Overview
Starting in version 8.x2, AllegroGraph introduced native vector storage and vector-generating features to enhance graph integration with Large Language Models (LLMs) for Retrieval Augmented Generation (RAG). These vector features augment AllegroGraph's Graph, Document, and Symbolic AI solutions for building Neuro-symbolic AI systems. By leveraging vector storage, AllegroGraph enables efficient management, retrieval, and analysis of large-scale vector data, fostering more sophisticated and intelligent data interactions.
What is Vector Storage?
Vector storage in AllegroGraph refers to the native ability to generate, store, manage, and retrieve data in vector format. Vectors, typically arrays of numerical values, represent data from a Knowledge Graph, Document, and/or LLM. This vector representation in AllegroGraph is particularly useful in scenarios for Graph Retrieval Augmented Generation (Graph RAG or RAG) or when data points need to be compared or analyzed based on their similarity or distance from one another.
There are a number of methods in AllegroGraph for generating, updating and storing vectors.
- Convert an existing Knowledge Graph (RDF repository) to vectors for use with ChatStream, see LLM Split.
- Store vectors received from an LLM via a SPARQL Query,
- Load text, documents, triples, quads directly into vector form
- Combine Knowledge Graphs (RDF repositories) in a single vector store for federation and knowledge base management.
Note that like all databases in AllegroGraph, vector databases are ACID compliant. They are also secured as described in the Security Implementation document.
You need an API key to create and use a vector database
The keys shown in the examples below (and elsewhere in the AllegroGraph documentation) are not valid OpenAI API or serpAPI keys. They are used to illustrate where your valid key will go. See the LLM document for information on obtaing keys.
Creating a vector database
Once you have loaded text into a repository (named, say, my-repo), you create an associated vector repo from it by defining a .def files and then use the agtool llm index ... command to create the vector database. The .def file contains an LLM embed specification which tells AllegroGraph which object strings in the repository should be converted to numerical vectors. These vectors along with their original text and the corresponding subject URI are stored in a newly created vector database named my-repo-vec (using our repo name, but in general in REPO-NAME-vec).
See the LLM embed specification for full details. Here we give a couple of examples.
The historical figures example
(This example is repeated in several documents where different uses of of the resulting repos and vector repos are emphasized. The text is identical from here to the note below in every document where it is used.)
For this example, we first create a new repo historicalFigures. Here is the New WebView dialog creating the repo:
Next we have to associate our OpenAI key with the repo. Go to Repository | Repository Control | Query execution options (selecting Manage queries displays that choice as does simply typing "Query" into the search box after Repository control is displayed) and enter the label openaiApiKey and your key as the value, then click SAVE QUERY OPTIONS:

(The key in the picture is not valid.) You can also skip this and use this PREFIX with every query (using your valid key, of course):
PREFIX franzOption_openaiApiKey: <franz:sk-U01ABc2defGHIJKlmnOpQ3RstvVWxyZABcD4eFG5jiJKlmno> Now we create some data in the repo. Go to the Query tab (click Query in the Repository menu on the left). We run a simple query which uses LLM to add historical figures triples to out repository. Note we define the llm: prefix. (These set-up steps, associating the openaiApiKey with the repo and defining the llm: prefix are taken care of automatically in the llm-playground repos. Here we show what you need to do with a repo you create and name.)
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/>
INSERT {
?node rdfs:label ?name.
?node rdf:type <http://franz.com/HistoricalFigure>.
} WHERE {
(?name ?node) llm:response "List 50 Historical Figures".
} Triples are added but the query itself does not list them (so the query shows no results). View the triples to see what figures have been added. We got 96 (you may get a different number; each has a type and label so 48 figures, each using two triples). Here are a bunch:
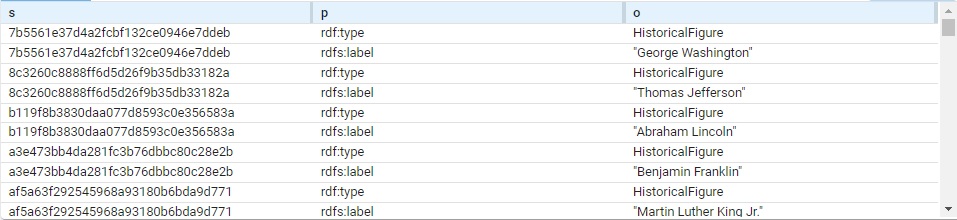
The subject of each triple is a system-created node name. (These are actual values, not blank nodes.) Each is of type HistoricalFigure and each has a label with the actual name.
This query will just list the names (the order is different from above):
# View triples
SELECT ?name WHERE
{ ?node rdf:type <http://franz.com/HistoricalFigure> .
?node rdfs:label ?name . }
name
"Aristotle"
"Plato"
"Socrates"
"Homer"
"Marco Polo"
"Confucius"
"Genghis Khan"
"Cleopatra"
...
(Note: this comes from a chat program external to Franz Inc. The choice and morality of the figures selected are beyond our control.)
Now we are going to use these triples to find associations among them. First we must create a vector database. We can do this in two ways, either with a New WebView dialog or with a call to agtool.
Creating the vector database using a New WebView dialog
Open the historicalFigures repo in New WebView (this feature is not supported in traditional WebView). Open the Repository control menu (in the Repository menu on the left and choose Create LLM Embedding.
That action displays this dialog:
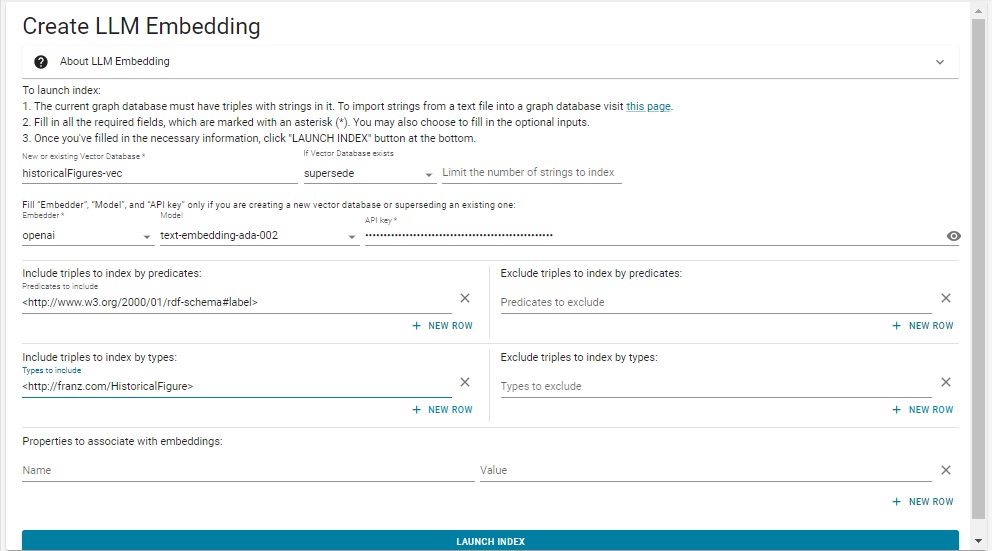
We have filled in the various fields using the same values as in the .def file above. Note we did not escape the # in rdf-schema#label. That is only required in lineparse files and will cause an error if done in the dialog.
Using agtool to create a vector database
We need to specify how the vector database should be created and we do this with a .def file. Create a file historicalFigures.def that looks like this (inserting your openaiApi key where indicated):
embed
embedder openai
if-exists supersede
api-key "sk-U43SYXXXXXXXXXXXXXmxlYbT3BlbkFJjyQVFiP5hAR7jlDLgsvn"
vector-database-name ":10035/historicalFigures-vec"
# The :10035 can be left out as it is the default.
# But you must specify the port number if it is not 10035.
if-exists supersede
limit 1000000
splitter list
include-predicates <http://www.w3.org/2000/01/rdf-schema\#label>
include-types <http://franz.com/HistoricalFigure> Note the # mark in the last line is escaped. The file in Lineparse format so a # is a comment character unless escaped. (We have a couple of comment lines which discuss the default port number.)
Pass this file to the agtool llm index command like this (filling in the username, password, host, and port number):
% agtool llm index --quiet http://USER:PW@HOST:PORT/repositories/historicalFigures historicalFigures.def Without the --quiet option this can produce a lot of output (remove --quiet to see it).
This creates a vector database repository historicalFigures-vec.
(End of example text identical wherever it is used.)
The Chomsky RAG example
RAG (Retrieval Augmented Generation) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
(This example is repeated in several documents where different uses of the resulting repos and vector repos are emphasized. The text is identical from here to the note below in every document where it is used.)
In this example, information contained in the chat is not added to the knowledge base. Adding chat information to the knowledge base is also supported. See LLM chatState Magic Predicate Details for a version of this example where that is done.
The AllegroGraph.cloud server has the chomsky and chomsky-vec repos already loaded and set up, allowing you to run the example here with much less initial work.
We start with a collection of triples with initial information. Create a repo name chomsky47. The data for this repo is in a file named chomsky47.nq. This is a large file with over a quarter of a million statements. Its size is about 47MB. Download it by clicking on this link: https://s3.amazonaws.com/franz.com/allegrograph/chomsky47.nq
Once downloaded, load chomsky47.nq into your new chomsky47 AllegroGraph repo.
Set the Query Option for the chomsky47 repo so the openaiApiKey is associated with the repo by going to Repository | Repository Control | Query execution options (type "Query" into the search box after Repository control is displayed) and enter the label openaiApiKey and your key as the value, then click SAVE QUERY OPTIONS (this same action was done before with another repo):
(The key in the picture is not valid.) You can also skip this and use this PREFIX with every query (using your valid key, of course):
PREFIX franzOption_openaiApiKey: <franz:sk-U01ABc2defGHIJKlmnOpQ3RstvVWxyZABcD4eFG5jiJKlmno> Create the file chomsky.def with the following contents, putting your your Openai API key where it says [put your valid AI API key here]
embed
embedder openai
api-key "[put your valid OpenAI API key here]"
vector-database-name "chomsky47-vec"
limit 1000000
splitter list
include-predicates <http://chomsky.com/hasContent> Once the file is ready, run this command supplying your username, password, host, port, and the chomsky.def file path. Note we use 2> redirection which, in bash or bash-comptible shells, causes the output goes to the /tmp/chout file -- there is a great deal of output. You can also add the option --quiet just after llm index to suppress output.
% agtool llm index USER:PASS@HOST:PORT/chomsky47 [LOCATION/]chomsky.def 2> /tmp/chout Try this query:
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/>
# When using the chomsky/chomsky-vec stores in AllegroGraph.cloud
# uncomment the following line with a valid openaiApiKey:
# PREFIX franzOption_openaiApiKey: <franz:sk-XXvalid key hereXX>
SELECT ?response ?citation ?score ?content {
# What is your name?
# Is racism a problem in America?
# Do you believe in a 'deep state'?
# What policy would you suggest to reduce inequality in America?
# Briefly explain what you mean by 'Universal Grammar'.
# What is the risk of accidental nuclear war?
# Are you a liberal or a conservative?
# Last time I voted, I was unhappy with both candidates. So I picked the lesser of two evils. Was I wrong to do so?
# How do I bake chocolate chip cookies? (Note: this query should return NO answer.)
bind("What is your name?" as ?query)
(?response ?score ?citation ?content) llm:askMyDocuments (?query "chomsky47-vec" 4 0.75).
# In AllegroGraph.cloud the vector store is named chomsky-vec. Modify
# the above line.
} This produces this response:
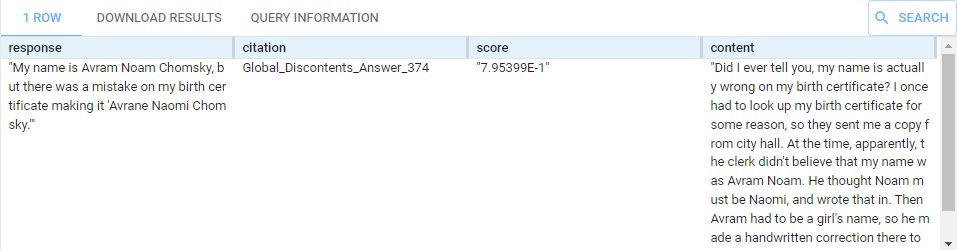
We have (commented out) other questions, about linguistics, politics, and himself (and about cookie recipes). Replace What is your name? with some of those. The content that supports the result is supplied, on multiple rows if it comes from various places (the summary is the same in each row, just the supporting content changes).
You can also use the natural language interface, as described in the ChatStream - Natural Language Querying document. Choose ChatStream - Natural Language from the NEW QUERY menu on the Query tab:
and enter any question (such as ones commented out in the query above) directly.
(End of example text identical wherever it is used.)
Other LLM Examples
See LLM Examples. The LLM Split Specification document also contains some examples. The LLM Embed Specification has some vector database examples.