Introduction
See the document Large Language Models (LLM) and Vector Databases for general information about Large Language Model support in AllegroGraph. In this document we discuss embeddings and creating vector databases.
An embedding is a vector representation of natural language text. A vector database is a table of embeddings and the associated original text. An Allegrograph Vector Database associates embeddings with literals found in the triple objects of a graph database. This Vector Database also stores the subject and predicate of each triple whose object was embedded. This permits a mapping from literals to subject URIs in support of nearest-neighbor matching between an input string and the embedded object literals as shown in the example below.
We assume in this document that you have defined the llm namespace this way:
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/> See Namespaces and query options for information on namespaces.
In Allegrograph the magic predicates llm:nearestNeighbor and llm:askMyDocuments utilize the vector database. A query clause of the form
(?uri ?score ?originalText) llm:nearestNeighbor (?text ?vector-database ?topN ?minScore) binds the subject ?uri of the ?topN best matching items in the vector database named by the literal bound to ?vector-database, where the minimum matching score is above a float bound to ?minScore. The llm:nearestNeighbor predicate also binds the matching score ?score and the source text ?originalText.
The predicate llm:askMyDocuments implements the process of Retrieval Augmented Generation. The predicate first retrieves the nearest-neighbor matching document fragments from the vector database, then forms a larger LLM prompt that combines this background content with the original query.
(?response ?citation ?score) llm:askMyDocuments (?query ?vector-database ?topN ?minScore) binds the ?response to the LLM's response to a big prompt that combines the ?query with the text content from the ?vectorRepoSpec based on the ?topN nearest neighbor matches above ?minScore. What's more, it binds ?citation to the subject URI of each matching document that contributes the response enabling the predicate to explain its response.
Creating a vector database
An embedding is a numeric representation of the meaning of a text fragment. The numeric representation is a vector of numbers, the length of the vector being dependent on the program computing the embedding. An embedding is different than a simple hash of the text fragment which is only dependent on the characters in the string and their positions. An embedding is based on the meaning of the string and thus is much more difficult to compute.
A vector store stores these embeddings as well as the original text fragment from which the embeddings were computed. The main use of a vector database is this: given a new text fragment you compute its embedding and then compare that to embeddings in the vector store to find the ones are similar. You have then found other text strings with similar meaning to the new text fragment you're testing. Thus you've done a semantic search to find similar text and not a simple text search to find similar text strings.
Text is typically split first. Splitting means breaking the text up into smaller and more manageable chunks. These chunks, called windows, should be large enough to contain meaningful knowledge but small enough to fit under the token limits of the embedding model. See the LLM Split specification document for information on splitting a text file.
Embedding can be specified and executed in two ways: using the Create LLM Embedding dialog in New WebView or using agtool llm index command. We describe both methods here, the New WebView first and then the agtool method.
Using the dialog in New WebView to create a vector database
This method must be used when using AllegroGraph.cloud as that tool does not provide access to agtool. The LLM Embedder dialog is also described, in somewhat more detail, in the New WebView document.
Here we show how to use the New WebView dialog using the historicalFigures repo as described in the historical figures example. if you have not already done so, create that repo.
Then open the historicalFigures repo in New WebView (note this feature is not supported in traditional WebView). Open the Repository control menu (in the Repository menu on the left and choose Create LLM Embedding.
That action displays this dialog:
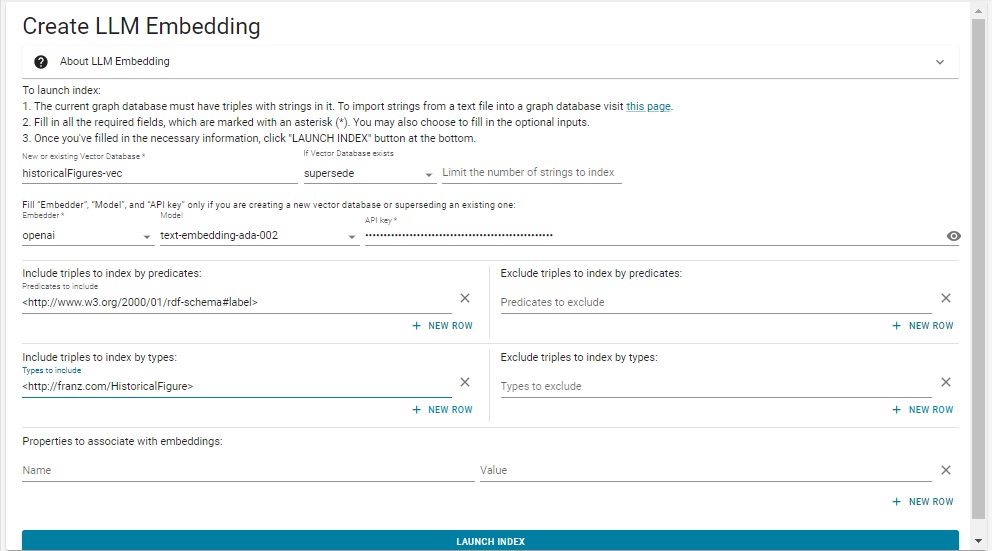
We have filled in the various fields using the same values as in the .def file we describe below. Note we did not escape the # in rdf-schema#label. That is only required in lineparse files and will cause an error if done in the dialog. The vector database associated with the embedding will be created when you click the Launch Index button. The historicalFigures example is quite small so this should not take long, but a much larger text database may take quite a while to be built.
Using agtool to create a vector database
You must give instructions so the system knows how to create a vector database. The instructions are called an LLM embed specification.
When using agtool, the LLM embed specification is a file in lineparse form that tells AllegroGraph which object strings in a repository should be converted to numerical vectors and stored in the vector database. The embedder stores that vector along with the original text and the corresponding subject URI in a vector database associated with the repo.
See the document Large Language Models for details and the document Lineparse Format for a general description of lineparse files.
A file containing the embed specification is the last argument to agtool here:
agtool llm index reponame specification-file In order to index strings the Large Language Model (LLM) embedder contacts an LLM API to process each text item and return a large vector of numbers (for example: a vector of 1536 element for OpenAI embeddings). The lineparse formatted specification file determines which text strings are sent to the LLM server.
Lineparse Items in specification file
Min and Max in the table below refer to the number of arguments to the named item. The various items in the table also appear in the New WebView dialog described above, where the values are directly input.
| item | min | max | required |
|---|---|---|---|
| embedder | 0 | 1 | no |
| model | 0 | 1 | no |
| api-key | 0 | 1 | no |
| vector-database-name | 1 | 1 | yes |
| if-exists | 0 | 1 | no |
| splitter | 0 | 1 | no |
| include-predicates | 0 | no max | no |
| exclude-predicates | 0 | no max | no |
| include-types | 0 | no max | no |
| exclude-types | 0 | no max | no |
| limit | 0 | 1 | no |
| property | 0 | no max | no |
The embedder is the service that will convert a text string to a vector of floats. The default is "demo" which will create an embedding quickly and at no cost but there is no meaning to the embedding and an api-key is not required. The embedder "openai" computes a useful embedding vector but it slower and typically not free to use.
The model is used to distinguish between different ways that an embedder can create an embedding. If not specified the default for that embedder will be chosen. For example for the embedder openai the default model is text-embedding-ada-002.
The api-key is the appropriate api key for the embedder chosen, if such a api key is required. An OpenAI api key must be obtained from openai.com. (Keys shown in examples in the AllegroGraph documentation are not valid.)
You must specify the vector-database-name. It can be any repo specification but is typically just the name of a repo. If it specifies an existing repo, it must be a vector database repo (as created by a previous call to agtool llm embed or directly by agtool repos ensure-vector-store.
If specified vector database does not exist then it will be created. In that case you must have specified the embedder and possibly the model and api-key so those can be put in the newly created vector store.
If the specified vector-database-name already exists then the value of if-exists is consulted. if-exists can be "open" (the default) meaning open and add data to the existing vector store. If if-exists is "supersede" then the vector database will be re-created in which case the values of embedder and possibly model and `api-key' are used.
If vector-database-name is "*" (a single asterisk) then this means use the vector database inside the repo containing the strings to be indexed. If there is no vector database inside the repo containing the strings to be indexed then a vector database will be created.
Currently only one splitter is defined (list) so that line should be omitted or the value should be list. We recommend that this line be omitted since we are developing alternative ways to specify the splitting of text. This directive may go away in the future.
The strings that are processed are those found in the object position of a triple.
The embedder selects object literals for embedding. When include predicates is specified, the embedder creates vectors only for objects in triples with the included predicates. When exclude-predicates is specified, the embedder will omit processing objects in triples with those predicates.
You have the option to specify both include-predicates and exclude-predicates, only one, or neither. If the same predicate is listed in include-predicates and in exclude-predicates then the exclude-predicates takes precedence. However there's no reason for specifying both exclude-predicates and include-predicates.
The point of exclude-predicates is that you may want to include all predicates in the emedding selection, except for a short list of predicates you want to exclude. However all predicates are not considered if you have an include-predicates item as well.
You can specify more than one predicate either on the same line or different lines.
For example to include three predicates you can write it:
include-predicates <http://sample.com/pred-a> <http://sample.com/count\#234>
include-predicates <http://sample.com/pred-c> Note that because in the Lineparse format the hash character (#) starts a comment, if a URL contains a hash character one must precede the hash character with a backslash in order to turn the hash character into a normal character that doesn't start a comment. The example above demonstrates that. Hash characters should not be escaped in entries in the New WebView dialog.
If you specify either include-types or exclude-types then that further refines the search for text to process. In that case only triple of the form
subject predicate text-object are considered if there is also a triple
subject rdf:type type where type is one of the included-types if there are any included types and type is not one of the excluded-types if there are any excluded types.
Also the predicate must obey the included-predicates and excluded-predicates if any are specified.
The property item allows you to specify a predicate and object to be associated with each object embedded. The property item can be repeated and always has two arguments
property name value This adds a triple with predicate <http://franz.com/prop/name> and the given value as object. The value should be a literal or resource in ntriple format. Thus for a resource you would write <http://foo.com/bar> and for literal "\"a literal value\"". Anything that's not in ntriple syntax is considered a literal so a value of
"a literal value" would be considered the same literal as
"\"a literal value\""
For each item indexed, the vector database stores the embedding vector along with the subject URI, the predicate URI, the original text of the object literal and optionally the object type (when include-predicates or exclude-predicates is specified).
Here is a sample specification file (named historicalFigures.def, used in the example below):
embed
embedder openai
if-exists supersede
api-key "sk-U43SYXXXXXXXXXXXXXmxlYbT3BlbkFJjyQVFiP5hAR7jlDLgsvn"
vector-database-name "10035/historicalFigures-vec"
# The 10035 can be left out as it is the default.
# But you must specify the port number if it is not 10035.
if-exists supersede
limit 1000000
splitter list
include-predicates <http://www.w3.org/2000/01/rdf-schema\#label>
include-types <http://franz.com/HistoricalFigure> Note we escape the # in the line
include-predicates <http://www.w3.org/2000/01/rdf-schema\#label> since Lineparse Format uses # for starting a comment.
These values appear in the New WebViwe dialog above.
Practical Example
Suppose we have an Allegrograph running on localhost:10035 with repository called historicalFigures that contains information about people from the past. For each historical person, there is a unique URI subject and predicates rdfs:label and rdf:type. The historical figures have type <http://franz.com/HistoricalFigure>. See Embedding by creating a VectorStore where we create a vector database. This example is repeated in several documents. We repeat the instructions given above about user New WebView or agtool to create a vector database so the example is comlete everywhere it is used.
(This example is repeated in several documents where different uses of of the resulting repos and vector repos are emphasized. The text is identical from here to the note below in every document where it is used.)
For this example, we first create a new repo historicalFigures. Here is the New WebView dialog creating the repo:
Next we have to associate our OpenAI key with the repo. Go to Repository | Repository Control | Query execution options (selecting Manage queries displays that choice as does simply typing "Query" into the search box after Repository control is displayed) and enter the label openaiApiKey and your key as the value, then click SAVE QUERY OPTIONS:

(The key in the picture is not valid.) You can also skip this and use this PREFIX with every query (using your valid key, of course):
PREFIX franzOption_openaiApiKey: <franz:sk-U01ABc2defGHIJKlmnOpQ3RstvVWxyZABcD4eFG5jiJKlmno> Now we create some data in the repo. Go to the Query tab (click Query in the Repository menu on the left). We run a simple query which uses LLM to add historical figures triples to out repository. Note we define the llm: prefix. (These set-up steps, associating the openaiApiKey with the repo and defining the llm: prefix are taken care of automatically in the llm-playground repos. Here we show what you need to do with a repo you create and name.)
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/>
INSERT {
?node rdfs:label ?name.
?node rdf:type <http://franz.com/HistoricalFigure>.
} WHERE {
(?name ?node) llm:response "List 50 Historical Figures".
} Triples are added but the query itself does not list them (so the query shows no results). View the triples to see what figures have been added. We got 96 (you may get a different number; each has a type and label so 48 figures, each using two triples). Here are a bunch:
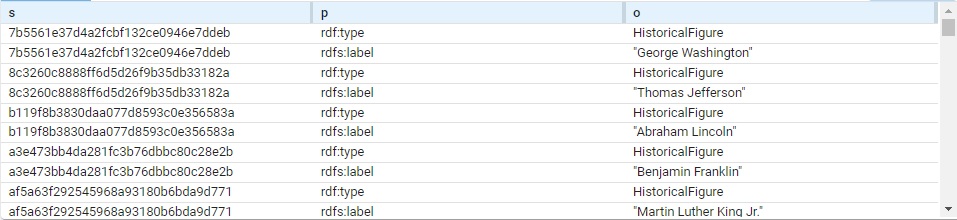
The subject of each triple is a system-created node name. (These are actual values, not blank nodes.) Each is of type HistoricalFigure and each has a label with the actual name.
This query will just list the names (the order is different from above):
# View triples
SELECT ?name WHERE
{ ?node rdf:type <http://franz.com/HistoricalFigure> .
?node rdfs:label ?name . }
name
"Aristotle"
"Plato"
"Socrates"
"Homer"
"Marco Polo"
"Confucius"
"Genghis Khan"
"Cleopatra"
...
(Note: this comes from a chat program external to Franz Inc. The choice and morality of the figures selected are beyond our control.)
Now we are going to use these triples to find associations among them. First we must create a vector database. We can do this in two ways, either with a New WebView dialog or with a call to agtool.
Creating the vector database using a New WebView dialog
Open the historicalFigures repo in New WebView (this feature is not supported in traditional WebView). Open the Repository control menu (in the Repository menu on the left and choose Create LLM Embedding.
That action displays this dialog:
We have filled in the various fields using the same values as in the .def file above. Note we did not escape the # in rdf-schema#label. That is only required in lineparse files and will cause an error if done in the dialog.
Using agtool to create a vector database
We need to specify how the vector database should be created and we do this with a .def file. Create a file historicalFigures.def that looks like this (inserting your openaiApi key where indicated):
embed
embedder openai
if-exists supersede
api-key "sk-U43SYXXXXXXXXXXXXXmxlYbT3BlbkFJjyQVFiP5hAR7jlDLgsvn"
vector-database-name ":10035/historicalFigures-vec"
# The :10035 can be left out as it is the default.
# But you must specify the port number if it is not 10035.
if-exists supersede
limit 1000000
splitter list
include-predicates <http://www.w3.org/2000/01/rdf-schema\#label>
include-types <http://franz.com/HistoricalFigure> Note the # mark in the last line is escaped. The file in Lineparse format so a # is a comment character unless escaped. (We have a couple of comment lines which discuss the default port number.)
Pass this file to the agtool llm index command like this (filling in the username, password, host, and port number):
% agtool llm index --quiet http://USER:PW@HOST:PORT/repositories/historicalFigures historicalFigures.def Without the --quiet option this can produce a lot of output (remove --quiet to see it).
This creates a vector database repository historicalFigures-vec.
(End of example text identical wherever it is used.)