Introduction
AllegroGraph Replication is a real-time transactionally consistent data replication and data synchronization solution. It allows businesses to move and synchronize their semantic data across the enterprise. This facilitates real-time reporting, load balancing, disaster recovery, and high availability configurations.
It assists organizations in mission critical challenges, such as managing liability or fraud, eliminating the risk of distributed enterprise scale environments, and reducing the costs.
AllegroGraph Replication is extremely reliable and best represents its capabilities in the most catastrophic situations. Current uses include keeping semantic data moving between North Sea Oil partners and managing the student success at the largest post-secondary educational institution in the US.
Why replication is useful
Organizations face more challenging technology landscapes than they did in the past. With the need to add semantic stores in a Big Data environment, they cannot afford to put this new and valuable data at risk.
Additionally, the need to use and distribute semantically sourced data throughout the organization is growing exponentially, even though budgets have been held flat or even declined in recent years.
Data thus must be protected and recoverable in case of system failures. Unexpected downtime must be minimized or eliminated.
AllegroGraph Replication is an enterprise class product that offers real-time replication and access to the semantic data, regardless of the quantity or location of the data. Replication can protect against data loss and can be a cost effective way to meet the challenges of maintaining data and access.
How AllegroGraph replication works
There are many ways to migrate, synchronize and move data. Each method comes with its own benefits and challenges. As the value of data increases, the cost of failure increases. As the volume of data increases, the difficulty of preventing data loss also increases.
One possibility is to synchronously write changes across a cluster of database replicas, but this broadly degrades performance and specifically reduces performance of transaction inserts into the system.
Another possibility is to use a combination of stored procedures and triggers. While this can be a satisfactory solution for smaller systems, it becomes difficult to maintain and increasingly challenging as the installation grows.
Some simply choose a design or architecture which does not scale well, making it impossible for the replicas to keep up with the primary in a heavily loaded replication cluster.
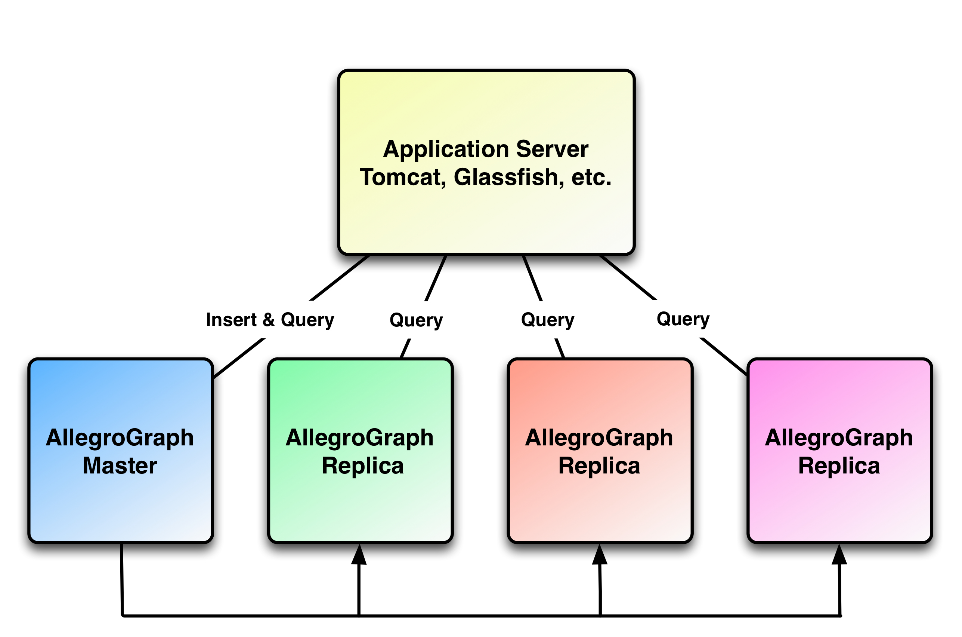
The AllegroGraph Replication architecture is designed to minimize the cost to the running primary system. It won't slow down inserts or queries against a running primary system. The latency between the Primary and Replicas is minimized. All replicas are transactionally consistent versions of the primary.
As an ACID compliant transactional semantic database, AllegroGraph maintains its own transaction log files. When AllegroGraph Replication is configured and enabled, the replication functionality determines where and for how long transaction logs are maintained in the system. This provides the ability for the database administrator to flexibly configure the system for load balancing, high availability or a combination of both.
In normal operation, the primary database reads transaction log records from its own transaction log and sends them to each of the replicas database servers. The process is extremely low cost and provides data movement between the primary and multiple secondaries with very low latency.
Unlike other methods of replication, this approach does not require that the load or architecture of any individual server be the same. Each replica processes transactions from the primary as quickly as it can and each at its own pace. This guarantees minimum latency for each individual replica and guarantees that each replica is a transactionally consistent version of the primary database at some previous point in time.
Common uses for replication
Replication of semantic databases in a new Big Data world addresses the need to manage the requirements of high availability, disaster recovery, real-time reporting, distributed query load, and transactional data synchronization. AllegroGraph Replication is more than up to these tasks and provides the performance to handle the use cases of the modern enterprise.
High availability/disaster recovery
Every enterprise has the mission critical need to provide data as continuously as possible. Yet disaster can threaten or stop ongoing and continuous operations. It is imperative, when the unforeseen does happen, that data is promptly recovered and put back into production use.
AllegroGraph Replication addresses high availability of semantic data in three areas:
- Managing planned downtime
- Protecting semantic data during unplanned downtime
- Providing disaster recovery
Without a proper system in place, database failure can cause:
- Lost revenue
- Damaged reputation
- Relationship issues with partners and customers
- Supply chain problems
- Legal liability
- Decisions on how to store data come under question
AllegroGraph Replication ensures not only that semantic enterprise data is never lost during downtime, but also that the data is always readily available. With AllegroGraph Replication, a standby database is always available, preventing data loss.
Real time reporting
Modern organizations have a common need to provide tools for creating, modifying and viewing Big Data, and to make these tools work with a large customer base. This requires real-time dashboards and reporting. All too frequently, this need has only been provided at the expense of application performance. The arrival of Big Data and its challenges have just made the problem more prone to negative side effect and additional costs. The exception for semantic data is when AllegroGraph Replication is used.
As part of an overall reporting solution for your enterprise Big Data semantic replication solution, AllegroGraph Replication:
- Minimizes the impact of reporting on the primary database by generating a transactionally consistent version for reporting.
- Enables query load balancing across a set of AllegroGraph database servers.
- Reduces information latency for queries and reporting.
- Optimizes batch reporting for the available window.
Data distribution and migration
As IT and Web infrastructures struggle to grow and manage Big Data complexities, there is a greater need for semantic data to be synchronized, integrated, consolidated and migrated to where it is needed. AllegroGraph Replication enables distribution of information within and across such environments by replicating data to and from different dedicated system and semantic data sources while maintaining full transactional integrity.
AllegroGraph Replication:
- Delivers data quickly and efficiently across the organization or web.
- Allows synchronization of data across multiple geographies.
Replication configuration
The following provides the detailed steps for deploying two different types of AllegroGraph Replication clusters. The first is a single primary/replica pair; the second, a single primary with multiple replica instances.
Useful references
The following documents will be referred to in this discussion:
- Server Installation: this is the Allegrograph installation documentation
- Server Configuration and Control: this document describes how to add a catalog to the configuration file
- Transaction Log Archiving: this document describes important configuration options relating to transaction logging
Single primary/replica pair
- Install and Setup agraph.cfg for Primary
- Create and Backup repository on Primary
- Install and Setup agraph.cfg for Replica
- Transfer and Restore Primary Backup to Replica
- Start Replication job on Replica.
Single primary with multiple replica instances
Same as above, but for each additional Replica instance, repeat steps 3 through 5.
Step 1. Install and setup AGRAPH.CFG for primary
Please refer to Server Installation for the steps necessary to download and install AllegroGraph for either the TAR.GZ or RPM method of installation.
Once installation is complete and the initial configuration file has been created (as described in the installation document), you must set up a catalog to hold your replicated repositories, as described in Server Configuration and Control and Transaction Log Archiving. Add a new Catalog Definition to your Primary's configuration file to setup Transaction log retention/archiving policies.
<catalog Replicants>
Main /path/to/main
TransactionLogRetain replication
# TransactionLogReplicationJobName *
# TransactionLogArchive /path/to/tlog/archive
</catalog> The last two catalog directives are commented out, but can be included if you want to only retain the Transaction Logs for specific replication jobs, or want unneeded Transaction Logs to be archived instead of deleted.
Once the catalog definition is added, you should start/restart your Primary server. The catalog you defined should now be available for use.
Step 2. Create and backup repository on primary
Create a repository in the Catalog you defined above, using your preferred method to do so. If you already have a repository containing statements that you now want to replicate, that is fine as well. In the step above, you would have added the catalog directives to the same catalog that holds this repository.
Now create a backup of this repository. This step is the same if the repository is empty or has contents. On the Primary Host, run the following command. The server needs to be up and running:
agraph-backup --port <primary-port> backup <repository-name> <repository-dir> <repository-dir> should be the path of a directory that does not exist or that is empty. The directory will be created (if necessary) and a backup of the repository named by <repository-name> will be written to a (newly-created) subdirectory. That backup will be used later when setting up the Replica instance.
Step 3. Install and setup AGRAPH.CFG for replica(s)
See the section Step 1. Perform the same steps for replicas as specified there for the primary. A catalog definition with replication directives is needed here as well. Note that a TransactionLogRetain directive value of replication behaves differently when the server is operating as a Primary or as a Replica, on a repository-by-repository basis. (The primary will keep tlogs so that all replicas can recover. The replicas keep tlogs just sufficient for themselves to recover.)
Step 4. Transfer and restore primary backup to replica(s)
On your Replica host, copy the backup file you created in Step 2. The AG Server needs to be up and running. In preparation for setting up replication, it is necessary to restore the backup of the primary to this AG instance. However, this must be done in a particular way. The full details of why this is necessary can be found in Replication Details. Here we give a brief description.
agraph-backup --port <replica-port> --replica restore <repository-name> <repository-dir> <repository-name> and <repository-dir> are as specified in step 2. The --replica argument takes care of the replication details for you. First, that the repository being restored must keep the same UUID as the repository from which it is backed up. Second, that this repository will be placed immediately into no-commit mode after the restore, so that no changes to the repository can be made that would prevent replication from starting when you issue the final command in this process.
Step 5. Start replication job on replica(s)
The last step is to tell the Replica to start a replication job. You issue this instruction via agraph-replicate.
agraph-replicate --primary-host <primary-host> --primary-port <primary-port> --secondary-host <replica-host> --secondary-port <replica-port> --user <superuser> --password <passwd> --name <replica-repository-name> --jobname repltest Making a replica into a primary
Suppose your primary fails. And by failure here, we mean totally fails, such as might happen when a meteor falls to earth and destroys the machine running the primary and all its associated disks. But the replica is still running, luckily on a machine in a different location unaffected by the meteor.
Here are the steps to turn the replica into the primary:
- Turn off replication. The replica is likely in a state where it is waiting for the Primary to return. Run the following command to temporarily stop replication.
agraph-replicate --secondary-host <host> --secondary-port <port> --catalog <catalog> --name <replica-repository-name> --user <user> --password <password> --stop - While the above command stops replication, it does not allow the Replica to accept commits. The second step is to turn off no-commit mode. The command below uses a commonly available http client called curl to make the appropriate request to the Replica.
- You should now be able to add statements to the replica. The final step is to find and remove the following file:
curl -X DELETE -u <user>:<passwd> 'http://<replica-host>:<port>/catalogs/<catalog>/repositories/<name>/noCommit' rm <Catalog main>/<name>/restart-ws-client <Catalog main> is the path specified as Main directory of the catalog your repository is located. <name> is the name of the repository itself. If this file is not removed, the next time the Replica is restarted, it will attempt to resume replication with the Primary.
Note that even if the Primary is restored, if the Replica has added any new statements, resuming replication would likely be fatal or could corrupt the data in the repository.
Further replication details
See Replication Details for further information on replication functionality.