Introduction: About AllegroGraph Cloud
AllegroGraph Cloud (also called Hosted AllegroGraph) is a web-based platform that simplifies the process of setting up AllegroGraph servers, allowing you to do so with just a few clicks.
See https://allegrograph.cloud for more information and registration instructions.
Chomsky examples are preloaded in AllegroGraph.cloud
The Chomsky chatbot and the Chomsky chatbot with memory examples are for the most part already set up in AllegroGraph.cloud (the chomsky data is loaded in the chomsky repo and the chomsky-vec repo has been created), saving users the trouble of downloading large files and creating a vector store. In some other AllegroGraph documentation, the names of the Chomsky database are chomsky47 and chomsky47-vec. The data is the same regardless of what name is used.
Natural language to SPARQL queries
AllegroGraph supports translating a natural language query to a SPARQL query. This feature is described in the Natural Language SPARQL Queries document. That document uses the kennedy repository supplied with the AllegroGraph distribution and discussed in the AllegroGraph Quick Start document. This repository is not, however, preloaded in the AllegroGraph Cloud.
The olympics repository, which contains information about the Olympic Games, is preloaded and in this section we will show how to set that repo up for natural language queries and show a couple of examples. A feature of this tool is the query is converted to SPARQL allowing users to examine the SPARQL produced. The SPARQL can be used as a template for other similar queries.
To enable natural language querying you must first specify an embedder and create a vector database associated with the repo. This has already been done for the olympics repo using the OpenAI embedder. In order to use it, you must supply an OpenAI key. See OpenAI GPT.
This key can be supplied to AllegroGraph in AG WebView by navigating to the webview/welcome/ page (that is [server:port]/webview/welcome/). Doing so will cause this dialog to be displayed:
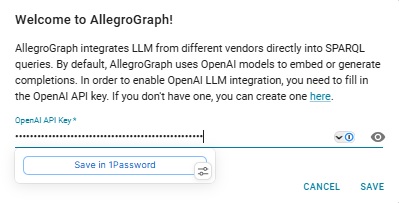
You fill in the OpenAI key (already done in the illustration) and click Save. The key will be used whenever it is required. (Actually users must have admin privileges to set the dialog value but the created Cloud user does have such privileges.)
(Note the webview/welcome page was introduced in version 8.3.1. In version 8.3.0, OpenAI keys were associated with individual vector repos rather than at once for all so the procedure described in the 8.3.0 version of this document was quite different from what is described here.)
Now in WebView, click on AllegroGraph on the left had side of the banner (upper part of the WebView page) and all loaded repos and associated vector repos will be displayed.
Open the olympics repo and click on Query from the Repository menu to the left. On that page click on the down arrow next to the New Query button and choose Natural Langauge (NL) to SPARQL.
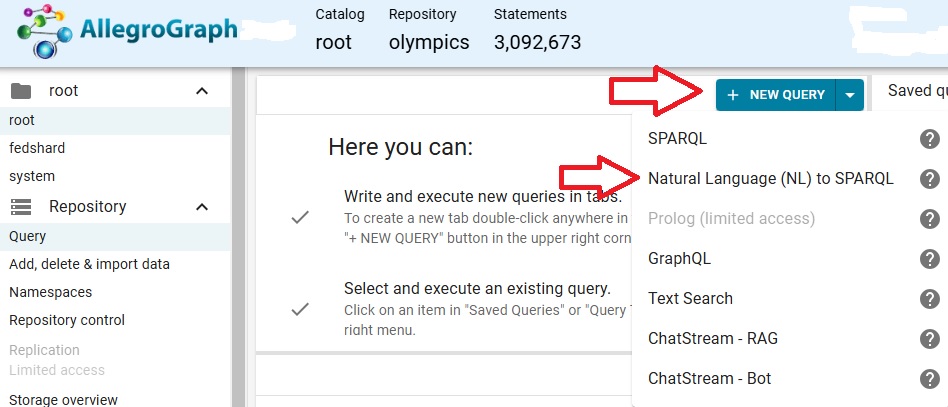
There is a box where you enter the query. It will be translated to SPARQL in the field below.
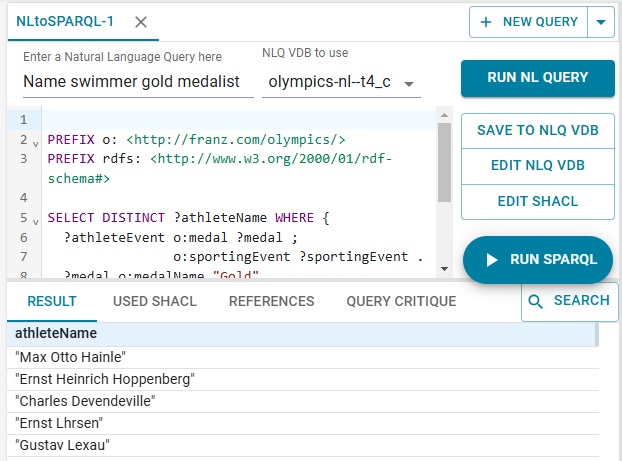
In our example, we ask Name swimmer gold medalist. Click the button RUN NL QUERY. The natural langauge query is translated to SPARQL. In our example, this is the translation:
PREFIX o: <http://franz.com/olympics/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?athleteName
WHERE {
?athleteEvent o:medal ?medal ;
o:sportingEvent ?sportingEvent .
?sportingEvent o:sportingEventName ?sportName .
FILTER (CONTAINS(?sportName, "Swimming"))
?medal o:medalName "Gold" .
?athlete o:athleteName ?athleteName ;
o:athleteEvent ?athleteEvent .
} Then the SPARQL query is executed and the results displayed, as shown in the illustration.
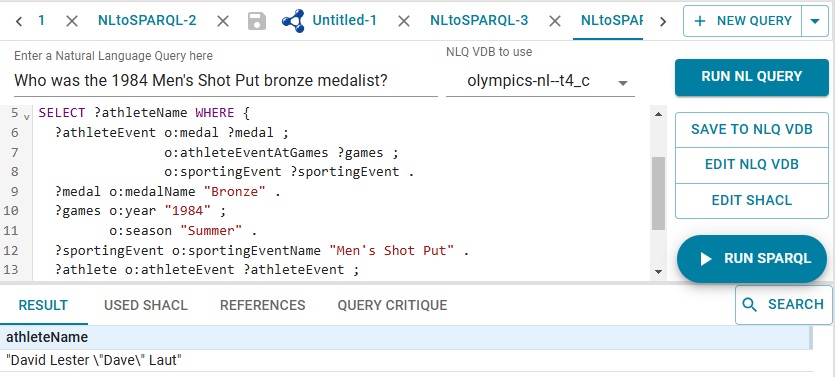
Out next query is What were the events in the 1984 games?, with this result:
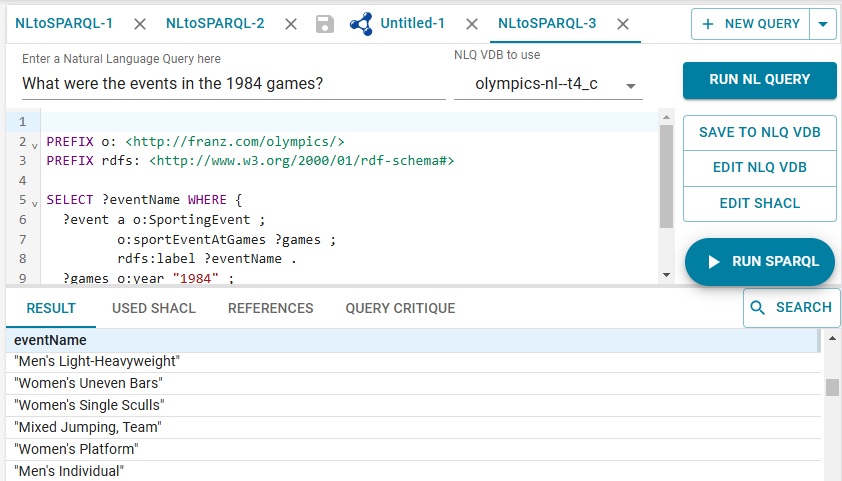
One of the events is Men's Shot Put. Who won the bronze? We ask:
GraphTalker and AllegroGraph Cloud
The GraphTalker service provides a chat-like interface for exploring AllegroGraph RDF repositories and other data sources using natural language. Most of the GraphTalker functionality is available in AllegroGraph Cloud instances. A GraphTalker interface can be launched from WebView's catalog page or from a repository page. In the first case the user will have to choose to repository to work with. In the second case, the repository will be pre-selected. In both cases, the user can switch to a different repository at any point in time.
GraphTalker requires Anthropic API key to operate. Since free AllegroGraph Cloud instances do not come with pre-configured Anthropic API keys, the users will be prompted to provide the key, which can be saved on the session, user, repository or server level.
The users of AllegroGraph Cloud instances do not have access to the underlying machines and their file system, so the GraphTalker tutorials functionality is available in a limited form: the users can ask GraphTalker to create new tutorials, but will not be able to edit the existing ones. This limitation will be lifted in the future via a dedicated tutorial editing interface.