Deleting duplicate triples introduction
Two triples within a store may be SPO-identical or SPOG-identical. Two different triples are SPO-identical if they have identical subject, predicate, and object. They are SPOG-identical if they also have identical graphs. All triples also have a unique triple id, which is determined by the system and not under user control. Distinct triples always have distinct triple ids even if they are SPO- or SPOG-identical.
SPO-identical and SPOG-identical triples are also called duplicate triples. The term duplicate triples refers to both SPO- and SPOG-identical triples and so is ambiguous.
It is uncommon to deliberately add duplicate triples into a store. It is usually the result of loading data files twice or loading different files which happen to contain some duplicate data. Uncoordinated hand entry by multiple persons also may result in loading duplicates. There also may be reasons to load duplicates, such as wanting to determine whether separate large data files contain duplicate data. This may be difficult to determine by other means, particularly if the files use different formats.
Unless duplicate suppression is enabled (see below), the AllegroGraph system neither detects nor prevents loading of duplicate triples. It is not an error for a store to contain duplicate triples.
But duplicate triples do use resources unnecessarily, can cause slowdown of query processing, and may cause misleading results, particularly for queries involving counts of triples with specific components.
AllegroGraph provides facilities for identifying and for deleting duplicate triples. These facilities are described in this document. We first describe what can be done to identify and delete duplicates in general, and then we describe each interface (webview, REST, etc.)
Visible triples
A user can be restricted from viewing certain triples (see Security Implementation). The triples that can be viewed by a user are visible to that user. When we talk about duplicates in this document, we always mean duplicates among the triples visible to the current user. It may be the store contains a single triple which is visible to the user and additional SPO-identical triples which are not visible, because the user is restricted from seeing triples with the graphs of the other SPO-identical triples. Triples can have attributes (see Triple Attributes) which restrict which triples can be seen by a user and duplicate triples can have different attributes.
Permission to delete duplicates
Even if duplicate triples are visible to a user, the user may not have permission to delete some or all of the duplicates (again, see Security Implementation). Any command to delete duplicates issued by the user will not delete duplicates the user does not have permission to delete.
Duplicates in federated stores
The functionality (described below) for listing and deleting duplicate triples is not supported in federated stores (see AllegroGraph Federation in the Introduction). You can list/delete duplicates in each individual store which makes up the federation, but not in the federated store itself.
Listing duplicate triples
AllegroGraph will generate a list of all SPO-identical or all SPOG-identical duplicates. We have a repository named duptest that contains (in simplified format) the following 5 triples:
PREFIX franz: <http://www.franz.com/>
franz:person1 rdf:type franz:person default-graph [2314]
franz:person1 rdf:type franz:person default-graph [4345]
franz:person1 rdf:type franz:person default-graph [4678]
franz:person1 rdf:type franz:person graph1 [3417]
franz:person1 rdf:type franz:person graph1 [2341] For each triple, we have shown the Subject, Predicate, Object, Graph, and a notional triple-id. Note that while the triple id of a triple can be accessed progammatically, users have no control over what id is assigned. We provide these made-up values just so we can talk about the triple ids in our example. Triple ids are positive integers.
All five triples are SPO-identical. The first three and the last two are also SPOG-identical but none of the first three is SPOG-identical to either of the last two.
We will now list duplicates (we show how to list duplicates programmatically below). If two triples are identical, the one with the higher id is the duplicate. Thus the list of SPO-identical duplicate triples will be
franz:person1 rdf:type franz:person default-graph [4345]
franz:person1 rdf:type franz:person default-graph [4678]
franz:person1 rdf:type franz:person graph1 [3417]
franz:person1 rdf:type franz:person graph1 [2341] The triple
franz:person1 rdf:type franz:person default-graph [2314] is the non-SPO-duplicate, with the same S, P, and O as the other four, but with the lowest id.
The list of SPOG-identical duplicate triples will be
franz:person1 rdf:type franz:person default-graph [4345]
franz:person1 rdf:type franz:person default-graph [4678]
franz:person1 rdf:type franz:person graph1 [3417] The two triples
franz:person1 rdf:type franz:person default-graph [2314]
franz:person1 rdf:type franz:person graph1 [2341] are the non-SPOG-duplicates since each has the lowest id among its SPOG fellows.
If you delete SPOG-identical triples, then two of the first three triples and one of the last two will be deleted, with these triples remaining:
franz:person1 rdf:type franz:person default-graph [2314]
franz:person1 rdf:type franz:person graph1 [2341] Those are the non-SPOG-duplicates listed just above. Similarly, if you delete SPO-identical triples, four of the five triples will be deleted, leaving:
franz:person1 rdf:type franz:person default-graph [2314] Getting a list of duplicates
Here are curl commands to get a list of duplicate triples using the REST/HTTP interface interface. They are applied to the duptest repo we discussed above. You do not see the triple id in any of this output.
First we look at SPO duplicates (we have broken lines for readability). The default graph is not displayed. The other graph (called graph1 above) is <http://franz.com/OFFICER>.
% curl -X GET --header "Accept: text/x-nquads" -u test:xyzzy \
"https://localhost:10650/repositories/duptest/statements/duplicates?mode=spo"
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person>
<http://franz.com/OFFICER> .
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person>
<http://franz.com/OFFICER> .
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person> .
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person> . Since we are looking at SPO-duplicates and all five triples are SPO-identical, we get four duplicates.
Here are the SPOG duplicates:
% curl -X GET --header "Accept: text/x-nquads" -u test:xyzzy \
"localhost:10650/repositories/duptest/statements/duplicates?mode=spog"
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person>
<http://franz.com/OFFICER> .
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person .
<http://www.franz.com/#person1>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.franz.com/#person> . Three duplicates, two with the default graph and one with the OFFICER graph.
The Lisp function for listing duplicates is get-duplicate-triples which returns a cursor containing the duplicates:
triple-store-user(15): (pprint
(get-triples-list
:cursor (get-duplicate-triples :mode :spog)))
(<person1 type person OFFICER> <person1 type person> <person1 type person>)
triple-store-user(16): (pprint
(get-triples-list
:cursor (get-duplicate-triples :mode :spo)))
(<person1 type person OFFICER>
<person1 type person OFFICER>
<person1 type person>
<person1 type person>)
triple-store-user(17): In the Python interface, use RepositoryConnection.getDuplicateStatements.
In the Java interface, see getDuplicateStatements().
Suppressing duplicate triples at commit time
You can arrange that duplicate triples be suppressed at commit time. When a commit happens, there is a list of new triples to be added to the repo. If duplicate suppression is enabled, each of these triples is checked to see if it duplicates an already existing triple in which case it will not be added to the repo on this commit. The check for a duplicate is done against the committed triples and the set of triples from this commit that have already been found to not be duplicates.
This feature also provides a way of aggregating duplicate triple attributes. If attribute aggregation is enabled then the duplicate suppression procedure is more complex and that's explained in the document on attribute aggregation.
Purging deleted triples
When triples are deleted they are not immediately removed from indices because they must remain in all indices until all transactions which may potentially need to see those triples (such as transactions that started before the triples were deleted) have completed (been committed or rolled back). A triple that cannot possibly be accessed by any live transaction is referred to as an inaccessible triple. AllegroGraph provides a facility to purge inaccessible triples from indices. See Purging Deleted Triples for a complete discussion of deleted triple purging.
The Webview interface dealing with duplicate triples
Here we describe the WebView interface for managing duplicates. This section is repeated here in the WebView document.
To display the Managing Duplicates page in WebView, choose Manage Duplicates from the Repository Control menu when a repository is open.
That displays the following page:
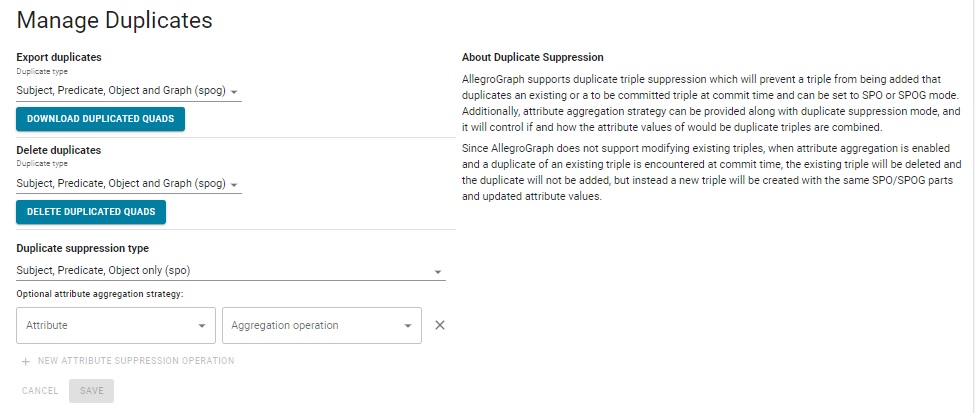
There are four fields on that page.
Export duplicates: Allows downloading a list of duplicate triples (when the drop down list is SPO as shown) or quads (when it is SPOG). The download process is triggered by this choice.
Delete duplicates: When chosen, duplicates (SPO or SPOG depending on what is specified in the drop down menu, SPO in the illustration) are deleted. If SPO duplicates are deleted, there is no control over the value of the graph on the remaining, undeleted triple. When triples are deleted, they are not actually removed, just marked as deleted. Over time, if many triples are deleted (because they are duplicates or just superseded by later data) they can waste significant space. See Purging Deleted Triples for information on cleaning up deleted duplicate and other deleted triples.
Supress duplicates by specifying the Duplicate supression type. The choices, as showing in the illustration, are Off, Subject, Predicate, Object and Graph (spog), and Subject, Predicate, Object only (spo). This specifies what is to be done to duplicates at commit time (not at load time unless commits are done simultaneously with the load). If the SPOG or SPO choices are selected and attribute aggregation (described next) is not enabled, no new duplicates will be committed but existing duplicate, if any will be unaffected. The subsiduary Optional attribute aggregation strategy (described next) affects adding duplicates and existing duplicates.
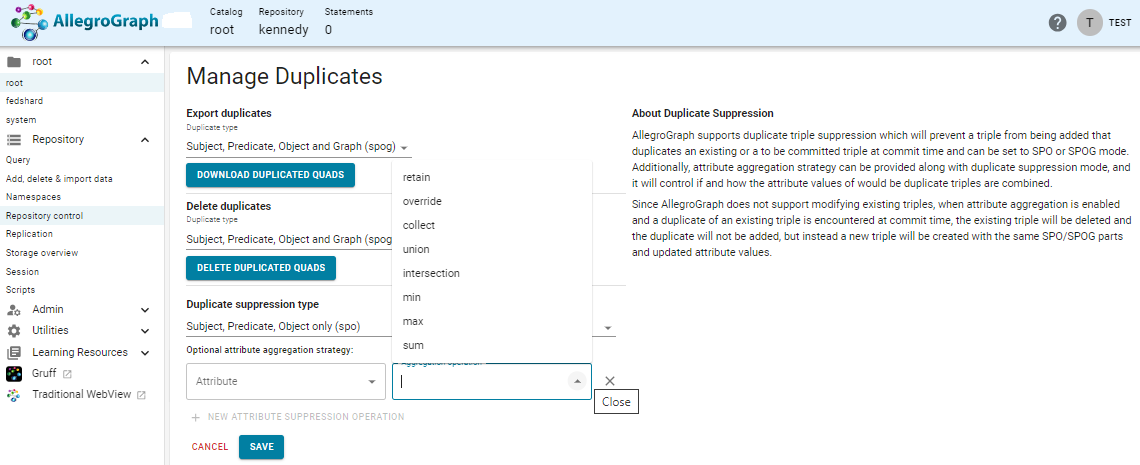
Optional attribute aggregation strategy: See the Aggregating attributes of duplicate triples section of the Triple Attributes document for information on attribute aggregation but in short, when you have two triples with the same SPO or SPOG (depending on which you consider to be duplicates) and both have attributes, instead of deleting one and keeping the other, you may wish to delete both (or not load one and delete the other) and create a new triple with different attributes constructed from combining in some fashion the attributes of the two triples.
Here is an example: Suppose you have a modified attribute with a single value (the date of the last modification) and a modified-history attribute (listing all modification dates). The current triple has attributes { "modified": "02212023", "modified-history": [ "02212023" ] }. Now you want to add an SPO identical triple with attribute { "modified": "08252024", "modified-history": [ "02212023" ] }. But you now want the attributes to be { "modified": "08252024", "modified-history": [ "02212023" "08252024" ] } (the date of the latest modification and the list of modification dates). You would specify the aggregation stratgy of the modified attribute to be override and that of the modified-history attribute to be collect. The new triple will be as desired (except the order of modified-history may be reversed). The various aggregation choices are displayed in the menu displayed when clicking on the Aggregation box.
REST interface to managing duplicates
The REST interface is described in the REST/HTTP interface document. The commands relating to duplicate triples start here in that document. In brief, you can get duplicate triples with
GET /repositories/[name]/statements/duplicates The mode argument can be spo or spog (the default).
You can delete them with
DELETE /repositories/[name]/statements/duplicates The mode argument can be spo or spog (the default).
You can get the duplicate suppression strategy with
GET /repositories/[name]/suppressDuplicates and set the duplicate suppression strategy with
PUT /repositories/[name]/suppressDuplicates The type argument can be false (no duplicate suppression at commit time), spo, or spog. Disabling automatic duplicate suppression at commit time can also be done with
DELETE /repositories/[name]/suppressDuplicates Java interface to deleting duplicates
The Java interface is described in the Javadocs. The relevant class is the AGRepositoryConnection class and the methods are getDuplicateStatements() (for getting duplicates), deleteDuplicates (for deleting).
Python interface to deleting duplicates
The relevant methods, both are in the RepositoryConnection class, are:
def getDuplicateStatements(mode)
def deleteDuplicateStatements(mode) Note you cannot enable supressing duplicates at commit time using the Python interface. See the Python API document.
Lisp interface to deleting duplicates
See Deleting triples. The function get-duplicate-triples returns a cursor of duplicates. The function delete-duplicate-triples delete duplicates. The function duplicate-suppression-strategy controls whether duplicates are deleted at commit time.