Introduction
Databricks is a company that provides a cloud-based platform to help enterprises build, scale, and govern data and AI, including generative AI and other machine learning models. Their data layer Delta Lake is an optimized storage layer that provides the foundation for tables in a lakehouse on Databricks. Delta Lake can be accessed via SQL statements and exported as CSV files. AllegroGraph seamlessly integrates with Databricks to give you the possibility to create and apply your extract, transform, load (ETL) pipeline to transfer data into your Knowledge Graph.
Setup
Prerequisite
- Make sure you have an Enterprise Databricks account (not Community Edition) and assigned host, for example, https://dbc-xxxxxxxx-09a9.cloud.databricks.com.
databricksCLI is available on the same machine where your AllegroGraph instance is running.
Connect Databricks and AllegroGraph
- You followed the instructions and have a valid Databricks config (~/.databrickscfg), for example:
[test-profile] host = https://dbc-xxxxxxxx-09a9.cloud.databricks.com client_id = XXX client_secret = YYY - You allowed access to a volume and a workspace folder for the service principal from (1) and set those values in the AllegroGraph configuration file:
/Workspace/<folder-with-read-write-access-for-the-principal>/import-sql-table.pyis a Python notebook created automatically by AllegroGraph on the first SQL table export./Volumes/workspace/default/<volume-with-read-write-access-for-the-principal>is a volume where exported SQL tables will be written.- You allowed access to at least one SQL warehouse for the service principal from (1).
Databricks export-table-notebook="/Workspace/<folder-with-read-write-access-for-the-principal>/import-sql-table.py", \
volume-to-store-sql-tables="/Volumes/workspace/default/<volume-with-read-write-access-for-the-principal>" where:
Usage
Importing data from Databricks is a two-step process:
- Databricks data is transformed into CSV file and downloaded to AllegroGraph side.
- You define the ETL pipeline to ingest data from the previous step using WebView or agtool.
Both of those steps are available in WebView on the Import CSV data from Databricks page. You can find the link to this page when you open a repository and click on the Add, delete & import data link in the right sidebar. The page provides a selection of several ways in which data from Databricks can be downloaded to AllegroGraph side:
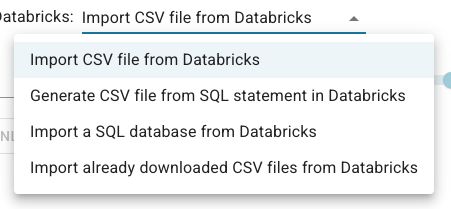
The explanation for each of the select items:
- "Import CSV file from Databricks" renders input for a file in DBSF, and the button to copy it to AllegroGraph side.
- "Generate CSV file from SQL statement in Databricks" provides a SQL editor to input a SQL statement, and the button to execute it, and download its output.
- "Import a SQL database from Databricks" renders the selection of accessible SQL tables with the button to export and download the picked one to AllegroGraph side.
- "Import already downloaded CSV files from Databricks" renders the selection of already copied CSV files from Databricks. On successful import, a CSV file or a folder with CSV files is removed automatically.
After acquiring a CSV file, users can define transformation rules to convert rows into triples. Please see CSV load in WebView section for more details on that.