Introduction
The AllegroGraph server is the running program which manages the various AllegroGraph repositories (also occasionally referred to as triple-stores or databases). The server must be set up as described in Server Installation.
This document describes server configuration below and server control further below.
All directives for AllegroGraph 9.0.0 are listed in this document. Most but not all can be used in earlier versions. The version in which the directive was added is shown for each case (versions prior to 7.0.0 are not specified exactly). If you are using a version earlier than 9.0.0 (but using this version of the documentation) the directives added after the version you are using cannot be used.
Argument notation
The directives that go in the configuration file generally require an argument. We generally show the type of argument expected. Here are some common argument types:
BOOLEAN: allowable values are
yesandno(and alsoy,t,true, or1foryesandn,nil,falseor0forno). Values are case-insensitive.PATHNAME: a pathname, usually to a directory and usually an absolute pathname.
FILE-PATHNAME: a pathname (usually absolute) of a file.
INTEGER: an integer indicating the number permitted (such as for
Backends) or a numeric label (such as forPort). Negative integers and 0 are not allowed unless the description says otherwise.TIME: a non-negative integer, which can be labeled with a units indicator. An unlabeled integer is interpreted as a number of seconds. Units indicators are 's', 'h', and 'd', meaning seconds, hours, and days. So 100 and 100s both mean one hundred seconds, 25h is twenty-five hours and 3d is three days.
REGEXP: a regular expression. Regular expression syntax is described here. Regular expressions can be specified to make case-insensitive matches.
VALUE: a value specified in the directive description.
Some directives (usually those identifying things) can be specified multiple times meaning any of the specified values can be used. The directive description will say whether it can be specified more than once. A few directives can have multiple values on one line, usually comma separated.
Directive values must not be quoted. Spaces are not allowed in directive values.
Server configuration
The AllegroGraph server requires a configuration file in order to start up. Usually, this file is specified using the --config command-line argument. A minimal file could look like this:
SettingsDirectory /tmp/ag4/settings
SuperUser test:xyzzy
<RootCatalog>
Main /tmp/ag4/root
</RootCatalog> An AllegroGraph configuration file consists of a set of top-level directives, and one or more catalog definitions. The syntax is straight-forward: directives (both top-level and within a catalog definition) consist of an alphanumeric word, whitespace, and then the value of the directive. Indentation is ignored and trailing whitespace is removed. A directive can span multiple lines. Catalog definitions are delimited by pseudo-XML markers like <RootCatalog>.
Each line of the configuration file is processed this way:
- Remove comment if present. A comment begins with
#anywhere on the line and extends to the end of the line. However the hash character can be escaped using a backslash as in\#in which case the\#is replaced by#and the hash character is considered part of the directive on the line. - Remove trailing whitespace (spaces and tabs).
- If the line now ends in a backslash character then process the next line using these steps and append it to the this line with the end of line backslash removed.
Some examples of using # and \:
# full line comment
24000-30000 # port range
one two \ # line will continue on next line
three four # comment on second line
this \# is a hash character # shows hash character which results in these three directives being processed by the configuration parser:
24000-30000
one two three four
this # is a hash character Each directive defining a parameter must be on its own single line (or multiple lines joined by backslashes as described above). Specifying more than one parameter on a single line will result in an error, or, possibly, in the first parameter being defined incorrectly and the remaining ones on the line not being defined at all.
The directories named in this file must either already exist and be writeable by the user running the server, or that user must be able to create them himself. You'll usually not want to use temporary paths as in the example, of course.
Note about SuperUser and AuthPolicy
For users of an external password utility like LDAP, the agraph.cfg directive
SuperUser test:xyzzy will create the test account and give it the internal password of xyzzy however that password can never be used if you specify AuthPolicy as external-token or token-external or external.
BaseDir directive
Any relative path in the config file is initially resolved with respect to the directory containing the config file. If you specify another directory using the BaseDir directive, all subsequent relative paths are resolved relative to that directory. BaseDir can be specified as often as you like and can itself be a relative pathname (which will be resolved with using the BaseDir value in use, or, if not previously specified, with respect to the directory containing the config file). If BaseDir is specified multiple times, relative pathnames in other directives are resolved with respect to the most recent BaseDir value.
BaseDirPATHNAME- A directory pathname which will be used to resolve relative pathnames in subsequent directives in the config file. Can be specified multiple times in the config file, with new values replacing older ones. See just above for more details. (Added in version 7.0.0 or before.)
Top-level directives
SettingsDirectoryPATHNAME- Required setting. Specifies the directory in which the server stores persistent information such as user accounts. (Added in version 7.0.0 or before.)
AccessLogEnabledBOOLEAN- A boolean (
yes/no) that can be used to enable logging of successful HTTP(S) requests to a dedicated log file. (Added in version 7.0.0 or before.) AccessLogDirPATHNAME- Directory in which the HTTP access log files are written. Default is
LogDir. (Added in version 7.0.0 or before.) AccessLogFilePatternVALUE- A file name pattern with
strftimestyle directives, to set up log rotation for the HTTP access log. The pattern may contain spaces. Default isaccess-%Y%m%d.logcontaining year, month and date. (Added in version 7.0.0 or before.) AccessLogEntryFormatVALUE- A log format pattern using Apache style directives. (Added in version 7.0.0 or before.) See Apache documentation for a list of possible directives, most of which are supported. The pattern may contain spaces. In case of invalid or unsupported directives a warning will be logged to
agraph.log. The logged value for unsupported directives (e.g.%l) is a dash:-. The default format is the NCSA extended/combined log format:%h - %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"
AllowHTTPBOOLEAN- A boolean (
yes/no) that can be used to turn off HTTP access to the server. Default isyes. (Added in version 7.0.0 or before.) Clients usually interact with the AllegroGraph server using either HTTP or HTTPS or both. This is true of Webview as well as Java and Python clients. The agtool program will use the direct lisp interface if possible otherwise it will use HTTP or HTTPS. For security reasons you may wish to disable HTTP access and only permit HTTPS access. In this case you specify 'no' for this switch and also specify an SSLPort (see the section Top-level directives for SSL client certificate authentication). However in order for the direct lisp interface clients (such as agtool) to connect to the server a very limited HTTP webserver is always running inside the server. This webserver serves only two URLs and returns public information available via ps and netstat. Thus it's not a security concern that HTTP is used.
AllowIPIP-ADDRESSES(Added in version 7.0.0 or before.) The value of the option must be a string containing one or more comma-separated IP address blocks in CIDR notation. The symbol
anycan be used instead of0.0.0.0/0notation.Patterns can be either accepting or denying (prefixed with
!) and are matched in the specified order, so less restrictive patterns must be included later in the list than denials which they include (see the second example, where127.13.0.0will be denied even though the list ends withany). Examples:# Accept only loopback connections: AllowIP 127.0.0.0/8, !any # Accept any IP addresses except 127.13.0.0/16 range, # unless it's 127.13.13.13: AllowIP 127.13.13.13, !127.13.0.0/16, any- If this option is non-empty, for every incoming connection, AllegroGraph extracts the IP address and attempts to match it against the given patterns in the specified order until the first successful match. If the matched pattern is accepting, the server handles the request, otherwise HTTP status code 403 is returned.
AuditingBOOLEAN- A boolean (
yes/no) that can be used to turn on auditing. Default isno. (Added in version 7.0.0 or before.)
AutocompleteTimeoutINTEGER- Specifies the timeout in seconds for SPARQL autocomplete searches. The default is 5 seconds. A negative value disables SPARQL autocomplete entirely, causing the autocomplete endpoint to always return an empty list. Setting the timeout to 0 means no timeout, allowing the autocomplete process to run until the specified number of options is gathered.
BackendsINTEGER- Specifies the maximum number of processes spawned to handle HTTP requests (note that session processes do not count toward this limit). Default is 10. (Added in version 7.0.0 or before.)
BackendMaxIdleINTEGER- Specifies the maximum number of seconds a backend can be idle before it is eligible for being killed to recover any resources it has aquired. The default is 600 seconds (10 minutes). (Added in version 7.4.0.)
BriefBacktraceTRUE-OR-FALSE- AllegroGraph errors cause the system to send a backtrace (a reverse ordered list of the function calls that resulted in the error, along with their arguments) to the log file. If this directive is
true(default isfalse), only the function names will be included in the backtrace and argument information will be suppressed. This will make debugging the error more difficult but sensitive data (such as passwords) which might have been passed as arguments will then not appear in the log. (Added in version 7.0.0 or before.)
StaleDNSEntryRetainTimeSECONDS- After a DNS entry has exceeded its specified lifetime AllegroGraph still may return it immediately to a query and at the same time it will try to update the value. This parameter specifies how long AllegroGraph will retain a stale value. If the DNS mapping from name to IP address may change while the application is running you'll want to specify a very small value (number of seconds). A zero value will cause the DNS record to be considered correct for only the lifetime specified in the DNS record itself. The default is 1800 (= 60x30 seconds or 30 minutes). (Added in version 7.0.0 or before.)
DisableGruffBOOLEAN- If true (the default is
false), Gruff cannot be invoked from AGWebView. See also the MaxGruffProcesses directive. (Added in version 7.0.0 or before.)
DisableGraphTalkerBOOLEAN- If true (the default is
false), GraphTalker cannot be launched on the AllegroGraph server. See also the MaxGraphTalkerProcesses directive. (Added in version 9.0.0.) EvalAllowedBOOLEAN- A switch to turn off Evaluate arbitrary code permissions globally. If it is
yes(the default), then the Evaluate arbitrary code permission bits are in effect. If it isno, then arbitrary code evaluation is disabled for all users (including superuser) regardless of the value of a user's actual permissions. (Added in version 7.0.0 or before.) HostNameHOST- Determines the host on which the HTTP server listens. Can be left out to have the server listen on all interfaces. Set to
localhostto listen only locally. (Added in version 7.0.0 or before.) HTTPProxyVALUE- This parameter can be used to make HTTP requests made by the server (for example, when a SPARQL query loads data from an external URL) go through a proxy. The VALUE syntax is [USER:PASSWORD@]HOST[:PORT], where the square brackets indicate optional portions. PORT defaults to 80. A USER and PASSWORD are necessary when the proxy requires authentication. (Added in version 7.0.0 or before.)
HTTPNoProxyVALUE- (Added in version 7.0.0 or before.) When proxying is enabled with the
HTTPProxydirective, this parameter can be used to list exceptions. HTTP requests made by the server to domains that match one of the suffixes specified with HTTPNoProxy are never proxied. HTTPNoProxy can be specified multiple times, for example:HTTPNoProxy mydomain.com HTTPNoProxy otherdomain.com With the above configuration, requests made by the server for
mydomain.com,otherdomain.com,sub.mydomain.comornotmydomain.comwill not be proxied.IP addresses can be specified and they are subject to the same string suffix matching rule as domain names are. Crucially, that means that a request made for a particular domain name will not match a rule that specified an IP address even if the domain name resolves to the IP address. It is usually the best to use entire IP addresses:
HTTPNoProxy 192.168.0.1- Requests to
localhostand127.0.0.1are never proxied.
HttpTraceFILE-PATHNAME- If the
HttpTracedirective is supplied, it is the name of the log file to which HTTP traffic is to be dumped. Relative pathnames are with respect to the log directory specified by the LogDir directive. If thisHttpTracedirective is specified andHttpTraceOptions(see just below) is not specified, tracing is done using the defaultHttpTraceOptions. See also the --http-trace-options command line argument. (Added in version 7.0.0 or before.)
HttpTraceOptionsOPTIONS- If the
HttpTracedirective is specified, tracing will be done with the information requested by this directive being written to the file specified byHttpTrace. The value of this directive should be a comma separated list of options. Options starting with the character + turn on the corresponding log category. Those starting with - turn them off (allowing you to enable a general category, like+alland disable specific items thus enabled, like-proxy).max-message-size=NUMBERcauses truncation of entries after NUMBER characters. The default value of this directive is+xmit,max-message-size=1000. The available log categories are listed in the Debugging section
of the AllegroServe documentation HTTPWorkersINTEGER- The number of initial HTTP workers to be started by the AllegroGraph server. The default is 50. The number should be larger than the number of backends (see
Backendsabove) plus anticipated frontend sessions (used, for example, by Webview). Too few workers may cause long-running requests (like opening a repository) to delay other concurrent requests. (Added in version 7.0.0 or before.) HTTPKeepAliveTimeoutINTEGER- The number of seconds for the HTTP keep alive timeout. The default is 10. (Added in version 7.0.0 or before.)
LicenseWarnInAdvanceNON-NEGATIVE-INTEGER- If NON-NEGATIVE-INTEGER is greater than 0, the server will issue a daily warning when the license will expire within that number of days. The warnings will continue until either the license is updated or the value of this directive is set to 0 (a server restart is required in either case). The default is 30. The value 0 means suppress the warning. (Added in version 7.0.0 or before.)
LogDirPATHNAME- Specifies the directory where the server log files are written. The primary log file is agraph.log, the secondary file is agraph-fallback.log. The secondary is only used when writing to the primary fails. The secondary file is preallocated to a size of 1MiB, so some log messages can be written even if the filesystem is full. On server startup or if writing to the primary becomes possible again, the contents of the secondary log file are automatically appended to the primary and the secondary log file is reinitialized. (Added in version 7.0.0 or before.)
MaxGruffProcessesPOSITIVE-INTEGER- Restricts the number of GRUFF processes to POSITIVE-INTEGER (default 8). This prevent users from opening too many GRUFF sessions. See also the DisableGruff directive. (Added in version 7.0.0 or before.)
MaxGraphTalkerProcessesPOSITIVE-INTEGER- Restricts the number of GraphTalker processes that can run simultaneously. This prevents users from opening too many GraphTalker sessions. See also the DisableGraphTalker directive. (Added in version 9.0.0.)
MemoryCheckWhenVALUE- A 'memory release specification'. It can be used multiple times. Each description must be in the form
name:valuewhere name can bequery,transactionortimeand value must be a number of items to run between checks (for query and transaction) or a delay in seconds (for time). (Added in version 7.0.0 or before.) MemoryReleaseThresholdINTEGER- A size specifying the threshold at which a memory release will occur. The size can be specified in gigabytes (e.g.
3g), megabytes (e.g.3000m), kilobytes (e.g.3000000k) or bytes (e.g.3000000000). (Added in version 7.0.0 or before.)
PidFileFILE-PATHNAME- A file to which the server writes out its process id. (Added in version 7.0.0 or before.)
PortINTEGER- If supplied, must be an integer. Used to set the port on which the daemon runs its HTTP server. When not given, Port defaults to
10035. If you do not want to allow access with HTTP, you must specify a value for SSLPort (see the section Top-level directives for SSL client certificate authentication) and also specify AllowHTTP tono. The value ofPortcan be overridden by the--portargument to agraph-control (and the--portargument to the agraph program). (Added in version 7.0.0 or before.)
QueryResultsLimitNUMBER- A user can be restricted to a maximum number of results to a query independently of a LIMIT clause in the query or other restriction. See Limiting results of a query in SPARQL Reference and Limiting the results a user can see in Managing Users. This directive specifies the limit, which applies to all user/repo limitations. The default value is 1000. (Added in version 7.2.0.)
QueryResultsCacheSizeNUMBER- If not 0, this specifies the maximum number of entries in the query results cache. If 0, query results caching is prohibited. See
allowCachingResultsquery option documentation for more details. The default value is 1000. (Added in version 8.0.0.)
QueryResultsCacheStorageSizeINTEGER- If non 0, this specifies the maximum on-disk size of query results cache. If 0, query results caching is prohibited. The value can be specified in gigabytes (e.g. 3g), megabytes (e.g. 3000m), kilobytes (e.g. 3000000k) or bytes (e.g. 3000000000). See
allowCachingResultsquery option documentation for more details. The default value is 1G. (Added in version 8.0.0.)
QueryOptionNAME=VALUE- (Added in version 7.0.0 or before.) A query option specification. It can be used multiple times. Each specification is equivalent to a query prefix option. The global configuration directive
QueryOption NAME=VALUE - is the same as the query prefix
PREFIX franzOption_NAME: <franz:VALUE> - but will be applied to all queries. See here in the SPARQL Reference for a list of SPARQL query options. An example is
QueryOption logQuery=yes - equivalent to this prefix added to each query
PREFIX franzOption_logQuery: <franz:yes> - Note there are a lot of query options and it would be redundant to list them all here when you can find them in the SPARQL Reference. But here are some more that are commonly used (keys and passwords shown are not valid; go to the SPARQL Reference for a complete description in all cases):
QueryOption openaiApiKey=sk-XXXXXXXXXXXIJKlmnOpQ3RstvVWxyZABcD4eFG5jiJKlmno QueryOption serpApiKey=XXXXXXXXXX4b15627d34b5859c76d17038d791c26e38f161e1234567e9 QueryOption profileQuery=time QueryOption profileQuery=space QueryOption chunkProcessingAllowed=yes
ReplicationPortsINTEGER-RANGE- (Added in version 7.0.0 or before.) If given, must be an integer range (e.g. 13000-13020). Replicas (single master -- see Replication and Warm Standby or multi-master -- see Multi-master Replication) require additional ports that are different from the Allegrograph HTTP/HTTPS ports. When using single-master replicas, the replication primary requires a separate listening port for each replica. When using multi-master replication, instances listen for TCP connections from other instances on these additional ports. In both cases, the operating system will choose an available port as needed when the replicas are set up if no value is given for this option, and that will always work. However, if there is a firewall between the replication primary and (any of) the replicas (single-master) or between instances (multi-master), the firewall administrator may need to configure the firewall to allow incoming connections from the replicas to the primary or among the replicas. That configuration process can be aided by limiting the range of ports which can be used, and that is what this parameter does. If a range is specified, only those ports will be used by replicas. For single-master, any replica which might become a primary should have this parameter also specified in its configuration exactly as it is for the primary. For multi-master, all servers should have this parameter identically specified in their configurations. Note that if no port in the range is available when setting up a replica, setting up the replica will fail. Therefore, the size of the range of ports should be at least the maximum expected number of replicas.
RunAsUSERNAME- Have the server, if started by root, run as the given user instead (defaults to
agraph). (Added in version 7.0.0 or before.)
SecureMMRBOOLEAN- If Multi-Master Replication is in use then internal network connections to this server over which transaction records are sent are encrypted with the SSL configuration given in this configuration file. If no SSL configuration is given then this parameter is ignored. This setting only applies to transaction records sent to this server. Transaction records from this server sent to other servers will be SSL only if the server to which the records are sent specifies has also enabled
SecureMMRin its configuration file.
SlowQueryLogThresholdNUMBER- (Added in version 7.0.0 or before.) If a SPARQL query takes longer than
NUMBERmilliseconds, log information about the query to the log file (or to the file named bySlowQueryLogFileif specified). An example whenSlowQueryLogThresholdis 1:Slow query (1.261700 msec): select ?s { ?s ?p ?o . } limit 100000 - The SPARQL query option
slowQueryLogThresholdwill set the threshold for a specific query. See Query Options in SPARQL Reference.
SlowQueryLogFilePATHNAME- Slow query log entries (see
SlowQueryLogThresholdjust above) will be written toPATHNAMErather than the regular log file if this option is specified. Relative pathnames are with respect to the log directory specified by the LogDir directive. (Added in version 7.0.0 or before.)
SMTPHostID SMTP-CONFIGURATION(Added in version 7.0.0 or before.) Defines a named SMTP configuration for use by AllegroGraph features that support email notification, such as auditing and the event scheduler. Multiple
SMTPHostdefinitions are allowed.ID is a name that is used with other configuration options to specify the SMTP host being defined. SMTP-CONFIGURATION associates with
IDa server, a login name and other information. For example, the following defines theSMTPHostwith IDgmail:SMTPHost gmail \ server="smtp.gmail.com", ssl=true, starttls=false,\ from="[email protected]", login="[email protected]", \ password="somepassword"- The following options are supported by
SMTPHost:server (string): the hostname or IP address of the server (example:
"smtp.gmail.com", or"127.0.0.1"). This is a required parameter.port (integer): defaults 25 for non-SSL, 465 for SSL (example:
port=993)ssl (boolean): defaults to false (example:
ssl=true)starttls (boolean): defaults to false (example:
starttls=true)from (string): the email address to which the
From:header of emails sent via this SMTPHost will be set. This is a required parameter.login (string): the user on the remote server (example:
login="[email protected]")password (string): the password corresponding to
login.password-command (string): a string suitable to be executed as a shell command. The specified command should output a single line containing the password to stdout. This is intended to avoid storing plaintext passwords in the configuration file.
SPARQLBaseURLURL- If given, the HTTP server will use this value as the base-url when parsing SPARQL queries. When not given, the URL of the request is used instead. (Added in version 7.0.0 or before.)
SuperUserNAME:PASSWORD- If given, must be a string in
name:passwordformat. The server will ensure, on startup, that a superuser with this name and password exists. Note that this means anyone that can read your configuration file has full access to the server. It is recommended to use the server setup script to create a superuser instead, or if you do use this directive, remove it after the first run of the server has created the user. (Added in version 7.0.0 or before.) -
TempDirPATHNAME - Specifies the directory in which AllegroGraph may create temporary files. Defaults to the system's designated temporary directory (typically
/tmp). (Added in version 7.0.0 or before.)
TransactionSemanticsVALUE- Either
sesame-2.6(the default) orsesame-2.7. It controls whether a new transaction is started automatically or an explicit begin is necessary. See Transaction handling semantics for more information. (Added in version 7.0.0 or before.)
UseLicensedCoresBOOLEAN- (Added in version 7.0.2.) If your AllegroGraph license restricts the number of cores that may be used by AllegroGraph, specifying this directive
true(default isfalse) ensures that no more than that number of cores will be used. If on startup you get an error message saying like the following:Starting server failed: The machine has more cores (4) than the number of licensed cores (1). Specify "UseLicensedCores true" in agraph.cfg in order to have AllegroGraph use only the licensed number of cores. See these links for details: https://franz.com/agraph/support/documentation/server-installation.html#licensekey https://franz.com/agraph/support/documentation/daemon-config.html#uselicensedcores
- Setting this directive to true in the agraph.cfg file will ensure no more than the licensed number of cores will be used.
XMLVersion1.0-or-1.1- Specifies the XML version to use for RDF serialization. Default is
1.1. SpecifyXMLVersion 1.0if you wish AllegroGraph to use XML 1.0. See also the Lisp function serialize-rdf/xml and the Lisp variable *serializer-xml-version*. (Added in version 7.2.0.)
Session directives
A session is a user-specific connection to the AllegroGraph server. Because it is controlled by a single user, it can be transactional (changes are not permanently added to the database until committed and rollbacks are supported) and it is suitable for loading user-specific scripts. Sessions can also access several stores in a federation.
Sessions can only be created by users who have permission to start sessions (see Managing Users for information on user permissions).
Those users can start sessions from the WebView Repository Menu or from the page displayed by Utilities | Sessions, using the HTTP/REST interface, in Python), and in Java.
The following configuration directives affect sessions:
SessionHostVALUE- If given, must be the server's host name or IP address for use in the URLs returned upon session creation. Useful when deploying a load balancer (like Amazon's Elastic Load Balancer) for sending the SessionHost string in the returned session URL instead of echoing the load balancer's host name from the client request. (Added in version 7.0.0 or before.)
SessionPortsINTEGER-RANGE- If given, must be an integer range like
8000-8020. Defines the ports that will be used for sessions. Useful when these need to be opened in a firewall or similar. When not specified, random ports will be used. (Added in version 7.0.0 or before.)
UseMainPortForSessionsBOOLEAN- A boolean (
yes/no). Ifyesthen the AllegroGraph process listening on the main port will act as a proxy for all requests for session processes. This helps to avoid firewall problems when using sessions, as only the main port needs to be exposed in this case. (Added in version 7.1.0.)
The next two directives control how long a session can be idle before it is terminated by the system. Starting sessions in WebView (see WebView Repository Menu) does allow specification of timeouts when the session is created on the Utilities | Sessions page. Idle timeouts can be specified for sessions started with the HTTP/REST interface, Python, or Java (in all cases setting the lifetime parameter/argument). The value specified must be less or equal to than the MaximumSessionTimeout. Neither DefaultSessionTimeout nor MaximumSessionTimeout can be determined programmatically so users should ask the database administrator for those values if needed.
DefaultSessionTimeoutINTEGER- Sets the idle timeout (aka lifetime) to use for sessions which are created without specifying one. The default value is 300 seconds (5 minutes). This value is used by all sessions created without specifying a timeout. (WebView does allow specifying a timeout when the session is created on the Utilities | Sessions page.) (Added in version 7.0.0 or before.)
MaximumSessionTimeoutINTEGER- Sets the maximum idle timeout (aka lifetime) that may be specified when creating a session. Any attempt to create a session with a timeout larger than this value will fail. The default value is 21600 seconds (6 hours). (Added in version 7.0.0 or before.)
Top-level directives for SSL client certificate authentication
In addition to authenticating remote users via HTTP Basic authentication, users can also be authenticated using SSL certificates. See the comments about authenticating users in the introduction of the Security Implementation document.
The following directives are used to enable SSL client authentication. See the SSL/TLS Quick Start document for details on specifying an SSL/TLS connection to the AllegroGraph server.
SSLCertificateFILE-PATHNAME- This must be the path of a file containing a server certificate and private key, PEM-encoded. This parameter is required when
SSLPortis set. (Added in version 7.0.0 or before.)
SSLPortINTEGER- An integer specifying a port number. If given, an SSL HTTP server will be run on this port. The value of
SSLPortcan be overridden by the--sslportargument to agraph-control (and the--sslportargument to the agraph program). (Added in version 7.0.0 or before.) SSLCAFileFILE-PATHNAME- This must point to a file containing one or more PEM-encoded certificates of trusted certificate authorities (CAs). A client certificate will be trusted if it has been signed by a CA within this file. This setting is required to enable certificate-based client authentication. (Added in version 7.0.0 or before.)
SSLCRLFileFILE-PATHNAME- If supplied, this must point to a file containing a PEM-encoded certificate recovation list (CRL). If a client certificate is received which has a serial number matching one in the CRL, the certificate (and therefore the entire SSL connection) will be rejected. This setting is optional. (Added in version 7.0.0 or before.)
SSLClientAuthUsernameFieldVALUE- (Added in version 7.0.0 or before.) The "Subject" field of a client certificate supplies the identity of the client. The subject is typically composed of several parts, for example:
Subject: C=US, ST=California, L=Oakland, O=Franz Inc., OU=Developers, CN=Joe Smith, [email protected] - This setting specifies which part of the Subject field of the client certificate should be used to identify the user to AllegroGraph. The setting may be CN (the default) or emailAddress. The value of the specified part will be used to perform a lookup in the user database (e.g., Joe Smith or [email protected] depending on the
SSLClientAuthUsernameFieldsetting). SSLClientAuthRequiredBOOLEAN- This setting determines if client certificate validation is required or optional. If yes, all SSL requests must contain a valid client certificate. If no (the default), then SSL requests without a client certificate are allowed. In this case, AllegroGraph falls back to HTTP Basic authentication. (Added in version 7.0.0 or before.)
SSLProtocolVALUE- (Added in version 7.0.0 or before.) There are two types of values here, for compatibility and security. For security you should use either
tlsv1.2ortlsv1.3. For compatibility you can use one of the following insecure protocol versions:- one of
ssl23,sslv3+,tlsv1+ - or one or more of
sslv2,sslv3,tlsv1,tlsv1.1,tlsv1.2,tlsv1.3
- one of
Reminder: all but
tlsv1.2andtlsv1.3have been deprecated and are deemed insecure. Do not use these methods to secure data on a public endpoint.You can read more about the available methods here.
The values are case-insenstive. When setting more than one, spaces or commas can be used as separators. The default is
tlsv1.2 tlsv1.3.SSLCipherSuiteSTRING(Added in version 7.0.0 or before.) A string as described in https://www.openssl.org/docs/man1.0.2/apps/ciphers.html. This string specifies the list of ciphers that the AllegroGraph server is willing to use for incoming SSL connections.
The default value, taken from this guide: https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/, is
"ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:RSA+AESGCM:RSA+AES:!aNULL:!MD5:!DSS"RedirectHTTPOnHTTPSBOOLEAN- If
yes(default isno) HTTP requests sent to the AllegroGraphSSLPortwill result in a 301 Moved Permanently response with the location set to the HTTPS version of the URL. IfSSLPortis not set, this directive has no effect. (Added in version 8.2.0.)
Top-level directives for LLM (Large Language Models)
Note: The llm directive was introduced in version 8.3.0 and in 8.5.0 it has been enhanced and is not completely upward compatible
Th LLM directives are used to specify site specific information about available LLMs. LLMs are described in the Large Language Models and Vector Databases document. Each version of AllegroGraph has code to interact with a set of LLMs but in order to make full use of these LLMs you need to declare the properties of each one of them in the agraph.cfg file. The information here will help Webview display prompts with your defaults. It will also help supply information to do embeddings.
Simply adding a new LLM directive will not make that new LLM accessible. The set of LLMs supported by a particular version of AllegroGraph will be precisely the set described in the LLM directives in the agraph.cfg file generated by install-agraph when a new installation is made.
It's best to take that default configuration (an example shown below) and modify it to suit your needs.
The form of the llm directive is
<llm NAME>
chatModel MODEL1 ARG1="VALUE1",ARG2="VALUE2"
chatModel MODEL2 ARG1="VALUE1",ARG2="VALUE2"
embedderModel MODEL3 ARG1="VALUE1",ARG2="VALUE2"
embedderModel MODEL4 ARG1="VALUE1",ARG2="VALUE2"
vendorfield NAME1
vendorfield NAME2
GLOBALARG1 VALUE1
GLOBALARG2 VALUE2
</llm> NAME names the LLM (for example ollama). That name is case sensitive. For each LLM you can specify zero or more chat models and embedder models and the can specify zero argument value pairs for each of them. You can specify global arguments that are then added to each chatmodel and embedder model specification. The vendorfield specifies those arguments that are needed to in order to access the LLM and they will be prompted for by the UI when doing embeddings.
For example here is a possible specfication for the ollama LLM. The location of the ollama server will likely be different than below so you'll want to change that. The chatModel information is used for prompting by the UI and you can specify other models in the Sparql query if you wish. Likewise the embedderModels are used for prompting but you aren't limited to using only these models. The vendorfield entries should not be modified. They specify which items the embedder expects to see in the embedder specification and that is part of the LLM codebase and can't be changed.
The agraph.cfg created when AllegroGraph is installed will contain llm directives for all LLMs currently supported but will not necessarily work for a given AllegroGraph installation. One will need to modify the directives to fit the current installation. Also as new chat and embedder models are created and old ones retired you'll want to keep the list of models up to date in agraph.cfg
For reference these are the LLMs supported in version 8.5.0 and some of the models in use at the time of release
<llm ollama>
chatModel llama3.1
chatModel mistral
chatModel qwen2
embedderModel all-minilm embedding-can-set-length=true
vendorfield length
vendorfield cansetlength
vendorfield scheme
vendorfield host
vendorfield port
vendorfield embedding-length
vendorfield embedding-can-set-length
scheme http
host localhost
port 11434
</llm>
## You can specify your default API key here using the ApiKey
## field name however this may not be a good idea if you wish
## to keep this key private.
## It's better to use a query option which is then not visible to
## those using webview.
## Note that while the field name ApiKey works in agraph.cfg, when
## assigning the value to a query option you use the name openaiApiKey
##
<llm openai>
chatModel gpt-3.5-turbo
chatModel gpt-4
chatModel gpt-4-turbo
embedderModel text-embedding-3-large embedding-can-set-length=true
embedderModel text-embedding-3-small embedding-can-set-length=true
embedderModel text-embedding-ada-002 embedding-can-set-length=false
NeedsApiKey yes
vendorfield embedding-length
vendorfield embedding-can-set-length
# enabling this in makes a cypress test fail since it expects no
# api key in the vector store:
# ApiKey sk-this-is-not-a-valid-key
</llm>
# the model is specified when the endpoint is created and can't
# be changed.
# so 'default' is just a dummy name here and not the model name
#
<llm databricks>
NeedsApiKey yes
embedderModel default endpoint-url="http://sample.embedserverxx.com"
chatModel default endpoint-url="http://sample.chatserverxx.com"
vendorfield endpoint-url
ApiKey sk-this-is-not-a-valid-key
</llm>
# no embedding models. It's suggested to use voyage for embeddings
<llm claude>
NeedsApiKey yes
chatModel "claude-sonnet-4-0"
ApiKey sk-this-is-not-a-valid-key
</llm>
# like databricks you specify the model when creating the endpoint
# so 'default' is just a placeholder and not the actual model name
<llm azure>
NeedsApiKey yes
embedderModel default endpoint-url="http://sample.embedserverxx.com"
chatModel default endpoint-url="http://sample.chatserverxx.com"
vendorfield endpoint-url
vendorfield embedding-length
vendorfield embedding-can-set-length
ApiKey sk-this-is-not-a-valid-key
</llm>
# no embedder models
<llm deepseek>
NeedsApiKey yes
chatModel DeepSeek-R1-Zero
chatModel DeepSeek-R1
ApiKey sk-this-is-not-a-valid-key
</llm>
<llm gemini>
NeedsApiKey yes
embedderModel gemini-embedding-001 embedding-can-set-length=true
chatModel gemini-2.5-pro
chatModel gemini-2.5-flash
chatModel gemini-2.5-flash-lite
ApiKey sk-this-is-not-a-valid-key
vendorfield embedding-length
vendorfield embedding-can-set-length
</llm>
# no embedder models
<llm groq>
NeedsApiKey yes
chatModel deepseek-r1-distill-llama-70b
chatModel meta-llama/llama-4-maverick-17b-128e-instruct
chatModel mistral-saba-24b
endpointUrl https://api.groq.com/openai/v1
ApiKey sk-this-is-not-a-valid-key
</llm>
# no chat models
<llm voyage>
NeedsApiKey yes
embedderModel voyage-3-large
embedderModel voyage-code-3
embedderModel voyage-finance-2
ApiKey sk-this-is-not-a-valid-key
</llm>
Top-level directives for external authentication
External authentication uses an external service to verify user credentials. Note that all user data (permissions, etc) is stored locally, so in order to be able to authenticate a user externally, a user with the same name must already exist on a given AG server.
The only external authentication protocols currently supported are LDAP and OAuth/OIDC.
AuthPolicyAUTH-POLICY- (Added in version 7.0.0 or before.) This is used to either enable or disable external authentication and/or specify the order of authentication attempts. Note that the policy only applies to basic (username and password) authorization and does not affect certificate or token authorization. The value must be one of the following:
- internal (default) - use only internal authentication mechanisms (AG password, token etc);
- external, external-token and token-external - use only external authentication mechanisms (LDAP or OIDC) and tokens; a password set for a user in the internal AllegroGraph database cannot be used for authentication; external and external-token are identical and mean that external authentication is tried first, and token afterwards; token-external reverses the order; note that there is no way to disable tokens as they are used for WebView and Gruff authentication to avoid having to pass around external, usually long-lived credentials;
- internal-external - for a given username and password, attempt internal authentication first, and if it fails, attempt external authentication;
- external-internal - for a given username and password, attempt external authentication first and if it fails, attempt internal authentication.
LDAPAuthLDAP-CONFIGURATION(Added in version 7.0.0 or before.) Defines an LDAP configuration which will be used to connect to an external LDAP server to perform user authentication. Note that LDAP authentication can only be used if
AuthPolicyoption contains the wordexternal(such asexternal,external-internal,token-externaletc.)The
LDAPconfiguration requires a host and port (optionally, with SSL support) and a username template to construct the username that will be used in bind operation.Here is an example LDAP configuration:
LDAPAuth \ server="ldap://ldap.example.com:389", \ username-template="cn={},dc=example,dc=com"- The following options are supported by
LDAPAuth:server (string): the URI of the LDAP server. The URI scheme must be either
ldapfor regular connection orldapsfor SSL connection. Port is optional and defaults to 389 if the scheme isldapor 636 if the scheme isldaps. Examples:ldap://ldap.example.com,ldaps://ad.example.com:10636. This is a required parameter.username-template (string): the template for constructing the LDAP username from the AG username. Must contain a username marker
"{}"which will be replaced with AG username during an authentication attempt. An exampleLDAPAuthvalue for an Active Directory service would be:LDAPAuth \ server="ldap://ad.example.com", \ username-template="{}@ad.example.comconnection-timeout (integer): timeout in seconds for LDAP connection. Defaults to
10.cache-timeout (integer): caching period in seconds of the LDAP user's password hash to avoid constant authentication requests to the LDAP server. Defaults to
1800(30 minutes). Only successful authentication attempts are cached.
- LDAP authorization works by performing a bind operation using the password provided in the request and a username that is constructed from the username template and the username provided in the request by replacing the username marker with the actual username. If this bind succeeds, AG considers the user authenticated, otherwise unauthenticated. If any connection-related errors happen when attempting the bind, they will be propagated to the user.
OAuthOAUTH-CONFIGURATIONThis directive was added in release 8.3.0. Defines an OAuth/OIDC configuration which will be used to execute the supported OAuth flows. Currently only the Authorization Code flow is supported. In addition to this option, in order to enable OAuth/OIDC authentication
AuthPolicymust contain the wordexternal(such asexternal,external-internal,token-externaletc.)This directive supports Single Sign-on and Sign-off.
Here is an example of OAuth configuration:
OAuth server="http://auth.example.com:4444", \ authorize-endpoint="/oauth2/auth", \ token-endpoint="/oauth2/token", \ jwks-uri="http://auth.example.com:4444/.well-known/keys.json", \ jws-algorithms="RS256, RS512", \ client-id="cc8b0524-ad95-47e8-977d-f3a70e5279a1", \ client-secret="J-k64I.gIC9xD9OM7d9bczKDJ5", \ scope="openid", \ username-claim="sub", \ username-regexp="^(.*)@.*", \ username-substitution="\\1", \ pkce=yes, \ front-channel-logout=yes, \ back-channel-logout=yes, \ explicit-id-token-type="JWT", \ explicit-logout-token-type="logout+jwt"- The following options are supported by
OAuthdirective:server (string): the base URI of the OAuth server. This value must match the
iss(issuer) claim in an ID token. Use*-endpointoptions to specify required paths. If endpoints cannot be expressed as paths relative to the server URI, absolute URIs can be used instead. This is a required parameter.authorize-endpoint (string): the URI of the endpoint on the server where the user should be redirected to initiate the authentication process. If it starts with
/, it will be treated as a path relative to the server URI and will be concatenated with it to get the absolute URI of the endpoint. Otherwise it will be treated as an absolute URI of the endpoint. This is a required parameter.token-endpoint (string): the URI of the endpoint on the server used to exchange the authorization code for the token in the OAuth Authorization Code flow. If it starts with
/, it will be treated as a path relative to the server URI and will be concatenated with it to get the absolute URI of the endpoint. Otherwise it will be treated as an absolute URI of the endpoint. This is a required parameter.jwks-uri (string): the URI of the JWKS file. AllegroGraph performs offline validation of ID tokens and expects to find keys for JWT signature verification at this URI. If it starts with
/, it will be treated as a path relative to the server URI and will be concatenated with it to get the absolute URI of the endpoint. Otherwise it will be treated as an absolute URI of the endpoint. This is a required parameter.jws-algorithms (string): comma-separated list of JWS signature algorithms allowed in JWT tokens. Token signed with unsupported or disallowed algorithms are considered invalid. Supported algorithms are
HS256,HS384,HS512,RS256,RS384,RS512andnone. HMAC-SHA2 algorithms (HS256, HS384 and HS512) expect the value of the client-secret to be used as key. Default value is"RS256, RS384, RS512".client-id (string) and client-secret (string): client credentials obtained when registering AllegroGraph server as a client for the authentication service.
scope (string): a string containing space-separated scopes that will be requested. The default value is "openid".
openidmust be included as one of the values in any string list supplied as the value of this argument.username-claim (string): the claim in the OIDC ID Token returned by the token-endpoint which will be used to compute the username of the internal AllegroGraph user. Defaults to
sub.username-regexp (string): the regular expression for matching groups in the username-claim string which are then used in username-substitution to construct the actual username. In the example above, username-regexp captures a part of the
subclaim that comes before@character in an email. username-susbstitution just takes this captured group without any modifications. Note that` character is used as an escape character in the option values, so a common notation for the first group (\1) becomes\1`. By default both options are unspecified meaning that the value of the username-claim will be used as is.pkce (boolean,
yes/no): if true, PKCE will be used. Default isno.front-channel-logout (boolean,
yes/no): if true, OIDC Front-Channel Logout is enabled. Default isyes. Note that front-channel logout requires HTTPS. Also note that front-channel logout relies on a user-agent (typically a browser) to provide information about login session to AllegroGrash in the form of a cookie, so if this is enabled, AllegroGraph sets authentication cookie withSameSite=None. Finally, note that, to our knowledge, front-channel logout does not work out-of-the-box on Firefox and requires changing a preference value (search for "firefox cookie behavior" in a web search engine). AllegroGraph's front-channel logout HTTP endpoint isGET /oauth/logout.back-channel-logout (boolean,
yes/no): if true, OIDC Back-Channel Logout is enabled. Default isyes. Note that in back-channel relies on direct HTTP communication between authorization service and AllegroGraph server, so the former must be accessible from the latter. Note that AllegroGraph's back-channel logout expects session to be specified via thesid(session ID) claim in the ID Token and the corresponding Logout Token. AllegroGraph's back-channel logout HTTP endpoint isPOST /oauth/logout.explicit-id-token-type (string): an explicit type (
typheader assertion) of the ID Token, which is not required by the OpenID Connect spec, but may be useful for preventing using Logout tokens for logging in. Default is""(empty string), which means that the check will be disabled. Note that if both this value and the value of explicit-logout-token-type (see below) are non-empty strings (i.e. both checks are enabled) than the types must be exactly the same as those values, but if only one check is enabled, than the other token's type will still be checked to be strictly different from the value of the enabled check. For example, if ID token type is""and Logout Token type is"logout+jwt"(the default), the Logout Token type will be checked to be"logout+jwt", and ID Token type will be checked to be anything but"logout+jwt". To completely disable any checks, both values must be set to"".explicit-logout-token-type (string): an explicit type (
typheader assertion) of the Logout Token to be checked during token validation, as recommended by the OpenID Connect spec. Default is"logout+jwt". The value""(empty string) can be used to disable verification. See the `explicit-id-token-type note above for the details on how this value relates to the ID Token type.
AllegroGraph expects auth service to respond with JSON.
Username can currently only be extracted from the OIDC ID Token, hence the required
openidscope.User record with the given username must already exist on the AllegroGraph server for the OIDC authentication flow to work.
ID tokens generated by the authorization server to which the configuration points can be directly used for authenticating API calls. The process of obtaining ID tokens depends on your authorization system. Use the value provided where
<token>appears in the examples just below.ID token can be sent as one of these two HTTP headers:
Authorization: Bearer <ID-token>- or
Authorization: Basic base64(<username>:<ID-token>) - Note that
Bearerauthorization scheme is preferable because it does not need username to specified, but theBasicform is still useful for compatibility because it allows using ID tokens in place of a regular password in tools that automatically handle credentials in URIs as Basic HTTP authorization headers. This may be convenient in e.g. curl to avoid adding the authorization header manually:curl http://<user>:<ID-token>@host:10035/repositories/repo/... - but is especially useful in
agtool, where the user does not have control over the underlying HTTP authorization header:agtool load <user>:<ID-token>@host:10035/repo data.ttl
Top-level directives for account management
AuditEventsToEmailVALUE(Added in version 7.0.0 or before.) A directive that instructs the system to send notification emails to a specified address when various audit events occur. This option can be specified multiple times to cause emails to be sent to multiple addresses.
The format for this directive is
AuditEventsToEmail to="email", [smtphost="smtp-host-name"], \ events="comma-separated events"Where
smtp-host-nameis the name of theSMTPHostdefinition to be used andemailis an email address. If only one SMTPHost is defined, this option can be left unspecified. Events can be any audit events (see Audit event types).For example, here is a valid specification, assuming an
SMTPHostnamed gmail has been defined:AuditEventsToEmail to="[email protected]", smtphost="gmail", \ events="expirePassword,addUser,deleteUser"- If there is only one
SMPHostdefined, smtphost can be left unspecified:AuditEventsToEmail to="[email protected]", \ events="expirePassword,addUser,deleteUser" - See Auditing email notifications for more information.
AccountExpiry- The time since the last authenticated activity of a user after which the account is permanently deleted. This option does not affect users with superuser permission. The default is that accounts do not expire. (Added in version 7.0.0 or before.)
AccountUnsuspendTimeout- The time after which suspended accounts are unsuspended automatically. See
MaxFailedLogins. (Added in version 7.0.0 or before.) LoginTimeout- A time (value like
10s,5m,1h). If set, AGWebView login sessions are timed out after this amount of idle time. The default is no timeout. (Added in version 7.0.0 or before.)
MaxFailedLogins- The number of failed logins in a row after which the account is suspended. Suspended accounts can be unsuspended explicitly by superuser or automatically if
AccountUnsuspendTimeoutis set. (Added in version 7.0.0 or before.)
PasswordChangeAllowed- A boolean (
yes/no) that can be used to control whether users can change their own password. The default isyes. Ifno, then only superuser can change passwords. (Added in version 7.0.0 or before.) PasswordExpiry- The time since the last password change after which the password will be expired. One cannot login with an expired password, it can only be used to change the password. The new password must not be the same as the expired password. (Added in version 7.0.0 or before.)
PasswordExpiryGrace- The time since password expiry after which the account is disabled. It's not possible to log in or change the password with a disabled account. Only the administrator can reenable accounts. This option does not affect users with superuser permission. (Added in version 7.0.0 or before.)
PasswordMinLength- The minimum number of characters all new passwords must have. The default is 0. (Added in version 7.0.0 or before.)
PasswordMinUppercaseChars- The minimum number of uppercase characters all new passwords must have. The default is 0. (Added in version 7.0.0 or before.)
PasswordMinDigitChars- The minimum number of digit characters all new passwords must have. The default is 0. (Added in version 7.0.0 or before.)
PasswordMinSpecialChars- The minimum number of non-alphanumeric characters all new passwords must have. The default is 0. (Added in version 7.0.0 or before.)
SuperUserCanAccessAllData- A boolean (
yes/no) that controls whether superuser bypasses normal permission checks for triples data. If it is on (the default), then superuser will have read/write access to all repositories. If it is turned off, then superuser needs to be granted access to repositories. This is most useful when auditing is enabled and any change to user permissions is logged. (Added in version 7.0.0 or before.)
Top-level directives for the event scheduler
The event scheduler, described in the Event Scheduler document, allows users to schedule times when a script should be run. The scripts can be run once or repeated regularly. These two configuration options should be set for the scheduler to work. The first must be set in order that a script file to run can be found. The second must be set if one wants emails sent reporting that a script ran or failed to run. Emails sent when a script runs successfully also contain the output of the script.
SchedulerDirDIRECTORY- The directory in which scheduler scripts must be found. It is permitted to put subdirectories in this directory and put scripts in subdirectories. This value must be set in the configuration file if it is desired to schedule event scripts. There is no default value for this directive. (Added in version 7.0.0 or before.)
SchedulerSMTPConfigSMTP-ID- See the description of SMTPHost above. Its first argument is an ID which can be specified as the value of this directive. If it is, that SMTPHost will be used to send scheduler notification emails. This directive must be specified for such emails to be sent even if only one SMTPHost is specified. There is no default value of this directive. (Added in version 7.0.0 or before.)
Top-level directives for multi-master replication clusters
These top-level directives affect multi-master replication clusters, described in the Multi-master Replication document. The first, MaximumBackupAge, specifies how old backups of the controlling instance are allowed to be.
MaximumBackupAge- The value must be an integer (meaning a number of second) or an integer followed by
s(for seconds),m(for minutes),h(for hours), ord(for days). The default is 3600 (i.e. one hour). When asked to grow a cluster an existing backup of the controlling instance is used unless it's older than thisMaximumBackupAgein which case a new backup is made. See the section Controlling instance backups and MaximumBackupAge for more information on this directive. (Added in version 7.0.0 or before.)
The other settings affect how replication cluster instances are kept in sync. These latter directives specify the default values of these setting and the values may be overridden by commands which create a replication cluster and settings can also be changed once a replication cluster exists. The meaning and effect of a setting is described in the Instance Settings section of the Multi-master Replication document. Changing the settings after a cluster has been created is also described in that section. The directives are:
durability- See the description of the Durability setting for information on this directive. (Added in version 7.0.0 or before.)
distributedTransactionTimeout- See the description of the Distributed Transaction Timeout setting for information on this directive. (Added in version 7.0.0 or before.)
transactionLatencyCount- See the description of the Transaction Latency Count setting for information on this directive. (Added in version 7.0.0 or before.)
transactionLatencyTimeout- See the description of the Transaction Latency Timeout setting for information on this directive. (Added in version 7.0.0 or before.)
More on controlling memory usage
While processing a query, backend processes may allocate memory from the operating system. When a previously allocated memory area is no longer used, the processes normally do not return it to the operating system, in hopes of reusing it for subsequent queries. However, it may be advantageous to periodically return idle memory to the operating system. The MemoryCheckWhen and MemoryReleaseThreshold configuration parameters allow for this.
Note that while returning memory to the OS makes memory available to other processes, it also incurs the overhead of minor page faults on subsequent allocations in the same process.
Each shared backend and dedicated session tracks its own memory usage. When a check is made the resident set size (RSS) of the backend or session process is compared to MemoryReleaseThreshold. If the RSS is greater than MemoryReleaseThreshold then an effort is made to give back as much memory to the OS as possible.
Since this kind of check is fairly expensive, performing it too often can have a detrimental effect on overall performance. The MemoryCheckWhen directive specifies under what circumstances it should be done. Let's see a couple of examples.
Perform memory check after every 7 queries:
MemoryCheckWhen query:7 Perform memory check after every 2 transactions:
MemoryCheckWhen transaction:2 Perform memory check every 10 seconds:
MemoryCheckWhen time:10 Finally, a complete configuration that would check whether the memory was above the threshold every 10 seconds and after every 2 transactions:
MemoryReleaseThreshold 2g
MemoryCheckWhen time:10
MemoryCheckWhen transaction:2 Note that MemoryReleaseThreshold must be specified whenever MemoryCheckWhen is. If neither of two are specified, then no checks are ever performed.
Memory locking
You can lock indexes and/or the string table into memory if desired. This improves performance but can lead to problems if memory is tight. This can be done with the agtool memory-lock (and memory-unlock) commands. Run
% agtool memory-lock --help
for further information.
CORS directives
CORS (Cross-Origin Resource Sharing), if enabled, allows scripts run on a web page from one server to make HTTP requests to the (different) server where AllegroGraph is running. CORS is not enabled by default because if not configured properly, it can introduce security holes. The following directives enable CORS limited as the various options allow. A general tutorial on CORS is available at http://www.html5rocks.com/en/tutorials/cors/. See here in the REST/HTTP interface document for more information.
You may want to use CORS to communicate with the AllegroGraph server if you are writing a web application that will be accessing AllegroGraph but will not be served from the same domain that the server uses. This image shows a possible configuration:
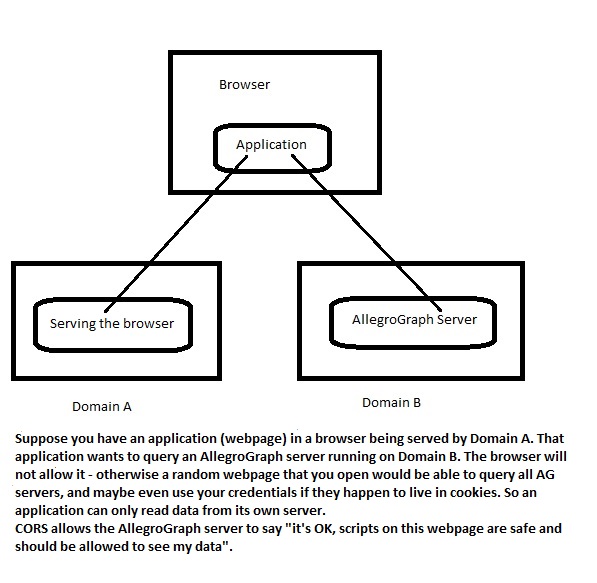
CORS support is enabled if the configuration file contains at least one of the following directives: CorsAllowAll, CorsAllowOrigin, CorsAllowRegex.
The following configuration file directives are used to configure CORS:
CorsAllowAllBOOLEAN- If set to 'yes' then requests from all origins will be accepted. When
yes, values forCorsAllowOriginandCorsAllowRegexare ignored. The default isno. (Added in version 7.0.0 or before.) CorsAllowOriginDOMAIN- Allow the specified origin (i.e. domain) to issue cross-site requests. Only one domain can be specified per entry but this directive can be specified multiple times. Domain names are case-insensitive. (Added in version 7.0.0 or before.)
CorsAllowRegexREGEX- Allow all origins that match the given regular expresion to issue cross-site requests. Only one regular expression is allowed per entry but this directive can be specified multiple times. Regular expression syntax is described here. Regular expressions can specified to make case-insensitive matches. (Added in version 7.0.0 or before.)
The following directives affect how CORS requests are handled when they are allowed.
CorsUrlRegexREGEX- Only enable CORS for target URLs that match the given regular expression. If this option is not specified, all URLs are allowed. If it is specified then the associated regular expression is compared to URLs being requested and allowed only if they match. This directive can be specified multiple times and if it is, CORS will be enabled for URLs that match at least one of the supplied regexes. Regular expression syntax is described here. Regular expressions can specified to make case-insensitive matches. (Added in version 7.0.0 or before.)
CorsAllowMethodsMETHOD-LIST- A space or comma separated list of allowed methods for cross-origin requests. List values are case-insensitive. The default is:
DELETE GET OPTIONS PATCH POST PUT. (Added in version 7.0.0 or before.) CorsAllowMethodMETHOD- A single HTTP method to be added to
CorsAllowMethods(defined above). TheCorsAllowMethoddirective can be specified multiple times. (Added in version 7.0.0 or before.) CorsAllowHeadersHEADERS-LIST- (Added in version 7.0.0 or before.) A space or comma separated list of headers allowed in cross-site requests. Headers are case-insensitive. The default list is:
Accept Accept-encoding Authorization Content-type Dnt Origin User-agent
CorsAllowHeaderHEADER- A single HTTP header to be added to
CorsAllowHeaders(defined above). This directive can be specified multiple times. (Added in version 7.0.0 or before.) CorsExposeHeadersHEADER-LIST- A space or comma separated list of custom response headers that should be readable by cross-site requests. The default is empty. (Added in version 7.0.0 or before.)
CorsExposeHeaderHEADER- A single HTTP header to be added to
CorsExposeHeaders(defined above). This directive can be specified multiple times. (Added in version 7.0.0 or before.) CorsPreflightMaxAgeINTEGER- Specifies how long (in seconds) a response to a preflight request should be cached by the browser. The default is 86400 (24 hours). If set to zero the corresponding HTTP header
Access-Control-Max-Agewill not be sent. (Added in version 7.0.0 or before.) CorsAllowCredentialsBOOLEAN- If set to 'yes' then cross-origin requests will be allowed to contain authentication info, such as cookies and auth headers. The default is 'no'. (Added in version 7.0.0 or before.)
Catalog definitions
Catalogs are locations on disk where AllegroGraph keeps its repositories. These locations are specified in the configuration file, along with some optional default settings for stores in the catalogs. Most of the time, you will want to specify all catalogs directly in the configuration file, but it is also possible to enable dynamic catalogs, which can be created and deleted either using the agtool catalogs tool or through the HTTP interface (as described in HTTP Protocol - SPARQL Endpoint).
Catalog definitions in the server configuration files serve as templates for creating databases. The parameters defined in the catalog definition will be copied to the database when it is created. Changes to the catalog definition do not influence the settings of existing databases. In order to modify parameters of existing databases, the file 'parameters.dat' in the database 'Main' directory must be edited and the database be restarted.
There are three types of catalog definitions that can occur in an AllegroGraph configuration file: special catalogs (root, system and fedshard catalogs), named catalogs, and a dynamic catalog specification. The first was seen in the example above (<RootCatalog> ... </RootCatalog>), and is used to determine where stores live that do not have a catalog specified. Named catalog specifications look similar:
<Catalog temporary>
Main /tmp/catalog
</Catalog> The first entry specifies the catalog name, temporary in the example. Catalog names can contain any characters except slashes, backslashes, colons, and tildes.
The catalog name can then be used to specify the catalog when creating or accessing repositories.
The names root, system and fedshard are reserved and may not be used in a Catalog directive. These three catalogs must be defined in every server and if not found in the configuration file they will be created automatically by the server.
The catalog directives of the root catalog are found within between <RootCatalog> and </RootCatalog> in the configuration file.
The system catalog is where AllegroGraph records information about the operation of the server. It can be given catalog directives in the configuration file between the directives <SystemCatalog> and </SystemCatalog>.
The fedshard catalog is reserved for storing metadata for fedshard repositories and not the data itself so very little disk space is required. The only catalog directive recognized in the configuration of the fedshard catalog is the Main catalog directive specifying the directory to be used to store the directories holding metadata for each fedshard repository. This Main directive for the fedshard repositories can be specified between the <FedshardCatalog> and </FedshardCatalog> directives in the configuration file.
Finally, a dynamic catalog definition is used to provide the settings for catalogs created over HTTP. If no dynamic catalog is defined, this feature is disabled.
<DynamicCatalogs>
Main /tmp/dynamic
</DynamicCatalogs> The directory (as well as any other catalog directories, see below) given for dynamic catalogs will be extended with a catalog name when such a catalog is created. For example, given the above configuration, a dynamic catalog named scratch would end up in /tmp/dynamic/scratch.
Catalog directives
Some of the directives allowed within a catalog definition (those marked as inheritable) can also be specified at the top-level, where they act as a default value inherited by catalogs which don't explicitly specify that setting.
MainPATHNAME- Required for every catalog. Specifies the directory in which the repositories for the catalog are stored. (Added in version 7.0.0 or before.)
TransactionLogDirPATHNAME(Added in version 7.0.0 or before.) Specifies the directory in which transaction log subdirectories will be created for repositories in this catalog. The directory will be extended with the name of a repository. For example, if
TransactionLogDiris/tmp/tlogs, then transaction logs for repositoryexamplewill be stored in/tmp/tlogs/example. This parameter is optional and defaults to the value supplied for theMainparameter.See the line in the example below
TransactionLogDir /mnt/disk3/ag4-transaction-logswhich says transaction logs should be placed in the /mnt/disk3/ag4-transaction-logs/[repository-name]/ directory.
The value of this directive can affect performance. See the discussion in the Performance Tuning document.
StringTableDirPATHNAME- Specifies the directory in which string table subdirectories will be created for repositories in this catalog. See
TransactionLogDirfor information on how directory names are constructed. This parameter is optional and defaults to the value supplied for theMainparameter. The value of this directive can affect performance. See the discussion in the Performance Tuning document. (Added in version 7.0.0 or before.)
StringTableSizeINTEGER- the value must be an integer, optionally followed by a multiplier (k=2^10 or m=2^20). The value determines the minimum number of slots to use for the hash table used to map UPIs to their corresponding strings. The actual number of slots configured is the supplied value rounded up to the nearest power of two, with a minimum of 1M (1,048,576). The default number of slots is 16,777,216 (16M). The maximum possible number of slots is 536,870,912 (512M). Increasing the number of slots may result in better insert and lookup performance for repositories with a lot of unique strings. Each slot takes 4 bytes of memory. Checkpoints will take longer the more slots there are as the information stored in the slots is recorded in the transaction log during checkpoints. As said, the value of this directive can affect performance. See the discussion of directives that affect performance in this section of the Performance Tuning document. (Added in version 7.0.0 or before.)
StringTableCompressionVALUE inheritable- If given, the value must be one of
none(the default),lzo(same aslzo999),lzo1,lzo999(same aslzo), orzlib.lzo999compresses more thanlzo1but takes more time. The string table compression method can only be set when a repository is created. See the discussion of this directive here in the Performance Tuning document. (Added in version 7.0.0 or before.)
ExpectedStoreSizeINTEGER inheritable- This is the number of triples one expects to have in the store. It is used by the server to select suitable values for things like internal table sizes. Most of the time, you should only worry about this when trying to squeeze out more performance. Setting it too high can lead to some wasted resources, setting it too low can result in sub-optimal performance and setting it much low (much less than the maximum effective value and less than one 25th of the real size) can cause enormous index management overhead and lead to extreme loss of performance on a continuously evolving store. The maximum effective value is one billion triples. Stores can be much bigger, of course, but values larger than one billion do not affect initial internals. As said, the value of this directive can affect performance. See the discussion of directives that affect performance in this section of the Performance Tuning document. (Added in version 7.0.0 or before.)
CheckpointIntervalTIME inheritable- A time (with a value like
10s,5m,1h) that specifies how often checkpoints will be performed. The default value is5m. The value of this directive can affect performance. See the discussion in the Performance Tuning document. (Added in version 7.0.0 or before.) MaxRecoveryTimeTIME inheritable- A time (with a value like
10s,5m,1h). AllegroGraph normally performs checkpoints at regular intervals, as configured by theCheckpointIntervaldirective. IfMaxRecoveryTimeis specified, AllegroGraph will maintain an estimate of how long recovery would take if a crash occurred at a given moment. When this estimated recovery time exceedsMaxRecoveryTime, a checkpoint will be performed. (Added in version 7.0.0 or before.) TransactionLogSizeINTEGER inheritable- A size (an integer, perhaps labeled with 'k' for kilobytes, 'm' for megabytes, or 'g' for gigabytes, for example
10mfor ten megabytes) that determines how big individual transaction log files are allowed to grow. When a transaction log size meets or exceeds this size, a new transaction log file will be created. The maximum is just under 4g. (Added in version 7.0.0 or before.) TlogSyncMethodVALUE- This parameter specifies the synchronized writing method for transaction logs. Three methods are supported: ODIRECT, SYNC, and fsync. The default (if this parameter is unspecified) is ODIRECT and that is the recommended choice on ext3 file systems. For catalogs residing on non-ext3 file systems, the other choices may yield performance benefits. (You will potentially see performance degradation in checkpointing. If that takes longer than expected and you are using a non-ext3 filesystem, try the other allowable values.) (Added in version 7.0.0 or before.)
DesiredTlogFilesINTEGER(Added in version 7.0.0 or before.) This parameter specifies the number of transaction log files which should be preallocated at database creation time. The default value is 2. Specifying a larger value helps lower the probability of additional transaction log files being created during commits.
Note: The circumstances under which the number of tlog files may grow larger than
DesiredTlogFilesare if there is a long-running backup, transaction log archiving is running slowly, or if replication is running slowly or stalled. When possible, AllegroGraph will reduce the number of transaction log files back down to DesiredTlogFiles.InstanceTimeoutTIME inheritable- The time (a value like
10s,5m,1h) a database instance will stay open without being accessed. The default is one hour. Starting a database instance can be time consuming. By keeping idle instances around this directive allows for trading off memory for lower worst case latency on database access. Note that this value is advisory; AllegroGraph checks for idle database instances intermittently so a given instance may linger longer than theinstanceTimeout. (Added in version 7.0.0 or before.)
TransactionLogArchivePATHNAME- This directive specifies a directory for storing archived transaction log files. See Transaction Log Archiving for more details. (Added in version 7.0.0 or before.)
TransactionLogRetain- This directive is no longer used and a warning will be signaled if it appears in a configuration file. See Transaction Log Archiving for more details and how to achieve what used to be done by this directive. (Added in version 7.0.0 or before.)
TransactionLogReplicationJobname- This directive is no longer used and a warning will be signaled if it appears in a configuration file. See Transaction Log Archiving for more details and how to achieve what used to be done by this directive. (Added in version 7.0.0 or before.)
Example Configuration
What follows is a more complete example to demonstrate the various configuration options in more detail.
# Don't allow normal HTTP access, only SSL
Port 10035
AllowHTTP no
SSLPort 10036
SSLCertificate /var/lib/ag4/server.cert
SettingsDirectory /var/lib/ag4/settings
Backends 5
# You can actually remove this after the first server run, to
# reduce the risk of someone finding it here.
SuperUser test:xyzzy
ExpectedStoreSize 100000
SessionPorts 8080-8083
<RootCatalog>
Main /var/lib/ag4/root
</RootCatalog>
<Catalog fast>
ExpectedStoreSize 2000000
CheckpointInterval 1h
Main /var/lib/ag4/fast
StringTableDir /mnt/disk2/ag4-string-tables
TransactionLogDir /mnt/disk3/ag4-transaction-logs
</Catalog>
<DynamicCatalogs>
Main /var/lib/ag4/dynamic
</DynamicCatalogs> Changing database parameters
In some circumstances, it is desirable to modify the settings of an existing database by editing the 'parameters.dat' file in the database main directory. The syntax of this file is similar to that of the server configuration file, but only the parameters that are normally present inside of a catalog definition are allowed.
For example, the 'parameters.dat' file for a database 'demo' created with the 'fast' catalog definition above would look like this:
CheckpointInterval 1h
Main /var/lib/ag4/fast
StringTableDir /mnt/disk2/ag4/fast It might be edited to change the CheckpointInterval. It is also possible to add new file placement rules. When modifying any of the file placement related parameters of a database, care must be taken to make sure that all files that constitute the current database state are still visible to the database. For example, if the StringTableDir directory in the database above should be removed, all files in /mnt/disk2/ag4/fast/demo/ would need to be manually moved into the main directory of the database, /var/lib/ag4/fast/demo/.
Note that resetting some parameters in 'parameters.dat' has no effect. In particular, changing ExpectedStoreSize in parameters.dat does nothing. The only way to change that is to set the option in the configuration file and recreate the database.
When moving around database files, it is important to know that some of these files are sparse, i.e. they contain holes (unallocated blocks). Many file management utilities (like 'cp' and 'tar') can optionally preserve file sparseness, but care should be taken to make sure that copies of database files don't become unexpectedly large after a manual manipulation.
Server control: starting and stopping the server
The method used to start and stop the AllegroGraph server depends on the type of install: an RPM install or installation from a tar.gz file (see Server Installation). The RPM install places files in specific locations. The configuration file agraph.cfg is placed in /etc/agraph/ and you can use /sbin/service to start and stop Allegrograph:
You can start AllegroGraph by running:
/sbin/service agraph start
You can stop AllegroGraph by running:
/sbin/service agraph stop In addition, chkconfig can be used to make AllegroGraph start when the system boots. For example:
chkconfig agraph on You can also use agraph-control with an RPM install.
The tar.gz installation is more flexible, and you choose the AllegroGraph directory as part of the installation process (again, see Server Installation). The typical way to start and stop AllegroGraph installed from a tar.gz file is to use agraph-control.
Starting multiple servers
You can run multiple servers on the same machine if desired. Separate instances must have different settings directories, and must use different ports. These are specified in the configuration file so each server instance must have its own configuration file. If you try to run two servers with conflicting information, the second will fail to start with a message similar to:
Daemonizing...
Starting server failed:
There appears to already be an AllegroGraph server running (pid 12803).
If it is your intention to run another AllegroGraph server
simultaneously,
please make a separate configuration file which has different values
for the following parameters:
Port 61111
SettingsDirectory /disk1/allegrograph/settings/
agraph-control
agraph-control is a script that can be used to start and stop AllegroGraph. It also can process other commands, as described below. agraph-control is located in the bin/ subdirectory of the AllegroGraph directory. The calling template is
agraph-control [OPTIONS] <command> Additionally when command is start or restart, agraph-control will also accept additional command-line options, so the calling sequence is
agraph-control [CONTROL-OPTIONS] <start | restart > [-- COMMAND-LINE-OPTIONS] The command-line-options are the arguments accepted by the agraph program (which is called by agraph-control) and are listed below.
Control options
There are three control options: --config, --cluster-config and --cluster.
--configThe value of
--configshould be the path of the configuration file. The usual location of that file in a tar.gz install is the lib/ subdirectory of the AllegroGraph directory. The usual location in an RPM install is /etc/agraph/. The default name is agraph.cfg.Thus, with a tar.gz install, you can start the AllegroGraph server with
[Agraph dir]/bin/agraph-control --config [Agraph dir]/lib/agraph.cfg start- If
--configis not specified, the behavior is as follows:For an RPM install when not running as root, there is no default and
--configmust have a value.For an RPM install when running as root, the default is /etc/agraph/agraph.cfg.
For a tar.gz install, the default is agraph.cfg in lib/ subdirectory of the AllegroGraph directory.
- If the file specified as the value of
--configis not found, the AllegroGraph server is not started and a message like the following is printed:Cannot locate configuration file (tried <supplied path>). - If
--configis unspecified, and the agraph.cfg file is not found in the default location or you are not running as root with an RPM install, the AllegroGraph server is not started and the following message is printed:Cannot determine location of configuration file. Please use --config
--portN- Specifies that the AllegroGraph server will communicate on port number
N, thus overriding the value specified by thePortdirective in the configuration file (see above). This argument is convenient when the number in the configuration file happens to be in use. --sslportN- Use this SSL port number rather than the one specified by the
SSLPortdirective in the configuration file (see above). This argument is convenient when the number in the configuration file happens to be in use.
Control commands
The commands to agraph-control are:
- status
- Writes to stdout, "up" if the server is running and "down" if not.
- start
- Start the AllegroGraph server. This has no effect if the server is already running.
- stop
- Stop the AllegroGraph server. This is the normal stop command and it attempts to perform a clean shutdown of all open databases.
- force-stop
- Stop the AllegroGraph server. This is the emergency stop command and open databases may not be cleanly closed.
- restart
- Requests that the server shut itself down, if running, and then start back up again.
AllegroGraph service daemon signal handling
The signals used by the AllegroGraph service daemon are:
- SIGTERM
- for normal stopping, used by the stop command.
- SIGQUIT
- for emergency stopping, used by the force-stop command.
Exit Status
For the status command, a 0 exit status is returned if the server is up, non-zero if the server is down.
For all other commands, the exit status is 0 if the command was executed succesfully, and non-zero if an error is reported during command execution.
The agraph program
agraph-control is a script which launches the actual program, named agraph. While agraph-control is recommended when starting the server, you can use agraph, particularly when you wish to invoke options not available to agraph-control. agraph accepts the following command-line arguments:
--configfile- The location of the configuration file. Defaults to
agraph.cfgin the executable's directory, or, failing that,/etc/agraph/agraph.cfg. (If the configuration file cannot be found, AllegroGraph does not start and prints the message No configuration file found. --log-dirdirectory- Specify where the server log files are written. Overrides the
LogDirdirective. --debug- Start the server in debug mode, which means logging will be more verbose.
--log-levellevel- Set an explicit log-level (debug, info, warn, or error), or specify log-levels per category, for example:
debug,daemon:info,storage:warn.
--portN- Use this port number rather than the one specified by the
Portdirective in the configuration file (see above). This argument, similar to the--portargument to agraph-control (see above) is convenient when the number in the configuration file happens to be in use. --sslportN- Use this SSL port number rather than the one specified by the
SSLPortdirective in the configuration file (see above). similar to the--sslportargument to agraph-control (see above) is convenient when the number in the configuration file happens to be in use.
--http-tracefile-pathname- Write a log of all HTTP traffic to the file specified. If specified, overrides the HttpTrace configuration directive. If the pathname is relative, the location is with respect to the log directory.
--http-trace-optionsoptions- If specified, overrides the HttpTraceOptions configuration directive. A comma separated list of options. Options starting with the character + turn on the corresponding log category. Those starting with - turn them off (allowing you to enable a general category and turn off specific items). Use the max-message-size= option to truncate overly long messages. The default is `+xmit,max-message-size=1000`. The available log categories are listed in the Debugging section
of the AllegroServe documentation. --pid-filefile- Determines where the process id of the server is written. Overrides the
PidFiledirective. --run-asuser- If started as root, run AllegroGraph as the specified user. Overrides the
RunAsdirective. --no-daemonize- If specified, then the service daemon will run in the foreground.
--stop-server- Stop the AllegroGraph server. Either the --pid-file or --config parameter must also be specified to identify the server instance that should be stopped.
--stop-timeoutseconds- Specifies how long to wait before giving up on a
--stop-serverrequest. Must be an integer greater than 0. If--forcehas also been supplied, then the default value is 10; otherwise the default value is 60. --version- Print version information (such as the version number and build date).
--short-version- Print just the version number.
--help- Print information about these arguments.
Troubleshooting
Shared memory size and permission to use /dev/shm
AllegroGraph uses POSIX shared memory for inter-process communication.
Each AllegroGraph instance requires a certain amount of shared memory (depending on the ExpectedStoreSize setting). The actual size is reported in agraph.log when an instance is started.
On Linux, the shared memory comes from tmpfs, which is typically mounted on /dev/shm. Default size is half of RAM. To resize, issue a command like the following as the root user:
mount -o remount,size=<size> <shm-device-file> For example:
mount -o remount,size=8G /dev/shm To make the change permanent, /etc/fstab needs to be updated or the above command must be run from a startup script such as /etc/rc.local.
/dev/shm is usually mounted with permissions that allow any process to use it, for example:
$ ls -ld /dev/shm
drwxrwxrwt 2 root root 40 Oct 17 16:31 /dev/shm/ However, sites with strict security policies may have /dev/shm mounted with tight permissions (for example, to only allow root to use shared memory). For AllegroGraph to operate, /dev/shm must have permissions which allow at least the RunAs user to read and write to it. Consult with your systems administrator if AllegroGraph fails to start up due to the permissions on /dev/shm.
If a previously-working instance doesn't start due to shared memory problem, then there may be a lingering process which still has a handle on a shared memory segment.
$ <stop-allegrograph>
# Check total size, available and used size.
$ df -h /dev/shm
# If the 'Used' column shows a non-trivial amount,
# look for processes that use /dev/shm.
$ lsof /dev/shm
# Maybe kill offending processes
$ kill -9 <pid1> <pid2> ...
$ <start-allegrograph>