
AllegroGraph + LLMs + Documents + VectorStore
The Most Complete Neuro-Symbolic AI Solution
AllegroGraph Overview
- AllegroGraph is a Horizontally Distributed, Multi-model (Vector, Document and Graph), Entity-Event Knowledge Graph platform that enables businesses to build Neuro-Symbolic AI applications capable of extracting sophisticated decision insights and predictive analytics from their highly complex, distributed data that can’t be answered with only Generative AI.
- FedShard™ Speeds Complex Queries through a patented in-memory federation function, the results from each machine are combined so that the query process appears as if only one database is being accessed, although many different databases and data stores and knowledge bases are actually being accessed and returning results. This unique data federation capability accelerates results for highly complex queries across highly distributed data sets and knowledge bases.
- Unlike traditional relational databases or simple property graph databases, Franz’s product AllegroGraph employs a combination of document (JSON and JSON-LD) Vector (Generation and storage), and graph technologies that process data with contextual and conceptual intelligence. Knowledge Graphs built on the AllegroGraph platform are able to run queries of unprecedented complexity to support predictive analytics that help companies
make better, real-time decisions.
About the Technology
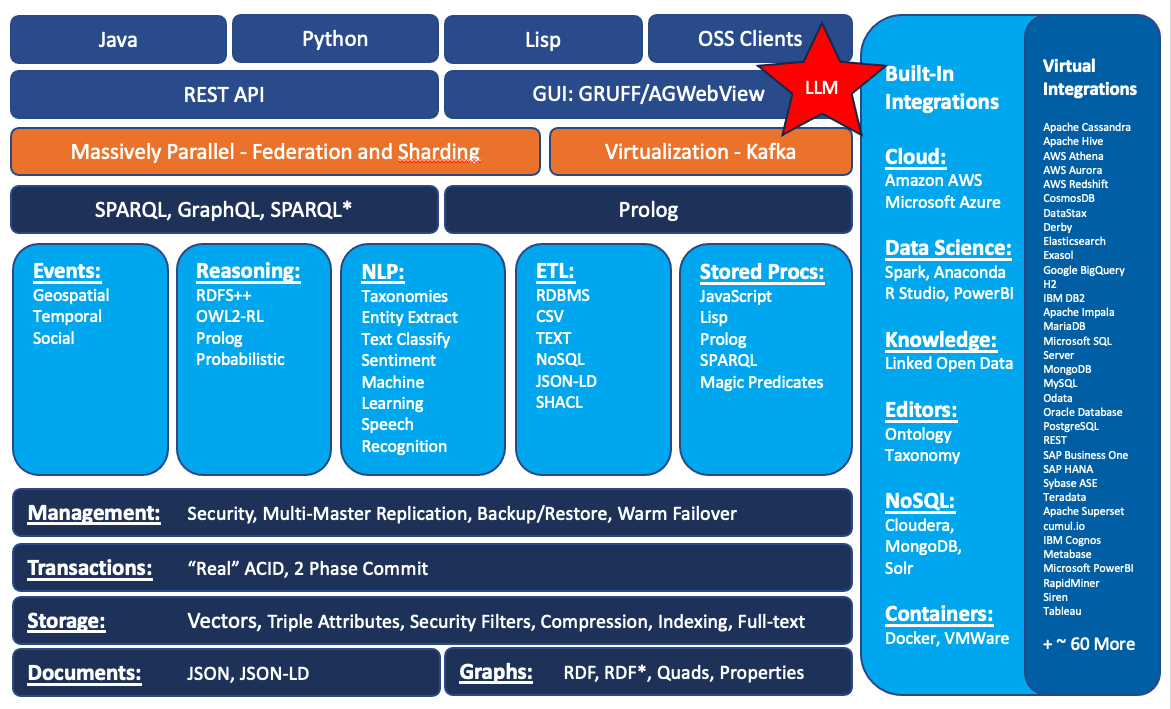
- The corner stone of Franz's Neuro-Symbolic AI platform is the AllegroGraph database with FedShard™ and LLMagic™. AllegroGraph is a purpose built, horizontal sharding, high-performance, persistent, graph, vector, and document database. AllegroGraph uses efficient memory management in combination with disk-based storage, enabling it to scale to billions of triples/quads/documents while maintaining superior performance. AllegroGraph is W3C/ISO standards compliant and supports LLMs, JSON, JSON-LD, SPARQL 1.1, OWL Reasoning, SHACL, and Prolog rules and reasoning directly and from numerous client applications.
-
Key Features
- Neuro-Symbolic AI Capabilities – LLM Integration
- VectorStore – Generation and Storage of Vectors.
- FedShard™ Speeds Complex Queries – Patented sharding and federation feature.
- Entity-Event Knowledge Graph Modeling
- Multi-model Document (JSON, JSON-LD) and Graph Database (RDF, OWL)
- Gruff – Knowledge Graph Explorer directly integrated and browser based.
- Cloud Native – Amazon Marketplace and Amazon EC2 – AMIs
- AllegroGraph is 100 percent ACID, supporting Transactions: Commit, Rollback, and Checkpointing.
- Security – Industry’s most secure Graph Database with Triple Attributes.
- Multi-Master Replication for Globally Distributed Data Center Coordination
- Online Backups, Point-in-Time Recovery, Replication, Warm Standby
- Dynamic and Automatic Indexing – All committed triples are always indexed (7 indices)
- Advanced Text Indexing – Text indexing per predicate
- Two-Phase Commit – SOLR and MongoDB Integration
- SHACL and SPIN support.
- All Clients based on REST Protocol – RDF4J, Java Jena, Python, C#, Clojure, Perl, Ruby, Scala, and Lisp clients
- Completely multi-processing based (SMP) – Automatic Resource Management for all processors and disks, and optimized memory use. Column-based compression of indices – reduced paging, better performance
- Server side Stored Procedures using the JavaScript API
- JavaScript-based interface (JIG) for general graph traversal
- Soundex support – Allows Free text indexing based on phonetic pronunciation
- User-defined Indices – fully controllable by system administrator
- Built-in Text search
<!–
* AllegroGraph is 100 percent ACID, supporting Transactions: Commit, Rollback, and Checkpointing.
* Full and Fast Recoverability
* 100% Read Concurrency, Near Full Write Concurrency
* Online Backups, Point-in-Time Recovery, Replication, Warm Standby
* Dynamic and Automatic Indexing – All committed triples are always indexed (7 indices)
* Advanced Text Indexing – Text indexing per predicate
* SOLR and MongoDB Integration
* SPIN support (SPARQL Inferencing Notation). The SPIN API allows you to define a function in terms of a SPARQL query and then call that function in other SPARQL queries. These SPIN functions can appear in FILTERs and can also be used to compute values in assignment and select expressions.
* All Clients based on REST Protocol – RDF4J, Java Jena, Python, C#, Clojure, Perl, Ruby, Scala, and Lisp clients
* Completely multi-processing based (SMP) – Automatic Resource Management for all processors and disks, and optimized memory use. See the performance tuning guide here, and server configuration guide here
* Column-based compression of indices – reduced paging, better performance
* Triples Level Security with Security Filters
* Cloud-Hosted AllegroGraph – Amazon EC2
* The AllegroGraph RDF server can be scripted using the JavaScript API
* JavaScript-based interface (JIG) for general graph traversal
* Soundex support – Allows Free text indexing based on phonetic pronunciation
* User-defined Indices – fully controllable by system administrator
* Client-Server GRUFF with Graphical Query Builder
* Plug-in Interface for Text Indexers (use SOLR/Lucene, Native AG Full Text Indexer, Japanese Tokenizer)
* Dedicated and Public Sessions – In dedicated sessions users can work with their own rule sets against the same database
* Visit our Learning Center
–>
-
Key Benefits
Features Advantages Benefits FedShard
Patented horizontally sharding and federation for scalable Knowledge Graphs
Query Results from each machine are combined so that the query process appears as if only one database is being accessed, although many different databases and data stores and knowledge bases are actually being accessed and returning results - Highly Scalable Entity – Event approach for Knowledge Graphs
- Speeds Complex Queries
- Unique data federation capability accelerates results for highly complex queries across highly distributed data sets and knowledge bases
Entity – Event Knowledge Graphs
New data model approach that unifies typical enterprise data with knowledge bases such as taxonomies, ontologies, industry terms and other domain knowledge.
AllegroGraph’s Entity – Event Data Model puts core ‘entities’ such as customers, patients, students or people of interest at the center and then collects several layers of knowledge related to the entity as ‘events’. - Organizations gain a holistic view of customers, patients, students or important entities and the ability to discover deep connections, uncover new patterns and attain explainable results.
- Events represent activities that transpire in a temporal context
- FedShard designed to facilitate a highly scalable Entity – Event approach
RDF/RDFS/JSON-LD
W3C (World Wide Web Consortium) industries Standards Standards based graph data and schema exchange format for interoperability.
Standards basis enables interoperability and easy data exchange while maintaining data structure. Proprietary graph solution like Neo4j can’t exchange data and retain intelligence - Allows applications to remain flexible and easily/incrementally adapted to new and rapidly changing business needs.
- Seamless interoperability with public – private data sources.
- Supports the needs of unstructured and structured data to allow applications to reflect real world data sources.
- No Vendor lock-in.
SPARQL
W3C (World Wide Web Consortium) industries Standards Standard query language – for building complex, semantic queries
Standards basis enables transportability, large network of people know SPARQL, easier paths of migration, greater integration to other data query methods. Proprietary graph solutions like Neo4j have immature, proprietary query forms. - Built for and optimized to support unstructured, semi-structured and structured data queries.
- Easily spans multiple, public and private data sources to enable new and unique business queries and analytics.
- Works well with unpredictable, unreliable and changing data sources.
- Excellent at answering questions when relationships have to be used to answer queries.
- No Vendor lock-in.
Hypergraph – Property Graph Permits
Hypergraph – Property Graph Permits greater flexibility, performance and accuracy than simple Property Graph models in representing complex, real-world data relationships.
More comprehensive data representation enables a broader range of queries that better match the real world, more complex, more efficient. Simple property graphs are a limited data representation - Enables better and more accurate representations of real world information that results in faster and more accurate results.
- Greater flexibility in the creation of applications.
- Faster, higher value query results that relate better to business issues.
- No Vendor lock-in.
Advanced Queries
- Geospatial
- Temporal
- Social Networking
Combined query with simultaneous geo-spatial, temporal, social network analytics.
Better represent the real world and to answer queries that are impossible with relational databases and difficult with Hadoop. Optimized for complex semantic queries. Enables the concept of Events that have: - Locations
- Timeframes
- Relationships of People
- Activities
Better represent the real world and to answer queries that are impossible with relational databases and difficult with Hadoop.
Linked Open Data
Standard for data linking and exchange
Standards basis enables interoperability with data sources inside and out of the enterprise. Proprietary graph solutions like Neo4j can’t link. Provides the ability to link to the data elements of 1,000s of publically published, extremely rich, topic specific semantic graph databases to enhance and enrich an existing graph database. Reasoning Ontologies
W3C Industry Standard
OWL/SKOS for reasoning and inferencing – provides organization and structure to represent the knowledge in and about the data and metadata.
Standards basis for ontologies enables shared, compatible integration of other and multiple ontologies. Proprietary graph solutions like Neo4j can’t take - Flexibility to leverage existing ontologies for agility, speed and reduced cost of application development.
- Creates new insight via existing information.
- Implicit and standards based interoperability simplifies development
- Enables a single, unified virtual view across multiple repositories with structured or semantic schemas.
- Eliminates need for point-to-point integration thereby reducing costs, speeding time to develop, reducing development risk.
- Establishes a common semantic meaning across disparate systems to allow federated queries.
Better represent the real world and to answer queries that are impossible with relational databases and difficult with Hadoop.
ACID Database model
Simple graph systems, and NoSQL systems do not adhere to the full transactional ACID model and data integrity. Mission critical applications require 100% transactional integrity, and recoverability from interruptions. By providing a full ACID compliant transactional database model, AG is resilient and can work in any enterprise class application. Rules and logic
Support industry standard Prolog
Powerful rules language enables advanced integration to support complex queries. Allows for advanced business rules to support complex decision support and to more accurately build predictive systems that reflect the real world. Magic Predicates
Predicates can be defined by computed variables based upon formulas or conditional logic
Complex data requires flexibility to perform complex queries. Allows for a better representation of real world subtilize in the processing of complex data for more accurate predictions. Flexible APIs
Java, Python, C#, Ruby, Perl, Lisp, Clojure/Scala
Provides open language access to handle custom development and integration needs Complex applications need access to the core AG engine to String support
Unlimited data element length to enable support of lengthy URLs/URIs.
Creates greater flexibility in designing systems, especially when federation of queries across multiple databases is needed. Without this feature, other systems are limited in reference to data. No limit to length of URI references so easier to build real world applications. Dereferenceable URI
Nodes in the graph database can be data or can point to data external to the core graph database in an enterprise or information located on the Web.
Creates greater flexibility in designing systems, especially when linking external data sources and federation of queries across multiple databases is needed. Without this feature, other systems are limited in reference to data. - Expands the reach of graph data to external data and sources which greatly increases the value and flexibility of solutions built on the platform.
- Leverages the entire Web as informational sources to be linked to by the graph database.
- Substantially enhancing the practical use and value of information.
Enterprise Platform
Very mature platform – Enterprise scale, ACID, commit, roll-back, checkpoint, replication, warm standby, triple level security model, SMP, Cloud enabled, auditing
Mission critical business applications require enterprise features for ongoing operations, high availability, security, scalability. - Analytics based upon graph databases have become mission critical to the daily business operations. Graph databases therefore, require enterprise class database features to be robust, reliable and for high availability.
Cloud and on-premise licensing
AllegroGraph can run locally, or can be run from the Amazon Web Services (AWS) scalable cloud
Flexibility to run AllegroGraph in the form that fits the business and technical needs. - On-premise allows clients with sensitive data to keep work completely behind their firewalls.
- AWS provides a fast and incrementally economical subscription pricing.
- AWS provides quick and easy scalability, so projects can ramp up on demand.
Predictive Analytics
Analyzing and predicting via highly complex data across multiple data bases
The combination of graph, semantics, rules/logic, inferencing, BBN, Geospatial/Temporal/SNA provide a uniquely powerful predictive analytics platform. - Predictive Analytics have become mission critical to the daily business operations. Semantic Graph databases can provide advanced analytics un-achievable with any other technology.
Event support
Support for events that combine geo-spatial, temporal, rules and machine learning
Can answer queries that are unanswerable with traditional graph, NoSQL and Relational DB technology Complex business problems require sophisticated ability to model the real world and real-time events. -
New Features
Key capabilities in AllegroGraph 8 include:
Neuro-Symbolic Platform
The unique combination of a Knowledge Graph (AllegroGraph), VectorStore, and deep LLM integration offers the industry’s first Neuro-Symbolic AI Platform. By combining AllegroGraph’s built in Symbolic AI Reasoning System with these new features, engineers can achieve unparalleled levels of AI-driven insights and decision-making. ‘Neuro-Symbolic’ describes the possibilities created by linking neural-network LLM technology with classical AI symbolic reasoning features including graph search, RDFS++, and PrologLLM Integration
AllegroGraph, guides Generative AI content through retrieval augmented generation (“RAG”), feeding LLMs with the ‘source of truth.’ This Knowledge Graph plus LLM approach helps avoid ‘hallucinations’ by grounding the output in fact-based knowledge. As a result, organizations can confidently apply these insights to critical decision-making processes, secure in the knowledge that the information is both reliable and trustworthy.VectorStore and Generation
Tools in AllegroGraph allow embedding natural language text into a vector representation. Allegrograph’s integrated VectorStore associates embeddings with literals found in the triple objects of a graph database. AllegroGraph also stores the subject and predicate of each triple whose object was embedded. This permits a mapping from literals to subject URIs in support of nearest-neighbor matching between an input string and the embedded object literals as shown in the example below.Semantic Entity-Event Data Modeling
Big Data predictive analytics requires a new data model approach that unifies typical enterprise data with knowledge bases such as taxonomies, ontologies, industry terms and other domain knowledge. The Entity-Event Data Model utilized by AllegroGraph 7 puts core ‘entities’ such as customers, patients, students or people of interest at the center and then collects several layers of knowledge related to the entity as ‘events’. The events represent activities that transpire in a temporal context. Using this novel data model approach, organizations gain a holistic view of customers, patients, students or important entities and the ability to discover deep connections, uncover new patterns and attain explainable results.FedShard™ Speeds Complex Queries
Through a patented in-memory federation function, the results from each machine are combined so that the query process appears as if only one database is being accessed, although many different databases and data stores and knowledge bases are actually being accessed and returning results. This unique data federation capability accelerates results for highly complex queries across highly distributed data sets and knowledge bases.Large-scale Mixed Data Processing
The AllegroGraph big data processing system is able to scale massive amounts of domain knowledge data by efficiently associating domain knowledge with partitioned data through shardable graphs on clusters of machines. AllegroGraph 7 efficiently combines partitioned data with domain knowledge through an innovative process that keeps as much of the data in RAM as possible to speed data access and fully utilize the processors of the query servers.Browser-based Gruff
Gruff’s powerful query and visualization capabilities are now available via a web browser and directly integrated in AllegroGraph 7. Gruff is the industry’s leading Knowledge Graph visualization tool that dynamically displays visual graphs and related links. Gruff’s ‘Time Machine’ provides users with an important capability to explore temporal connections and see how relationships are created over time. Users can build visual graphs that display the relationships in graph databases, display tables of properties, manage queries, connect to SPARQL Endpoints, and build SPARQL or Prolog queries as visual diagrams. Gruff can be downloaded separately or is included with the AllegroGraph v7 distribution.High Performance Big Data Analytics
AllegroGraph delivers high performance analytics by overcoming data processing issues related to disk versus memory access, uses processor core efficiency and updates domain knowledge databases across partitioned data systems in a highly efficient manner. -
High-performance Storage
AllegroGraph, a purpose built (not a modified RDBMS), Graph Database has continually driven innovation in the marketplace. The AllegroGraph product line has always pushed the performance envelope starting with version 1.0 in 2004, which was the first product to claim 1 billion triples loaded and indexed using standard x86 64-bit hardware. Our 2008 SemTech conference example of 10 billion quads loaded on Amazon’s EC2 service was the first to run a triplestore of that size in the cloud. In 2011, AllegroGraph was the first to achieve the load/process/query of 1 Trillion Triples.
AllegroGraph versions 5 and 6 continued to lead the industry with new features (GeoTemporal Reasoning, MongoDB integration, JSON-LD, n-dimensional Geospatial, Triple-Level Security, and much more) that others have tried to adopt with limited success.
The AllegroGraph 7 series offered yet another industry breakthrough technology that makes Entity – Event Knowledge Graphs not only possible but highly scalable through our patented FedShard™ Feature.
AllegroGraph 8 once again breaks new ground by adding deep LLM integration, Vector Storage/Generation, and rule-based reasoning for the industry’s most complete Neuro-symbolic platform.
Load Test # of Triples Time Load Rate/Sec LUBM 8000
1.106 Billion
30 min, 39 sec
601,414
Amazon – r5.8xlarge (32 vcpu/256GB RAM)
-
Architecture
AllegroGraph provides a REST protocol architecture, essentially a superset of the RDF4J HTTP Client. Franz’s staff directly supports adapters for various languages, RDF4J Java, RDF4J Jena, Python using the RDF4J signatures, and Lisp. There are Open Source Adapters through community projects for C#, Ruby, Clojure, Scala, and Perl. Links to download here.
The following diagram shows the building blocks of the system:
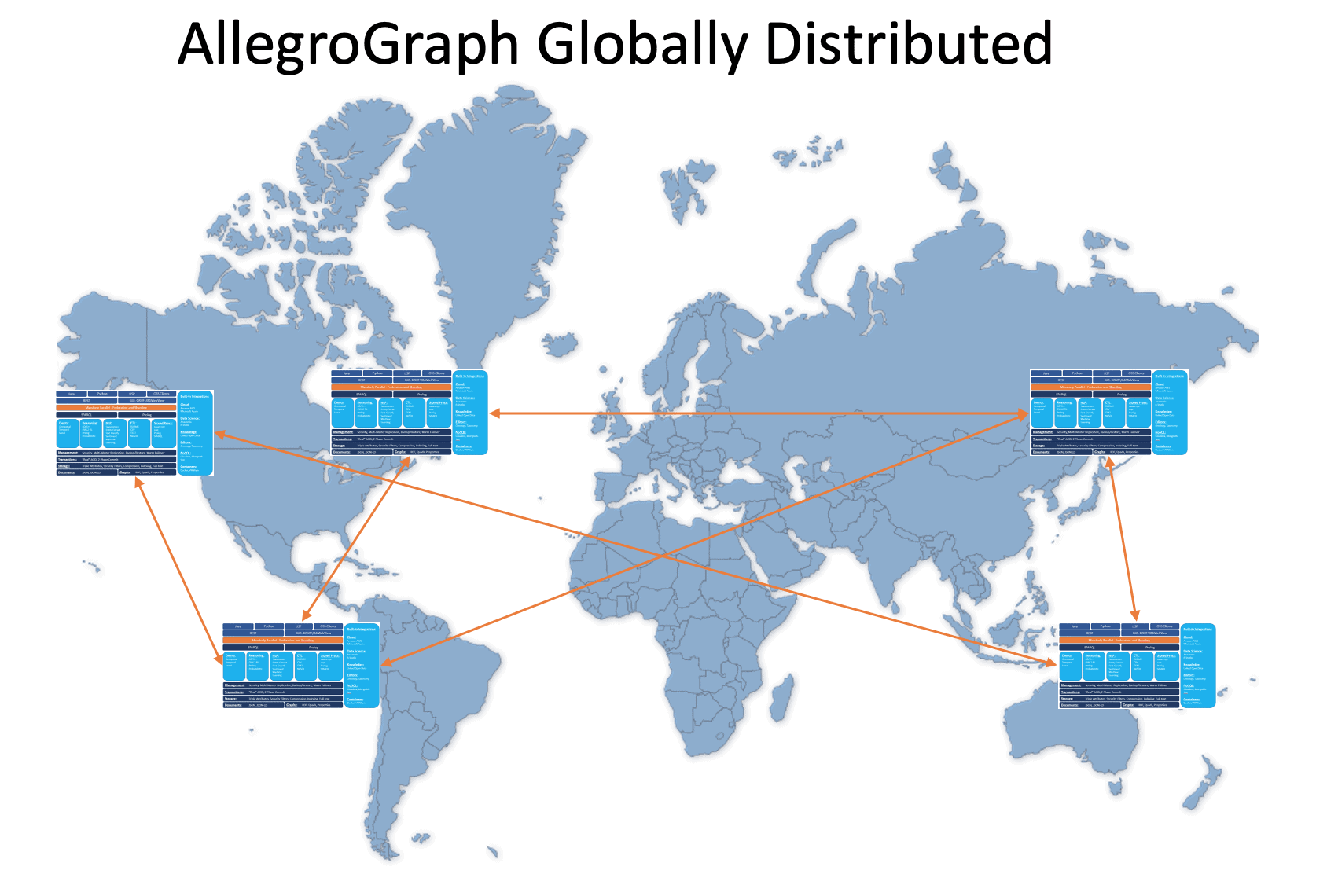
AllegroGraph can be run on multiple servers in widely separated locations:
Handling Very Large Datasets with Distributed AllegroGraph using our FedShard™ technology
For very large datasets which are not practical to store in a single repository or even on a single server, AllegroGraph has the FedShard™ feature, where general data is broken into shards based on some classifying criterion, like all data relating to a specific patient in a hospital or a specific customer in a bank. Additionally, knowledge-base data (medical knowledge for hospitals, for example) is stored in one or more separate databases. Queries are then run on federations of shards and knowledge-base repositories. This unique data federation capability accelerates results for highly complex queries across highly distributed datasets and knowledge bases.
The following image shows how this works:
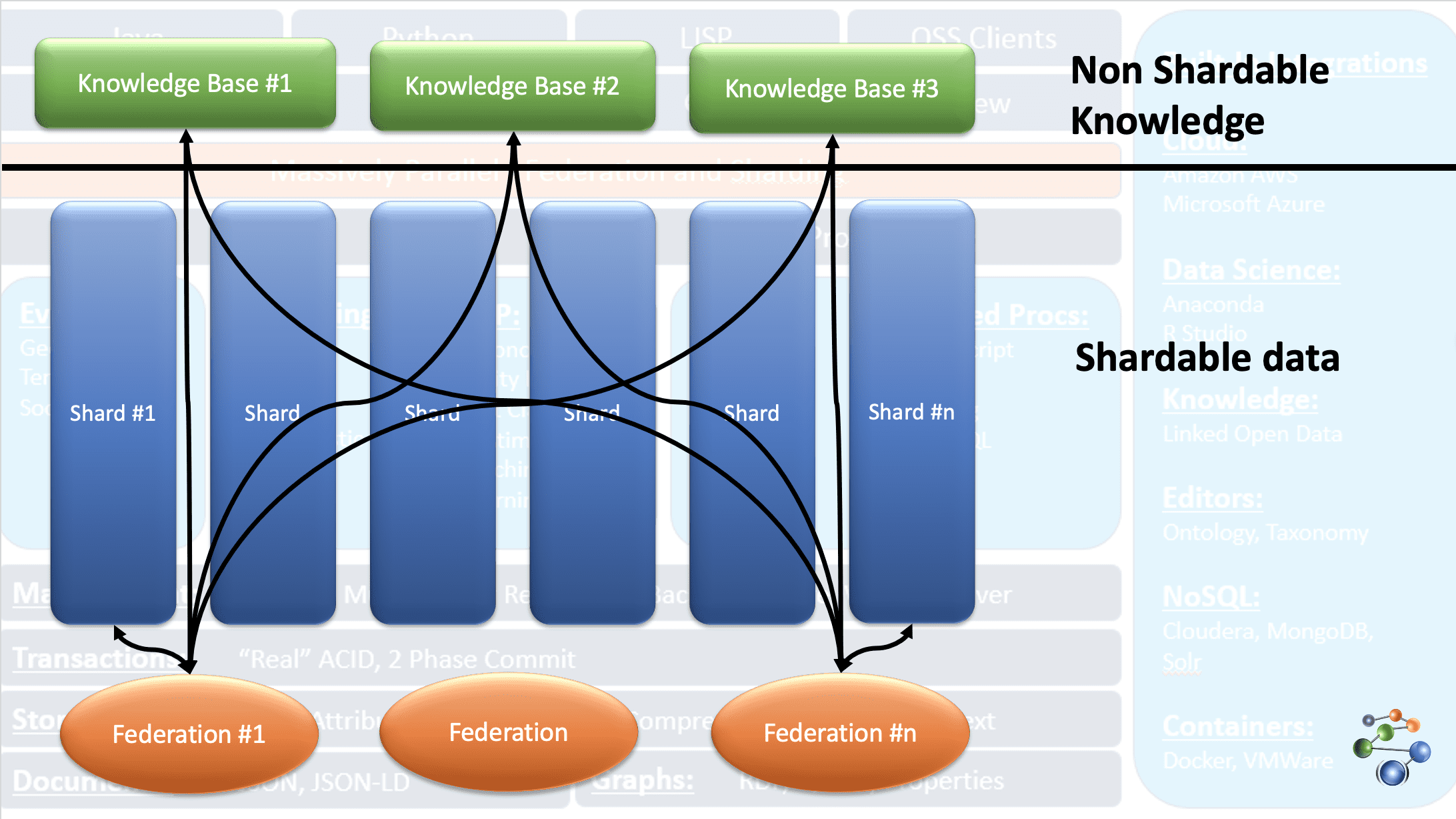
The three Knowledge Base repos at the top contain unshardable knowledge bases needed for all queries. The Shards below contain partitionable data. Each of the shards is federated with all knowledge bases. Queries are run in parallel on each of the federations. The black lines show how each shard is federated with the knowledge bases.
The shards need not reside in the same AllegroGraph instance, and indeed need not reside on the same server, as this expanded images shows:
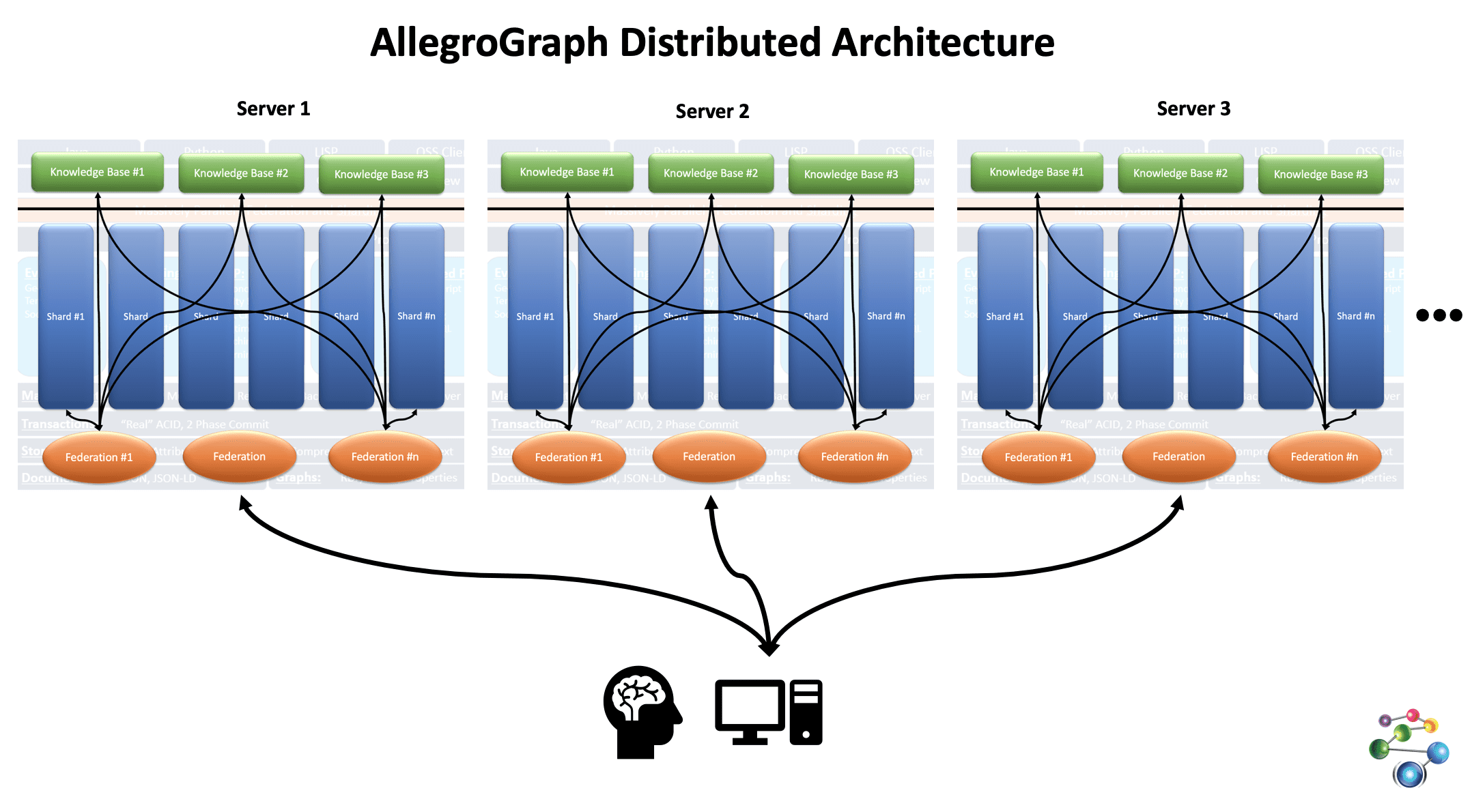
The Distributed Repositories Using Shards and Federation Tutorial has a fully worked out example showing how very large datasets of patient data can be broken into shards which reside on different AllegroGraph servers but are combined using AllegroGraph’s FedShard™ capability to provide fast query results.
-
Powerful and Expressive Reasoning and Querying
AllegroGraph provides the broadest array of mechanisms to query and access knowledge in an RDF datastore:
RDFS++ Reasoning – Dynamic Materialization
Description logics or OWL-DL reasoners are good at handling complex ontologies. They tend to be complete (give all the possible answers to a query) but can be totally unpredictable with respect to execution time when the number of triples increases beyond millions. AllegroGraph offers a very fast and practical RDFS++ reasoner.We support all the RDF and RDFS predicates and some in full OWL. The supported predicates are RDF:type, RDFS:subClassOf, range, domain, subProperty.
OWL:sameAs inverseOf, TransitiveProperty, hasValue, someValuesFrom, allValuesFrom, one of, equivalentClass, restriction, onProperty, intersectionOf.
AllegroGraph’s RDFS++ engine dynamically maintains the ontological entailments required for reasoning: it has no explicit materialization phase. Materialization is the pre-computation and storage of inferred triples so that future queries run more efficiently. The central problem with materialization is its maintenance: changes to the triple-store’s ontology or facts usually change the set of inferred triples. In static materialization, any change in the store requires complete re-processing before new queries can run. AllegroGraph’s Dynamic Materialization simplifies store maintenance and reduces the time required between data changes and querying.
OWL2 RL Materialized Reasoner
AllegroGraph’s OWL2 RL materializer uses a set of inference rules to generate new triples and adds them to the database. OWL 2 RL is the subset of OWL 2 that is designed to support rule based reasoners. OWL 2 RL contains a large number of rules for generating triples and some rules for verifying that the triple store is consistent with respect to the OWL 2 RL ontology. The OWL2 RL materializer is best when OWL 2 RL inference is required or the store is relatively static.SPARQL Queries on Named Graphs
SPARQL, the W3C standard RDF query language, returns RDF, XML and other formats in responses to queries. AllegroGraph’s SPARQL, one of the W3C’s “interoperable implementations”, includes a query optimizer, and has full support for named graphs. It can be used with the RDFS++ reasoning turned on (i.e., query over real and inferred triples). SPARQL can be used with every available AllegroGraph interface mentioned in the previous section.Prolog
AllegroGraph’s RDF Prolog provides concise, powerful, industry-standard, domain-specific reasoning to build high-level concepts (that require complex rules or numerical processing) on top of RDF data. AllegroGraph Prolog is an option because many use cases are difficult (or very cumbersome) to model with only RDF/RDFS and OWL. Prolog can also be used on top of the RDFS++ reasoner as a rule based system.Low-level APIs Allow fast, ‘close-to-the-metal’ access to triples by subject, predicate, and object.
-
Geo-spatial, Temporal and Social Network Analysis
Geospatial and Temporal Reasoning
AllegroGraph stores geospatial and temporal data types as native data structures. Combined with its indexing and range query mechanisms, AllegroGraph lets you perform geospatial and temporal reasoning efficiently.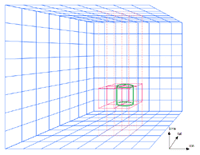
Social Networking Analysis
AllegroGraph includes an SNA library that treats a triple-store as a graph of relations, with functions for measuring importance and centrality as well as several families of search functions. Example algorithms are nodal-degree, nodal-neighbors, ego-group, graph-density, actor-degree-centrality, group-degree-centrality, actor-closeness-centrality, group-closeness-centrality, actor betweenness-centrality, group-betweenness-centrality, page-rank-centrality, and cliques. Geospatial and temporal primitives combined with SNA functions form an Activity Recognition framework for flexibly analyzing networks and events in large volumes of structured and unstructured data. -
Other powerful features
Native Data Types and Efficient Range Queries
AllegroGraph stores a wide range of data types directly in its low level triple representation. This allows for very efficient range queries and significant reduction in triple-store data size. With other triple-stores that only store strings, the only way to do a range query is to go through all the values for a particular predicate. This works well if everything fits in memory; but if the predicate has millions of triples, it will need costly machines with huge amounts of RAM. AllegroGraph supports most XML Schema types (native numeric types, dates, times, longitudes, latitudes, durations and telephone numbers).Free-text Indexing
AllegroGraph supports free-text indexing on the objects of triples whose predicates have been registered for indexing. Once indexed, triples can be found using a simple but robust query language. Free-text indexing support includes functions to register predicates and see which predicates are registered. Support for Solr was added in AllegroGraph version 4.5Named Graphs for Weights, Trust Factors, Provenance
AllegroGraph actually stores quints. A triple in AllegroGraph contains 5 slots, the first three being subject (s), predicate (p), and object (o). The remaining two are a named-graph slot (g) and a unique id assigned by AllegroGraph. The id slot is used for internal administrative purposes, but can also be referred to by other triples directly.The W3C proposal is to use the ‘named-graph’ slot for clustering triples. So for example, you load a file with triples into AllegroGraph and you use the filename as the named-graph. This way, if there are changes to the triple file, you just update those triples in the named graph that came from the original file. However, with AllegroGraph, you can also put other attributes such as weights, trust factors, times, latitudes, longitudes, etc, into the named graph slot.Direct Reification
AllegroGraph allows triple-ids to be the subject or object of another triple. This is beyond the scope of pure RDF. The advantage of this approach is that you can reduce the total number of triples in the store to a more manageable size, and, even more importantly, dramatically reduce query time because a single query can retrieve more data.Automatic Resource Management
The AllegroGraph architecture is designed to maximize hardware resources for all data management procedures (Loading, Indexing, Query, etc.). The hardware utilization can be managed through the AllegroGraph configuration file as necessary.Dynamic and Automatic Indexing
Triple-indices are user configurable, or index management can be taken care of entirely by AllegroGraph. By default, all committed triples are always indexed (default: 7 indices). AllegroGraph now supports any index combination of S, P, O, G. The default indices are:* S, P, O, G, I – Subject, Predicate, Object, Named Graph, ID
* P, O, S, G, I
* O, S, P, G, I
* G, S, P, O, I
* G, P, O, S, I
* G, O, S, P, I
* I
-
Compatible Technologies
Databricks (Delta Lake)
Databricks is a popular choice for hosting lakehouses – a new architecture that unifies data storage, analytics, and AI on one platform. AllegroGraph provides quick semantic layer integration with Databricks transparently through our advanced VKG (virtual knowledge graph) interface. Learn how to load RDF triples directly from your Delta Tables that are hosted in Databricks. Visit our Github example page to learn more.Apache Kafka
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. AllegroGraph as an entity-event knowledge graph will accept incoming events, do instant queries and analytics on the new data and then store events and results. Visit our Github example page to learn more.Apache Spark
Apache Spark is one of the most popular platforms for large-scale data processing. In addition to machine learning, SQL database solutions, Spark also comes with GraphX and GraphFrames two frameworks for running graph compute operations on your data. Visit our Github example page to learn how to read data from AllegroGraph and then perform graph analytics with Spark.Kubernetes
Kubernetes is an open-source container orchestration system for automating software deployment, scaling, and management. Visit our Github example page to learn how to run a Multi-Master Replication cluster (MMR) inside Kubernetes using the Helm package manager to perform the installation.Pool Party
Pool Party is a world-class semantic technology suite that offers sharply focused solutions to your knowledge organization and content business. Pool Party is the most complete semantic middleware on the global market. Use it to enrich your information with valuable metadata. Let it link your business and content assets automatically. Pool PartyGruff
Gruff is a visualization and query tool for Enterprise Knowledge Graphs. Gruff displays visual graphs and has an interface to build SPARQL or Prolog queries as visual graphs. Gruff can also display tables of all properties of selected resources or generate tables with SPARQL queries, and resources in the tables can be added to the visual graph. For details see Gruff -
System Requirements
The AllegroGraph Database Server runs natively on Linux x86-64 and is available at AllegroGraph.cloud, direct downland for on-premise, or in the AWS or Azure Marketplace.
For Windows and Mac we provide a few options:
- Use AllegroGraph.cloud
- Use Docker and the AllegroGraph image on Docker Hub.
- Install a Linux Virtual Machine (for non-performance experiments). We provide a Virtual Machine image on our Download page or you can create your own.
- Run Windows Subsystem for Linux (WSL) on Windows 10.
-
Benchmarks