Introduction
AllegroGraph Multi-master Replication (MMR) is a real-time transactionally consistent data replication solution. It allows businesses to move and synchronize their semantic data across the enterprise. This facilitates real-time reporting and disaster recovery.
It also allows load balancing over several essentially identical servers with (allowing for minor update timing differences) identical repos. Availability is also enhanced significantly because work can be done by any of the multiple servers so if any are unavalible for whatever reason, others can be used. See the High Load and Availability section below for more information.
Single repositories can be replicated as desired. The replicas each run in an AllegroGraph server. A single server can serve multiple replicas of the same repository (this is not typical for production work but might be common in testing). Note if there are multiple replicas in a single server, each replica must either be in a different catalog or must have a different name.
The collection of servers with replicas of a particular repository is called a replication cluster (or just cluster below in this document). Each repository in the cluster is called an instance. One instance is designated as the controlling instance, which will be described in more details below.
Each instance in the cluster can add or delete triples and these additions and deletions are passed to all other instances in the cluster. How long it takes for instances to synchronize depends on factors external to AllegroGraph (such as network availability and speed and whether the other servers are even available) but given time and assuming all instances are accessible, after a period of no activity (no additions or deletions) all instances will become synchronized.
High Load and High Availability
The two most important use cases for AllegroGraph Multi-master Replication are high load and high availability configurations.
A high load use case is a scenario when AllegroGraph server must be able to respond, without significant performance impact, to a higher number of concurrent requests that can be handled by the resources of a single machine. AllegroGraph provides fast data ingestion speed and high query performance, but an AllegroGraph server running on a single machine will always be limited by the resources of that machine. While vertical scaling (that is, upgrading to a more powerful machine) can be good enough for hundreds of concurrent requests, it may not be enough for thousands.
A high availability use case is a scenario when AllegroGraph must be able to respond to requests at all times. Generally, High Availability (HA) refers to a system's ability to be accessible close to 100% of the time. High Availability by definition can only be achieved by having multiple instances of the same service, preferably in different physical locations to provide protection against local problems, such as network outages, power outages or even natural disasters.
AllegroGraph Multi-master Replication allows to set up a cluster of AllegroGraph servers containing multiple copies (replicas) of the same repository, and changes to the contents of any of the replicas get propagated to all the other ones in the cluster. Both modifying and querying data can be done on any of the replicas. Even if the contents of the repository are being changed quickly, all the changes will still eventually appear in each of the replicas.
In order to achieve both high load readiness and high availability, AllegroGraph MMR cluster can be combined with a load balancer service that can automatically dispatch requests to one of the available nodes in the cluster.
With a load balancer, high load is spread across all the machines in the cluster, thus horizontally scaling the available processing resources. Such a configuration also eliminats a single point of failure: if any of AllegroGraph servers stops responding for any reason, the load balancer service can detect this and redirect all the traffic to any of the other nodes in the cluster, until the problematic server gets back online and synchronizes with the rest of the cluster.
Examples of using MMR with load balancing (NGINX or Amazon's Elastic Load Balancer) and infrastructure management systems (Kubernetes, Terraform) can be found on AllegroGraph examples on Github site. While these examples showcase concrete configurations, AllegroGraph MMR system is flexible enough to support a variety of other configurations so we do not discuss the details of any particular one here. That said, here are a few important things to consider:
AllegroGraph Multi-master Replication system provides eventual consistency. This means that changes to the contents of the repository are guaranteed to be propagated to the other replicas, but the propagation is not instant. In our experience, propagation rates can be anywhere from milliseconds and up to several seconds across data centers. So it is possible that an update is made on one instance, but a subsequent query gets dispatched to a different node in the cluster and does not see the update right away. See MMR Instance Settings for more details on how to control instance divergence. This limitation can be mitigated to an extent by using a load balancer service that supports session stickiness so that requests from the same client are likely to be dispatched to the same node in the cluster.
AllegroGraph allows authentication via bearer tokens, and supports both external OpenID Connect (OIDC) tokens and internal tokens generated by the server itself. While OIDC tokens will work on any of the servers in the MMR cluster provided that all the servers share have the same OIDC configuration, internal tokens for now only work on the server that generated them. This can also be mitigated to an extent by some kind of load balancer session stickiness.
AllegroGraph WebView relies on internal tokens for login sessions, so load balancer session stickiness (for example IP-based session stickiness) is required for AllegroGraph WebView to work with load balancer.
AllegroGraph sessions can cause issues with load balancers, since they are essentially direct HTTP connections to AllegroGraph server subprocesses. It is recommended to use the
UseMainPortForSessionsmode if sessions are used in a load-balanced configuration. See AllegroGraph Replication using NGINX Load Balancer example for a slightly more detailed explanation.When configuring high availability cluster, any HTTP API endpoint can be used as a liveness check. The examples linked above use the version HTTP endpoint for this purpose, but in some cases repository size endpoint might be a better test, since it guarantees the repository itself is operational, not just the server.
Secure transport of data
When a cluster is running each instance has two network connections (send and receive) to each other instance. By default these connections are not encrypted and that means that strings added to the repository will be visible to network snoopers. If you're storing sensitive data in strings and the network isn't secure then you should consider making the connections encrypted.
Each instance can choose to have transaction data sent to it encrypted with SSL/TLS. An instance can't choose whether to send encrypted data or not, that is up to the receiving instance. In order to ensure that transaction traffic is always encrypted all AllegroGraph servers hosting an instance of the cluster must choose to have MMR traffic sent to it encrypted.
In order for an instance to cause transactions sent to it to be encrypted the agraph.cfg file must include SSL directives and also specify SecureMMR as yes.
Setting up a multi-master cluster
Only superusers can convert a repository to a multi-master repo or can modify the configuration of such repos after creation. (Users with write permission can add and delete triples even if they are not superusers, of course.)
You can start multi-master replication cluster on a repository using AGWebView, using the agtool repl command, or using the REST interface. We will discuss using AGWebView and agtool repl in greatest detail.
A cluster is created either by using agtool repl create-cluster to create a new repository as a cluster instance (that operation cannot be done in AGWebView) or by starting with an initial instance of a repository (which may be an empty repository or may already contain triples) and then cloning it. The clones can be on the same server or on different servers.
When you convert an existing repository to a cluster instance, the repository must not be open. Both AGWebView and agtool repl create-cluster close the repository before conversion. If it is not possible for any reason to close the repository, the conversion will fail.
The cluster can be grown at any time by adding additional instances and it can be shrunk by removing instances.
The first step to setting up a multi-master cluster is to specify a repository in some catalog on some server as the first instance of a cluster. The repository must be an existing repository (which may have just been created for this purpose). Once it has been converted to be the first instance of a replication cluster, other instances can created and added to the cluster. (Existing repositories cannot be added to an existing cluster. Each instance added after the initial creation of a cluster will be newly created when added.)
Newly created instances can have their own names and can be in their own catalogs. So the initial instance can be named kennedy and be in the root catalog of server1, a second instance can be named kennedy-dup and also be in the root catalog of server1, a third named kennedy in the catalog mycatalog of server1, a fourth named kennedy in the root catalog of server2, and so on.
Ports for multi-master clusters
Each multi-master instance will start a network listener on a port within the range specified by ReplicationPorts in configuration file agraph.cfg (see Server Configuration and Control). If none were specified then the operating system will choose a random port. This port must be reachable from all other instances on all other machines that run instances of this cluster in the future. Generally ports chosen by the operating system work unless there are firewall restrictions.
Setting up a multi-master cluster using AGWebView
To create a multi-master replication cluster in AGWebView, you must start with an existing repository in the server connected to by the AGWebView screen. You can use an existing repository (that is not already part of any cluster) or you can create a new repository using the tool on the catalog page in AGWebView (the link is to the description of the Root catalog page).
In WebView you can create a new repo with the Create Repository button to the right on the repositories page.
There you will see repositories already existing in the catalog, along with tools to create a new ordinary repository and (unrelated to the discussion here) to start a session. Choose an existing repository to make the first instance of a cluster or create a new one for that purpose. We have a kennedy repository and we will use that one. Clicking on the repository name will take you to the repository overview page, described next.
Using AGWebView to convert a repository to a multi-master instance
Here is a portion of the Repository Overview:
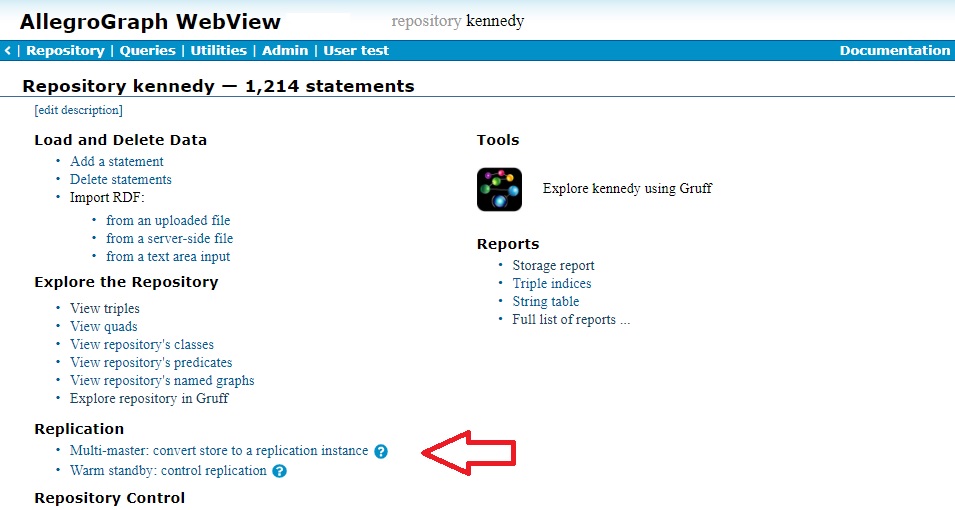
The red arrow points to the link Convert store to a replication instance. Clicking on this link displays the following dialog on the AGWebView page:
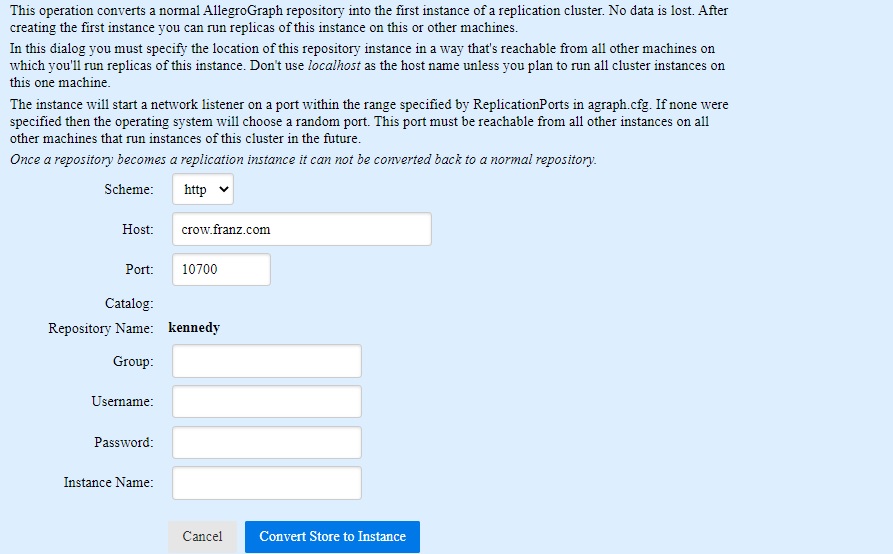
In WebView choose Replication in the Repositories menu to the left.
The information you will supply in the various fields identifies the instance being created and specifies how other instances will contact the new instance. You have to decide whether they will use HTTP or HTTPS, and what the host and port are. Just the Scheme, Host, and the Port fields will be filled in initially (we have filled in the remainder as an illustration). The fields are:
- Scheme
- http or https. If only one scheme is currently available on the server, only that choice will be available.
- Host
The server containing the repository which is to be made into the first instance of the new cluster runs on a specific host. That host is specified in this field and a suggested value is provided. The value must be specified in a way that allows access from any server that will contain a repository in the cluster. The value can be a hostname (such as the suggested
crow.franz.com) or an IP address. You should avoid the hostnamelocalhostas that will not work properly for access from other machines. (localhostcan be used when all cluster repositories will be in servers running on a single machine, which can be useful for testing but is unusual in production environments.)Because you are creating the first instance of a new cluster, the host must be the machine running the server in which the existing repository being converted resides, and the port must be a port on that machine which communicates with that server.
- Port
- The current port is filled in but you may wish to use another port (such as a port for HTTPS). The port shown is the one for the chosen scheme. If the scheme is changed, the port for it will be shown.
- Catalog
- This field as shown is not settable since the repository already is in some catalog (such as, in this case, the root catalog) and that cannot be changed by the conversion operation. (The dialog for creating a new instance is very similar but the catalog field is active in that dialog since the new repository instance can have a different name and be in a different catalog.)
- Repository Name
- This is filled in with the name of the repository being converted (
kennedyin this example). - Group
- If supplied, the new instance will be in the named group. Groups and the associated notion of priority are described in the section Repository priorities below. It is not necessary to include a repository instance in a group and this field can be left blank. Group names must be distinct from instance names.
- Username
- A username for a user who has permission to create multi-master replication (a superuser). This could be the current user as this dialog will not display for users without the necessary permission but the values must be filled in even if it is the current user.
- Password
- The password for
username. - Instance Name
- Each instance of a cluster must have a unique (to the cluster) name. (It will also have an instance ID number assigned by the system.) This allows easy reference to the instance. You can leave this field blank and the system will select a name.
When the form is filled in, click on the Convert Store to Instance button and the conversion will take place. The button will gray out and working will appear next to it. If the conversion is successful, the dialog will disappear.
Problem with encoded-ids. If the repository being converted has encoded id templates defined, the conversion can be done even if those templates do not allow for 2^60 unique identifiers but trying to get the next encoded upi for that prefix will fail. See Issues with encoded-ids below for more information.
The controlling instance
In a replication cluster, one instance is distinguished as the controlling instance. When a cluster is created, the first instance becomes the controlling instance. Later, control can be shifted to other instances.
Certain operations can only be done by the controlling instance. These special operations are those that if done simultaneously on multiple instances would cause conflicts to exist. These operations are:
Adding another instance to the cluster.
Removing an existing instance from the cluster.
Defining or deleting a triple attribute (see Triple Attributes)
Defining an encoded id.
You can change the controlling instance. This is typically done (using agtool repl or the WebView Replication Cluster Management page) by sending a command to the current controlling instance. Making the change this way ensures that only one instance believes it is the controlling instance. The exception is when the controlling instance is unavailable (because, for example, its server is down). Then another instance can be made the controlling instance but then, for a while at least, when the former controlling instance becomes available, there will be two instances thinking they are controlling. Care should be used when that situation occurs.
Controlling instance backups and MaximumBackupAge
When an instance is added to a cluster, it is populated with data from a backup of the controlling instance and is then further updated in the same way as other instances are updated. There is a background process which regularly checks the controlling instance backup and deletes it if it is older than MaximumBackupAge. The MaximumBackupAge configuration directive specifies how old a backup can be before it is considered stale (and deleted when the backup process checks) and also how often the backup process does its check.
A backup is stale if it is older than the MaximumBackupAge. If there is a request to make a new instance and the most recent backup is stale, a new backup will be created prior to the new instance being created and that new backup will populate the new instance. If a suitable (non-stale) backup exists, it will simply be used.
The system checks every MaximumBackupAge-in-seconds/4 seconds to see if a backup is stale, deleting it if so.
A small value for MaximumBackupAge may result in more backups. A large value will require the new instance to do more work to catch up with other instances after it is started.
The backups described in this section are for internal use as required by multi-master replication and are not related to user-created backups described in the backup-and-restore document.
Managing clusters in WebView once created

When a repository is an instance of a cluster, the linked command in the Multi-Master Replication section of WebView's Repository Overview page changes to Manage Replication Instances [as controller] (as controller only appears if the instance is the controlling instance, but the section appears, with at least a link to Manage Replication Instances on the repository pages for all instances in the cluster).
Clicking on the link takes you to the Replication Cluster Management page, shown (for a cluster with only one instance which is thus the controlling instance) below.
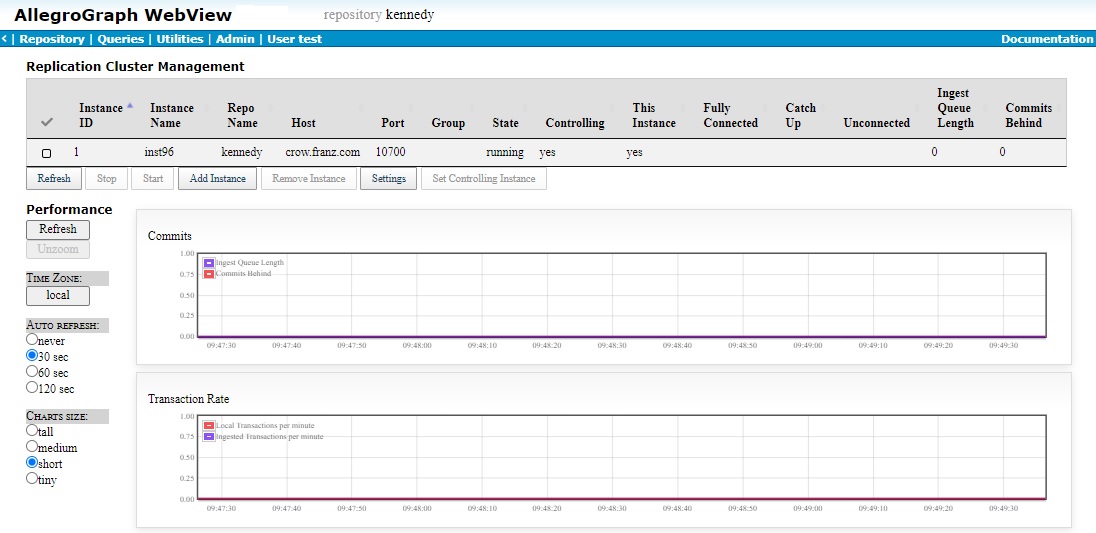
We will describe the various columns, buttons and graphs shortly, but first we add an instance by clicking on the Add Instance button. This dialog appears:
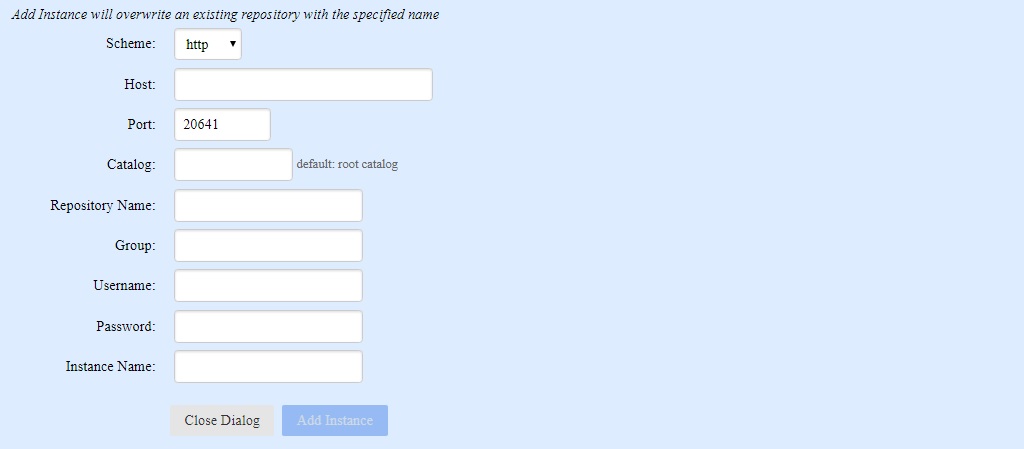
You fill in the various fields. Here are some notes:
- Host
- No suggested value is provided because the system has no way of knowing what host you want. The value should be a hostname or a IP address. Avoid
localhostunless all instances will be in servers running on the same host (not uncommon when testing but rare in production). - Port
- This field is filled in with the port used by the current server. Be sure to change this to be the port used by the target server. (The current server can host both instances if either their names or catalogs are different. More typically, instances are in different servers but in this example, we have all instances on the same server.)
- Catalog and Repository Name
- These can be different on the target server than on the current server. The catalog specified must exist on the target server (the root catalog, the default if no catalog is specified, always exists). The repository name can be the name of an existing repository, but (as the warning at the top says) that repository will in that case be destructively replaced with all its data being lost.
- Group
- If supplied, the new instance will be in the named group. Groups and the associated notion of priority are described in the section Repository priorities below. Some groups, created when other instances were created, may already exist. You can include this instance in an existing group, or in a new group, or in no group (leave this field blank if you do not want the instance to be in any group). Group names must be distinct from instance names.
The Instance Name must be a unique (in this cluster) name (the system will choose a suitable name if none is provided).
Username and Password must be for a user on the server identified by Host and Port who has superuser privileges.
We now have two cluster instances in two servers. The Replication Cluster Management table for the controlling instance now looks like this:
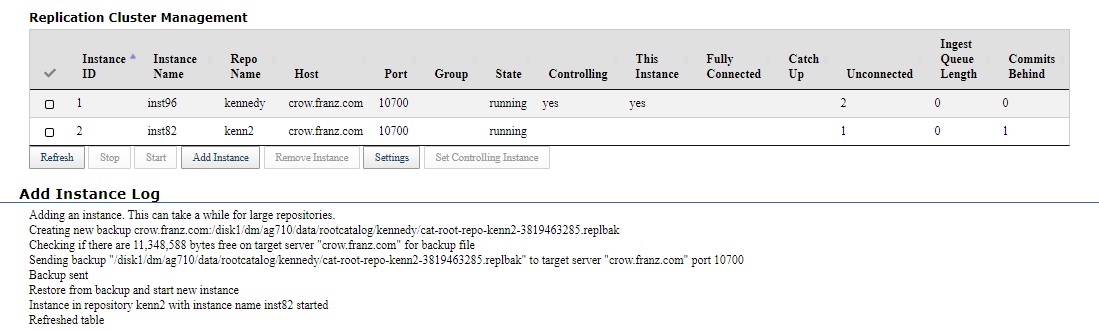
It shows the two instances. Below the instance table is a log describing recent actions, adding an instance in this case. The various steps are shown when completed. Problems, if any (none in this case) are also noted. The graphs are still below but have been left out of this picture.
The page for non-controlling instances looks like this:
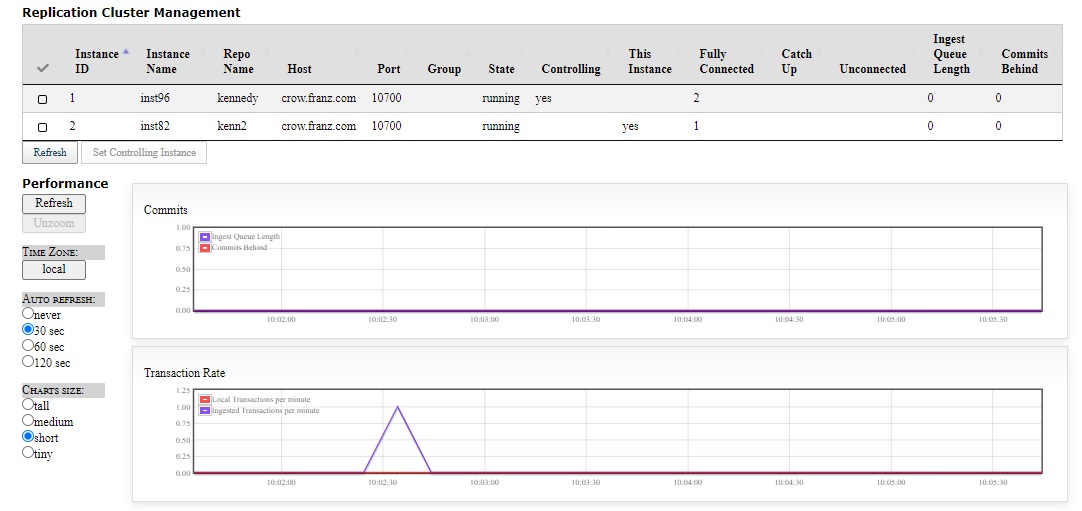
Note the Transaction Rate graph had a burst of activity when the instance was created.
The information table is similar in both cases but the controlling instance page has many control buttons while the non-controlling page has just two.
The columns in both are:
- Selection Tool (a check mark)
- If the checkbox in this column is checked, various button options become live and clicking the button affects the selected instances.
- Instance ID
- The value is the instance ID number assigned by the system to each instance.
- Instance Name
- The given name for each instance (chosen when the instance was created).
- Repository
- The repository name for the particular instance. (These are
kennedyandkenn2in the example.) - Host
- The host for the instance. (Both crow.franz.com in the example but more typically separate hosts.)
- Port
- The port on the host which communicates with AllegroGraph.
- Group
- The group of the instance, if any. Groups and the associated notion of priority are described in the section Repository priorities below.
- State
- The current instance state (running, unreachable, etc.) An instance is unreachable if it cannot be contacted. That can happen when the instance is stopped or when the machine or the AllegroGraph server on which the instance would run is itself not running.
- Controlling
- The controlling instance has 'yes' in this column. There is only one controlling instance. See below for information on the controlling instance.
- This Instance
- The WebView you are looking at is displaying information about a specific server. The instance identified in this column is the instance in that server.
- Fully Connected
- Lists (by instance ID number) the instances to which the instance in the row is fully, partially, or not connected.
- Catch Up
- Lists (by instance ID number) the instances which are catching up to the instance of the row. What it means for instance X to have instance Y listed as Catch Up is: (1) The required two connections have been established between X and Y; (2) One or both of the connections are in Catch Up mode (either X is trying to get Y's commits that X is missing or Y is trying to get X's commits that Y is missing, or both).
- Unconnected
- Lists (by instance ID number) the instances which are not connected to the instance of the row.
- Ingest Queue Length
- The number of commits this instance has collected that it must ingest.
- Commits Behind
- The information passed between instances tells how many commits an instance has initiated. If Instance1 tells Instance2 that it has initiated 100 commits and Instance2 has only seen 90 commits from Instance1, it calculates it is 10 commits behind. Adding all those as yet unseen commits from all instances to the ingest queue length gives this value. Note this value is always an estimate since information on commits is sent periodically and there may be additional commits by other instances since their last report.
What buttons appear below the table depends on whether the instance displaying the page is the controlling instance or not. See the illustrations above, where the controlling instance shows all the buttons and other instances show only two (Refresh and *Set Controlling Instance).
We describe the buttons for the controlling instance. Some affect the whole table and are thus always active. Others affect just one or more instances and so are inactive unless some instances are selected. The buttons are:
Refresh Always available. Refresh the displayed data. Also on non-controlling instance page.
- Stop
- Available when one or more instances are selected. Stop the selected instances. When an instance is stopped, data cannot be added or deleted from it and it will not receive commits from other instances. An instance is also stopped when its associated server is down or otherwise unavailable but this option stops the instance while leaving the server running.
- Start
- Available when one or more instances are selected. Restarts a stopped instance. A no-op if the instance is already running.
- Add Instance
- Always available. Allows adding a new instance. See Managing clusters in WebView once created above for details and an example.
- Remove Instance
- Available when one or more instances are selected. Removes the selected instances. The removed instances become regular repositories containing the triples they contained when removed. In the typical use case, removed repositories are then deleted but that is neither automatic nor required.
- Settings
- Always available. Displays a dialog showing the settings. See Instance Settings for more informaton.
- Set Controlling Instance
- Available when exactly one instance is selected. Makes that instance the controlling instance. A no-op when the selected instance is already the controlling instance. Also on non-controlling instance page.
The graphs
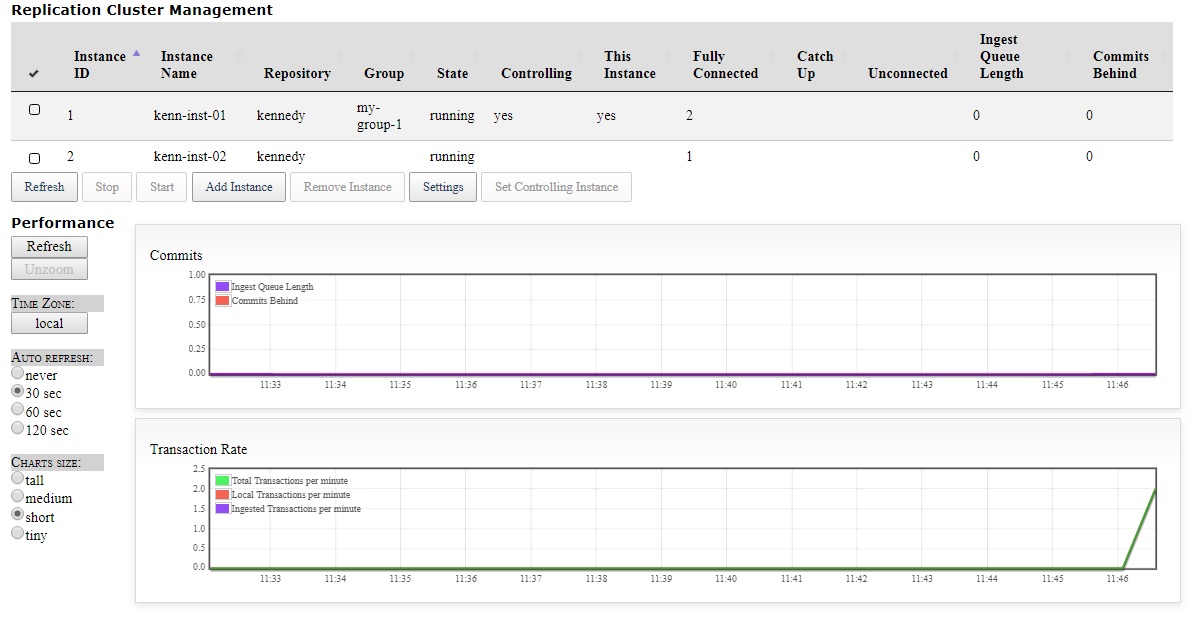
The two graphs at the bottom of the page provide information on activity. We added about 1200 triples so the transaction rate (lower graph) had a spike around 10:02. Otherwise the graphs show not much activity in the illustration. The various buttons on the left control graph behavior. Note the Time Zone button. It can toggle between the local time, the local time where the server is running, and UTC time (Universal Coordinated Time).
Values are graphed independently (rather than being stack one on top of the other). The Ingested Transctions value is the sum of the local transactions plus any transactions made on another instance and ingested on this instance.
Instance Settings
The several instances in a cluster are intended to be synchronized so they have the same set of triples but when instances are making commits which add or delete triples, the instances are unlikely to actually be identical. It takes time for information about triple additions and deletions to propagate around the various instances. Eventually (assuming the instances and the associated network are actually running) synchronization will occur, but how quickly depends on factors outside the scope of this document and perhaps outside your control.
You may want to ensure that instances do not diverge too much. The settings described here allow you to control instance divergence by preventing commits until instances are sufficiently synchronized.
Default values for these setting can be specified for a server in its configuration file agraph.cfg (see the section Top-level directives for multi-master replication clusters section of the Server Configuration and Control document). New clusters set up by a server will use those settings unless other settings are specified on cluster creation. Once a cluster is created, the settings can be changed by the controlling instance.
There are four settings, displayed in the dialog displayed when the Settings button is clicked on the Managing Clusters dialog for the controlling instance described in the Managing clusters in WebView once created section above.

The settings are
- Durability
The value can be one of three symbolic values,
min,quorum, ormax, or, as described below, a positive integer. The value specifies how many instances must have ingested a commit before the commit is deemed durable. When a transaction is committed in an instance, the commit propagates to other instances where it is ingested (i.e. committed). If commits do not become durable, then the ability to make further commits can be restricted, depending on the values of the other three parametes described in this section.The meanings of the symbolic values depend on the number of instances.
minalways means 1.maxalways means the number of instances.quorummeans the smallest integer larger than half the number of instances. Here are some examples:# of Instances Min Max Quorum ----------------------------------------------------- 1 1 1 1 2 1 2 2 3 1 3 2 7 1 7 4 10 1 10 6 11 1 11 6So if there are 10 instances, 1 commit makes a commit durable when
Durabilityismin, 10 when it ismax, and 6 when it isquorum.When the number of instances changes (because new instances are added or existing instances are deleted), the values associated with the
maxandquorumsymbolic values also change (minalways corresponds to 1). So if the number of instances is 10 and 3 instances are deleted so 7 remain,maxbecomes 7 andquorumchanges from 6 to 4. When a symbolic value is given forDurabiliity, there are always enough instances to make a commit durable.Durabilitycan also be a positive integer. When that number of instances ingest a commit, the commit becomes durable. This value should be less than or equal to the number of instances since if it is greater no commit can become durable. Be warned that if instances are deleted, a numeric value forDurabilitywill not change (as the numeric values associated withmaxandquorumchange). So, for example, if there are 10 instances andDurabiltyis 8, and then 3 instances are deleted (leaving 7), no subsequent commit can become durable.The default value for this setting in the server running the controlling instance is set by the
durabilityconfiguration directive. See the Top-level directives for multi-master clusters section in the Server Configuration and Control document. If not specified in the configuration file, this value defaults tomin.
- Distributed Transaction Timeout
A non negative integer. This is the number of seconds to wait for a commit to become durable. If durability is greater than 1, a commit initiated by an instance cannot complete until (durability - 1) other instances have indicated they have committed as well or until the timeout is reached. If the number of seconds specified by
Distributed Transaction Timeoutpasses before enough instances report they have committed, the original commit completes and control returns to the caller that initiated the commit.The default value for this setting in the server running the controlling instance is set by the
distributedTransactionTimeoutconfiguration directive. See the Top-level directives for multi-master clusters section in the Server Configuration and Control document. If not specified in the configuration file, this value defaults to 60 (seconds).
- Transaction Latency Count
This value along with Durability are the controls that the administrator has in determining the level of synchronization and coupling between the various instances in the cluster.
The Transaction Latency Count is the number of transactions that each instance will allow to be non-durable and still commit another transaction.
If the Tranaction Latency Count is 4 then even if the last four commits are not yet durable we can do one more commit. If when we go to commit again we find the last 5 commits are non-durable then the commit function will signal an error (but the error can be delayed by a positive value of Transaction Latency Timeout).
Another example: If the Transaction Latency Count is set to zero then each commit must be durable before the next commit can be done or an error is signaled.
The default value for this setting in the server running the controlling instance is set by the
transactionLatencyCountconfiguration directive. See the Top-level directives for multi-master clusters section in the Server Configuration and Control document. If not specified in the configuration file, this value defaults to 3.
- Transaction Latency Timeout
The value should be a non-negative integer indicating the number of seconds that the system will wait until the Transaction Latency Count is met. If the Transaction Latency Count is not met by the Transaction Latency Timeout, then an error will be signaled.
Commits cannot complete until they become durable (the number of instances commiting is at least the value of Durability) or until the Distributed Transaction Timeout number of seconds has passed. There may be several commits waiting to become durable. When Transaction Latency Count plus 1 commits are waiting to become durable, attempting an additional commit will signal an error.
The error, however, will not be signaled until
Transaction Latency Timeoutseconds have passed. If during that time, sufficient commits have become durable, the commits that exceed theTransaction Latency Countwill then proceed and (assuming the number of pending commits drops below Transaction Latency Count plus 1, no error will be signaled. If the number of pending commits remains above that value, an error will be signaled whenTransaction Latency Timeoutseconds have passed.You may want (particularly when testing and making large batch updates) to set this value to a large number, like 3600 (which is one hour) to avoid errors caused by, say, an overloaded test machine but still catch errors when the wait is so long that a more serious problem is indicated.
The default value for this setting in the server running the controlling instance is set by the
transactionLatencyTimeoutconfiguration directive. See the Top-level directives for multi-master clusters section in the Server Configuration and Control document. If not specified in the conifguration file, this value defaults to 0 (seconds).
Cluster operations you cannot do with WebView
There are certain cluster operations that cannot be done using WebView. Instead, you should use the agtool repl command interface. These things include
Quiesce the cluster (stop all commits until the cluster is in sync) (see agtool repl quiesce)
Set instance priorities (see agtool repl priority)
Specify the retention period of transaction logs (see agtool repl retain)
Using the agtool repl command
The agtool repl command can be used to create and manage multi-master clusters. agtool is the general command tool for AllegroGraph (see the agtool General Command Utility document).
The general form of the agtool repl command is
agtool repl COMMAND [ OPTIONS ] ... where COMMAND is one of:
- get-config - read the MMR configuration
- set-config - set the MMR configuration
- controlling-instance - Set the controlling instance of a cluster.
- create-cluster - Create the first instance of a cluster.
- grow-cluster - Add an instance to the cluster.
help- Display repl usage.- priority - Specify the priority for retrieving commits.
- quiesce - Control the coordination of replication in the cluster.
- remove - Remove an instance from the cluster.
- retain - Specify the retention period of transaction logs.
- settings - Set cluster parameters.
- start - Restart a stopped cluster instance.
- status - Get the status of an instance of the cluster.
- stop - Stop a cluster instance.
The SPEC argument to agtool repl
Most agtool repl commands take a SPEC argument that specifies the cluster instance to act upon. The form of this argument is
http(s):[//[USER:PASSWORD@]HOST[:PORT]][/catalogs/CATALOG]/repositories/REPO Example:
http://test:xyzzy@host:43160/repositories/my-repo The user is test with password xyzzy, and the repo is my-repo on host host listening on port 43160. This repository is in the root catalog (the default so no catalog is specified). The scheme is http.
Using agtool to read the configuration
This function is only available to a super user.
The current MMR configuration is printed by
agtool repl get-config SPEC where SPEC must be the controlling instance of the cluster. The configuration is printed in lineparse format.
You can edit the configuration and make it the MMR configuration with
agtool repl set-config SPEC FILENAME Where SPEC is the controlling instance of the cluster.
This is a very powerful operation and can be dangerous as well. The cluster configuration uploaded is quickly distributed to all instances which then use it to reconnect to the cluster. Supplying incorrect information can make it impossible for instances to reconnect.
The best practice is to use the other agtool repl commands to reconfigure the cluster one step at a time (grow, delete, stop or start instances).
However there may be cases where, for example, you want to correct a typo in a password or machine name or completely change the user and password used on an instance. These would be ok.
You can not add an instance to the cluster by just adding an instance to the configuration. Only agtool repl grow-cluster can add an instance.
You can remove an instance from the cluster by removing the instance from the configuration however this will not stop the removed instance and it will continue to run trying to connect to the cluster. So it's best to use agtool to stop the instance before removing it this way (or better yet use agtool itself to remove the instance rather than uploading a new configuration).
Using agtool to set the controlling instance
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl controlling-instance usage is
agtool repl controlling-instance [ OPTION ] ... SPEC INSTANCE_NAME Options are --force (force operation to complete even if all requirements are not met) and -v/--verbose (more verbose output). SPEC is as described above and must specify the controlling instance of the cluster. The instance name (in the cluster) must be included and cannot be the controlling instance name. INSTANCE_NAME can be the name or a SPEC value denoting the instance to become the controlling instance. If the controlling instance is down, INSTANCE_NAME must be a SPEC value denoting the instance to become the controlling instance and --force should be specified.
Using agtool to create a cluster
This can also be done in WebView but using a somewhat different sequence of commands (see the note below and see Using WebView to convert a repository to a multi-master instance. The agtool repl create-cluster usage is
agtool repl create-cluster [ OPTION ] ... SPEC [ INSTANCE_NAME ] Options are
--group(see below)-v/--verboseif supplied, causes more verbose output--if-existsif supplied, specifies what to do when the repo to convert already exists. See below for details.--forceif supplied with valuetrue, forces the conversion of an existing repo to a multi-master instance even if there are unsuitable encoded id templates. See below for details.
SPEC is as described above. The instance name (in the cluster) can be included. An instance name will be assigned if it is not specified. The instance will become the first instance of the cluster and hence the controlling instance.
The --if-exists and --force options
The typical use of agtool repl create-cluster is to have it create a new repository as the first (and controlling) instance of a cluster. However, you can convert an existing repository to become the first instance of a cluster. To do so, specify use as the value of the --if-exists option.
The allowable values for --if-exists are:
supersede- Delete the existing repo and all its contents and recreate it with no contents as the first instance of the new cluster. Use the option with care. We recommend backing the repo up prior to superseding it.overwrite- Same assupersede.error- Signal an error of the repo specified bySPECexists. This is the default value.use- Use the existing repo with its contents as the first instance of the new cluster. See the section Issues with encoded-ids below for requirements on encoded ids defined in the repo.
If the system will not convert an existing repo when --if-exists use is specified because of encoded id problems (see Issues with encoded-ids below), you can force the conversion by specifying --force true:
agtool repl create-cluster --if-exists use --force true \
http://test:xyzzy@host:43160/repositories/my-repo will then convert the existing repo my-repo to be the first instance in a cluster whether or not there are issues with encoded ids.
The --group option
The group option can also be specified using WebView (see the description of converting a repository to the initial instance and the description of adding an instance above, where the dialogs used to convert or create instances have a Group field).
Cluster instances may be in a group but need not be, so --group need not be specified. Groups have names which identify them. Group names must be distinct from instance names. Since this is the first cluster instance, the group specified will be created with this instance as its first member. See priority below for information on how groups are used.
Issues with Encoded IDs
Encoded IDs can be used to generate unique URIs. The user registers a prefix template and then can call next-encoded-upi-for-prefix to get the new unique identifier. See the Encoded IDs document for more information.
In multi-master replication clusters, however, the prefix templates must specify exactly 2^60 different identifiers. (Outside of multi-master custers, prefix templates can specify fewer unique idenifiers.)
Consider an example similar to one in the Encoded IDs document:
[0-9]{3}-[a-z]{3}-[0-9]{4} That calls for [three digits]-[three letters]-[four digits], like 143-afg-0126. There are 10^326^310^4 = 175,760,000,000 unique identifiers. But 2^60 is 1,152,921,504,606,846,976, so that template will not work for calls to next-encoded-upi-for-prefix in a multi-master instance.
The special template "plain" simply runs through the integers from 0 to (2^60 -1) and is recommended if your goal is unique URIs. Other templates that work are:
[a-p]{15}
[0-7]{10}-[0-7]{10} Consider the first: there are 16 letters from a to p and the template is 15 letters long so there are (2^4)^15 = 2^60 possibilities.
Once a repository is an instance of a multi-master cluster, you can define new Encoded IDs with unsuitable templates but calls to next-encoded-upi-for-prefix will signal an error.
The mere existence of an inadequate template will not cause a problem, nor will using existing UPIs created before the repository became a cluster instance, just trying to create a new UPI with next-encoded-upi-for-prefix or its equivalents in other languages such as Java or using the REST interface.
Note that the required number of distinct strings generated by a template may change in future releases. The Release Notes will describe any the change should it occur.
Differences between creating a cluster with agtool and with WebView
When you create a cluster in WebView, you first create a repo and then convert it to a cluster repo. (You can have added triples before conversion, but you always start with an existing repository and its contents are unchanged by the conversion.) When you use agtool repl create-cluster, you are typically creating a new, empty repository as a cluster repo. You can use an existing repo like in WebView by specifying --if-exists use. Otherwise, if `SPEC' names an existing repo containing triples, the system will delete it and create a new, empty repo with the same name.
Using agtool to add an instance to a cluster
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl grow-cluster usage is
agtool repl grow-cluster [ OPTION ] ... SPEC TARGET-SPEC [ INSTANCE_NAME ] SPEC and TARGET-SPEC are as described above. SPEC indentifies the controlling instance of an existing cluster and TARGET-SPEC identifies the new cluster instance. If TARGET-SPEC identifies an existing repository, that repository will be deleted and reconstituted as a cluster instance. If INSTANCE-NAME is not specified, one will be assigned.
The OPTIONs are --group and -v/--verbose (more verbose output). --group is optional. It specifies the group the new instance should be in (if any). The value can be an existing group name (the instance will go in that group) or a new name (a new group will be created). See priority below for information on how groups are used.
Using agtool to specify cluster instance priorities
This cannot be done in WebView. The agtool repl priority usage is
agtool repl priority [ OPTION ] ... SPEC Options are --relation (see below) and -v/--verbose (more verbose output). SPEC is as described above.
Priorities specify how commits from different instances will be processed by a particular instance. See the section Repository Priority for information on how priorities are used.
The --relation argument value should be a string of the form name1,name2,value where nameX is a group or instance name.
Note that two instances in the same group have a default priority of 20 with respect to each other. This can be overridden. Two instances not in the same group (perhaps not in any group) and not having a defined priority have default priority 10.
Using agtool to quiesce a cluster so all instances sync up
This cannot be done in WebView. The agtool repl quiesce usage is
agtool repl quiesce [ OPTION ] ... SPEC SPEC is as described above.
OPTIONS include one required option, --action, and two optional options, --timeout (seconds to wait for the operation to complete) and -v/--verbose (more verbose output).
--action specifies the quiesce action. It must be one of:
stop: Put the specified instance in a state where attempting a new commit causes an error. The instance then waits to be connected to all other instances so all of its existing commits are distributed. Once all instances are in this state (see --
action=stopallbelow) then we know that all instances are caught up with all other instances. This action can timeout.stopall: This does the operation of
action=stopon all instances This action can timeout.start: This allows the specified instance to accept commits.
startall: This does the
--action=starton all instances.restartall: This does the
--action=stopallfollowed by theaction=startall.ready: This is like stop except it doesn't prevent commits from occuring. It just checks that this instance is connected to all other instances and that it has no more commits to distribute.
readyall: This does
--action readyon all instances.
Each instance of the cluster runs independently bringing itself up to date with other instances as rapidly as it can. There may be a time when you need all instances to get completely in sync and have a commit distributed to all of them before anything further is changed.
Quiescing the cluster means stopping all instances from commiting and waiting until all instances are up to date. All of the quiesce operations will only work if all cluster instances are running. If any have been stopped or if an agraph server is simply unreachable at the moment the quiesce operation will wait until all instances are running or until the specified timeout is reached. Specifying a timeout is always a good idea as otherwise the system can wait forever.
Using agtool to remove a cluster instance
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl remove usage is
agtool repl remove [ OPTION ] ... SPEC INSTANCE_NAME Options are --force (force operation to complete even if all requirements are not met), --timeout (number of seconds to wait for the operation to complete), --undo-repl (as described in detail below) and -v/--verbose (more verbose output). SPEC is as described above and must specify the controlling instance of the cluster. The instance name (in the cluster) must be included and cannot be the controlling instance name. INSTANCE_NAME can be the name or a SPEC value denoting the instance to be removed. The instance identified by INSTANCE_NAME is removed from the cluster. (Note that the format of this command differs from other commands. SPEC and INSTANCE_NAME both must be supplied and must refer to different instances: SPEC to the controlling instance, INSTANCE_NAME to the instance to be removed, which cannot be the controlling instance.)
When an instance is removed it can never join the cluster again nor should it ever be opened since it will try to communicate with the other cluster instances who now will refuse to talk to it. So the repo is useless once removed.
However the --undo-repl option to agtool repl remove and agtool repl stop will convert the repo back to a normal repo so it can be opened and used like a normal repo. See the documentation of agtool repl stop for more details on converting an MMR repo to a normal repo.
The undo-repl operation only works on an MMR repo that is currently an active part of a cluster since it is when the repo is stopped (as part of the agtool repl remove command) that the conversion to a normal repo is done.
Using agtool to specify the transaction log retention period
This cannot be done in WebView. The agtool repl retain usage is
agtool repl retain [ OPTION ] ... SPEC SPEC is as described above.
OPTIONS are the following, which specify how transaction logs should be retained.
- --must-retain MUST-RETAIN
- The ID of the minimum transaction log that must be retained. A value of -1 will turn off retention based on this value.
- --since-time SINCE-TIME
- All transactions since the given date must be retained.
SINCE-TIMEmust be an ISO date, "now", or a universal time. A value of -1 will turn off retention based on this value. - --time-interval TIME-INTERVAL
- Transaction log entries between now and time-interval seconds ago will be retained. You can use this to retain, say, the last 24 hours of entries by specifying 86400 seconds. A value of -1 turns off retention based on this value.
There is also a -v/--verbose option (more verbose output).
Using agtool to set cluster parameters
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl settings usage is
agtool repl settings [ OPTION ] ... SPEC [ INSTANCE_NAME ] Options allow you to specify which settings you want to set. See Instance Settings above for more information on these values. The choices are:
- --distributed-transaction-timeout SECONDS
- Set the distributed transaction timeout in seconds for all instances.
- --durability DURABILITY
- Set the durability for the cluster: an integer or
min,maxorquorum. - --transaction-latency-count COUNT
- Set the transaction latency count for all instances.
- --transaction-latency-timeout SECONDS
- Set the transaction latency timeout in seconds for all instances.
There is also a -v/--verbose option (more verbose output). SPEC is as described above and must be the controlling instance.
Using agtool to start an instance
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl start usage is
agtool repl start [ OPTION ] ... SPEC The single option is -v/--verbose (more verbose output). SPEC is as described above and need not be the controlling instance. The command is sent directly to the specified instance which is then restarted. This is a no-op if it is already running.
Using agtool to get the status of an instance
The agtool repl status usage is
agtool repl status [ OPTION ] ... SPEC The single option is -v/--verbose (more verbose output). SPEC is as described above. The instance status is printed. Note the status is quite verbose and is intended to assist debugging so may not be meaningful to users. This can also be done in WebView (see Managing clusters in WebView once created). Not all the information is displayed in WebView.
Using agtool to stop a cluster instance
This can also be done in WebView (see Managing clusters in WebView once created). The agtool repl stop usage is
agtool repl stop [ OPTION ] ... SPEC Options are --force (force operation to complete even if all requirements are not met), --timeout (seconds to wait for the operation to complete), --undo-repl (described below), and -v/--verbose (more verbose output). SPEC is as described above. It identifies the instance to be stopped, not the controlling instance (unless that is the instance to be stopped). The specified instance is stopped (no longer can make or process commits). This is a no-op if it is already stopped.
The --undo-repl operation turns the repo from an MMR repo into a normal repo. If you do this operation on a currently running instance you should do agtool repl remove --undo-repl instead as it will do agtool repl stop --undo-repl and then remove the instance from the cluster.
If you wish to restore a backup of an MMR instance and make it into a normal instance you should
1. agtool archive restore the repo
2. agtool repl start the repo so it can then be stopped
3. agtool repl stop --undo-repl to convert to a normal repo If you wish to create a new cluster whose initial value is this repo do
agtool repl create-cluster --if-exists use
Details on Certain Multi-master Replication Features
In this section, we describe certain features mentioned elsewhere in this document but requiring a longer description best put in a single location.
Repository priorities
All repositories in a replication cluster share information about their own commits and those of other repositories that they know about. This ensures that cases like the following are properly handled: REPO-3 is down when REPO-1 makes a commit, and then REPO-1 goes down followed by REPO-3 coming up. REPO-2 -- which has been running the whole time -- will inform REPO-3 of REPO-1's commits.
It can sometimes happen that a repository falls behind (perhaps it was offline or running slowly during a period of great activity). In that case, it finds that the same commit information is available from many other repositories and the question arises: from which of the repositories should it take the information?
Suppose in your setup you have two data centers, one in Chicago in the USA and one in Singapore. Each has 10 machines each running an AllegroGraph server. You have a multi-master replication cluster with instances on every one of the 20 servers.
If an instance in Singapore falls behind (say, because its server is taken down for maintenance for 24 hours during which other instances made many commits), it will be far behind when it comes back up. Should it get information from an instance in Chicago, which is around the world, or another instance in Singapore, down the hall? Obviously it should get as much information as possible from its neighboring instances.
Where instances prefer to get information is determined by the priority feature. When the same information is available from many instances, it will be taken from the instance whose priority is highest.
Here is a more detailed example. All instances in a replication cluster are named instN (where N is an integer).
Instance inst1 needs a certain commit and it finds that the commit is available on inst2, inst3 and inst4.
Which instance should inst1 ask for the commit?
The system calculates the priority between the pairs
inst1 inst2
inst1 inst3
inst1 inst4 and the highest value wins.
Groups also come into play when computing the priority. Each instance is in zero or one group.
The set of group names are distinct as are the set of instance names. Furthermore group names are distinct from instance names. Thus a particular name is either an instance name, a group name or neither.
The priorities are specified as a set of triples:
(name1, name2, priority) meaning for name1 the priority of getting commits from name2 is priority. Again name1 and name2 can be names of instances or groups.
The priority will determine whether we use this connection to retrieve a commit we need.
For each pair of instances inst1 and inst2 we compute the priority value this way, checking each of the possibilities listed in order and stopping when we find a possibility that matches:
If there's a triple
["inst1", "inst2", value]then that is the priority value for inst1 getting commits from inst2.If inst1 is a member of group group1 and there is a triple
["group1", "inst2", value]then that is the value.If inst2 is a member of group2 and there is a triple
["inst1", "group2", value]then that is the value.If inst1 is in group1 and inst2 is in group2 and there is a triple
["group1", "group2", value]then that is the value.If none of the above match then the default value is 10.
For each group there's a default triple (that can be overridden) of
["group1","group1", 20] meaning, by default members of the same group have a priority of 20 between them. Two instances that are in no group are not considered to be in the same group.
Priorities can be set between instances and/or groups with agtool or using the REST interface. They cannot be set with Webview.
Triple count reports may be inaccurate
When you request a count of the triples in a repository (with, for example, the Lisp function triple-count or the GET /repositories/[name]/size request in the REST/HTTP interface), the result may be inaccurate if the repository is a multi-master instance. The result may even be negative.
The reason is that commits may not be replicated and applied in causal order.
Consider the following scenario. We have three multi-master nodes A, B, and C, and assume at the start, all are empty. Then:
- Node A adds triples and commits.
- Node B receives and applies the add-triples commit from node A.
- Node B deletes the triples and commits.
- Node C receives and applies the delete-triples commit from node B. The triple count is now negative.
- Node C receives and applies the add-triples commit from node A. The triple count returns to zero.
You can also get a positive but inaccurate count. Suppose each node contained the same set of 10 triples at the start and those triples are not among those deleted in step 3. Supposed further that 5 triples are added in step 1 and those 5 are deleted in step 3. Then C will show 5 triples in step 4, an inaccurate count.
Counts will be accurate if there are no deletes. The count will eventually be accurate even when there are deletes once all commits have been replicated and applied.
For non-multi-master repositories, a negative triple count indicates some error.
The REST interface for multi-master replication
Multi-master replication clusters can be created and managed using the REST interface. There is an introduction to multi-master replication REST commands in the Multi-master replication section of the REST/HTTP interface. All REST interface commands are described in the HTTP reference document.