Introduction
Attributes are name/value pairs that can be associated with triples or users. Names and values must be strings. Attributes can only be associated with a triple at the time the triple is added to the triple store (with functions such as add-triple or Data Import tools. Once a triple has been added to the store, its attributes cannot be modified.
There are many potential uses of triples attributes, including access control. Attributes can specify which users can access which triples. Users can also be given attributes, which can be compared to the triple attributes. Suppose for example there is an attribute name "security-level" with values "high", "medium" and "low". Then a user with "security-level" attribute "medium" can be prevented from viewing triples with "security-level" attribute "high". See the Triple Security document for more information on triple-level security.
Because triples can have as many attributes as desired and attributes can have as many values as desired (there are configurable limits but the defaults are much larger than any conceivable application), access control can be as finely tuned as desired.
Attributes can be associated with triples when adding them one statement at a time, or via file import. Once a triple has been added to a repository, its associated attributes cannot be changed or removed.
Attribute characteristics
An attribute is a name/value pair where both the name and the value are strings. Attributes are assoicated with specific triples. While the theoretical maximum size of an attribute value is approximately one terabyte, the pratical maximum size will be limited by the amount of available virtual memory and address space.
There are restrictions on the characters allowable in an attribute name. An attribute name may be composed of characters of the following types:
- a letter
- a digit
- a dash (-)
- an underscore (_)
- having a codepoint >= 128
That is, standard 7-bit ASCII characters are restricted to letters and digits and two additional characters (- and _) but anything outside the standard 7-bit ASCII range is allowed.
Use of attribute __quoted__ by RDF star
RDF star (see the RDF star document) uses a special triple attribute named __quoted__. Users should not add or use that attribute name.
Associating attributes with triples: NQX files
A new file format has been designed, called Extended N-Quad format (NQX, for short) which extends the N-Quads format to allow the specification of attributes for each triple in the file.
Each line of an NQX file has the following format:
[An N-Quad line without the ending .] [attributes] . N-Quad lines are defined here. The attributes can be absent. If present, it must be in JSON format:
{ "pet": "dog", "key2": [ "red", "blue" ] } Here we specify three attribute name/value pairs:
"pet"/"dog"
"key2"/"red"
"key2"/"blue" Here are some sample lines from an NQX file:
_:b0EF918FCx100 <http://example.org/ontology/infractions> <http://example.org/ontology/Infraction#ExcessiveTardiness> {"securityLevel": "high", "department": "hr", "accessToken": ["E", "D"]} .
_:b0EF918FCx100 <http://example.org/ontology/salary> "100000"^^<http://www.w3.org/2001/XMLSchema#int> {"securityLevel": "medium", "department": ["accounting", "hr"], "accessToken": "A"} .
_:b0EF918FCx100 <http://example.org/ontology/department> <http://example.org/ontology/ops> {"securityLevel": "low", "department": ["sales", "accounting", "hr", "devel"], "accessToken": "A"} .
_:b0EF918FCx100 <http://example.org/ontology/name> "Joe Smith" {"securityLevel": "low", "department": ["sales", "accounting", "hr", "devel"], "accessToken": "A"} . N-Quad format supports optionally specifying a graph. Those example lines do not includes graphs. Here is a line with a graph (<http://ex#trans@@1142684573200001>):
<http://dbpedia.org/resource/Arif_Babayev> <http://dbpedia.org/property/placeOfDeath> <http://dbpedia.org/resource/Baku> <http://ex#trans@@1142684573200001> {"color": "red"} . The system distinguishes between a graph and an attribute specification because attributes are specified in JSON format and graphs are not.
Attributes must be defined before a file using them can be loaded. Attributes cannot be defined in a NQX file or in any triple format file. See the Defining Attributes section for information on defining attributes.
For all other supported triple file formats (N-Quad, N-Triple, Turtle, etc.), a set of default attributes can be specified at import time. These default attributes will be attached to each triple imported from the source. When NQX files are loaded, they too can have default attributes specified and those will be associated with any triple in the file that does not have individual attributes specified. See the Data Import document.
Defining attributes
Attributes must be defined before they can be used. Defining an attribute establishes the name of an attribute and any constraints that should be placed on its use.
Defining attributes with Java, the REST interface, and AGWebView
Attributes can be defined in various ways. The Java interface uses methods in the AGRepositoryConnection.AttributeDefinition class (see the Javadoc index). There is a complete example in java-tutorial/AttributesExample.java. The REST/HTTP interface can also be used to define attributes. See the Attributes section in the REST/HTTP interface document. New WebView has an Attribute Definitions and Static Filter page accessible with the Attribute definitions & Static filter choice on the Repository control submenu of the Respository menu. Traditional AGWebView has a Define attributes definitions choice on the Repository page.
Defining attributes with agtool
The agtool program is the general program for AllegroGraph command-line operations. Among the operations supported are
- define-attribute
- delete-attribute-definition
The latter deletes an attribute definition.
The expressions
agtool define-attribute --help and
agtool delete-attribute-definition --help will show the arguments and calling sequence of the commands.
Defining attributes in Lisp
The Lisp function define-attribute (the definition appears in the Lisp Reference document) also can be used to define attributes.
The arguments to define-attribute are
name &key db allowed-values ordered minimum-number maximum-number db is the triple store. name is the attribute name. name must be a string made up of letters, digits, the characters #\- and #_, or characters with code point 128 or greater (that is, letters, digits, hyphen, and underscore among 7-bit ASCII characters and any character that cannot be represented in 7-bit ASCII).
allowed-values, if specified, must be a list. It restricts attribute values to members of the list. The values must be strings. If attributes are ordered, then they can be compared with predicates like attribute>=.
For example, if there is a "securityLevel" attribute, it can be ordered. Suppose the allowed-values are ("low" "medium" "high"). The ordering comes from the position in the list (and not from alphabetical or other orderings, so "low" is less than "high" and so on). Each triple with attribute "securityLevel" will have a value from that list. Users can also have a "securityLevel" attribute. A filter can be set up that allows only users with a security level equal to or higher than the triple security level to access the triple.
Attribute definitions are transactional. They do not persist unless committed. Attempting to commit a definition for a name which is already committed (presumably by another authorized user) will result in a conflict, which is detected at commit time. The second committer must then roll back.
The Lisp function define-attribute can be used to define attributes. The functon add-triple has an :attributes keyword argument where the attributes of the new triple can be specified (attributes can be associated with a triple only when it is added or loaded). The various triple loading functions like load-nquads have an :default-attributes keyword argument which specifies the attributes to be added to all triples being loaded. The function load-nqx and load-nqx-from-string will load NQX files which allow attributes to be specified for individual triples. (Only NQX files can have attributes for individual triples specified.) The :default-attributes argument to load-nqx and load-nqx-from-string specify attributes for those triples which have no attributes specified in the file or string.
Static filters
A static filter using an S-expression-based query can be established on a given triple store. This filter will be applied to all queries. Only triples which match the filter will be returned by any query against the store.
Both triples and users can have attributes. Therefore, the attributes of a user performing a query can be compared to the triple attributes and if the user's attributes are not appropriate, the triple will be invisible to the user. User attributes can be supplied in HTTP requests using the x-user-attributes header. When supplied, the header must contain a JSON object representing attributes, for example:
{ "color": "red" }
{ "color": ["red"] }
{ "color": ["red", "blue"] } Static filter definitions are transactional. They do not persist unless committed. Attempting to commit a definition when a static filter is already committed (presumably by another authorized user) will result in a conflict, which is detected at commit time. The second committer must then roll back.
Static filter definitions
Static filters can be defined and deleted with the following tools:
- AGWebView -- see the Set static attribute filter choice on the Repository page).
- The Java interface -- see the Javadoc index; there is a complete example in java-tutorial/AttributesExample.java).
- The REST/HTTP interface - see the Attributes section in the REST/HTTP interface document).
- agtool -- using the set-static-attribute-filter and delete-static-attribute-filter commands.
Static filter expressions
Definitions
An attribute container is a collection of attribute sets. Both triples and users are attribute containers since they can have attributes associated with them.
An attribute set is the set of all values for a given named attribute within an attribute container. Attribute sets can also be specified using literal strings (or lists thereof).
Grammar
The syntax of a static filter expression is as follows:
EXPR := (OPERATOR SET*)
EXPR := (and EXPR*) # True if all of the subexpressions are true.
EXPR := (or EXPR*) # True if at least one subexpression is true.
EXPR := (not EXPR) # True if EXPR is false.
SET := CONTAINER.ATTRIBUTE-NAME # An attribute set specification.
SET := "string" # Literal string representing an attribute
# set with a single value.
SET := ("string1" ... "stringN") # An attribute set consisting of the
# supplied string values.
CONTAINER := user # The attributes of the current user, e.g., from
# the x-user-attributes HTTP header.
CONTAINER := triple # The attributes of the triple being considered
# for filtering.
ATTRIBUTE-NAME := IDENTIFIER # The name of a defined attribute.
# These operators are described in the next section
OPERATOR := empty | overlap | attributes-overlap
| attribute-contains-one-of | subset | superset |
attribute-contains-all-of | equal |
attribute-set<= | attribute-set< | attribute-set= |
attribute-set> | attribute-set>= Operators
empty
(empty SET) True if the specified attribute set is empty.
overlap, attributes-overlap, attribute-contains-one-of
(overlap SET1 SET2)
(attributes-overlap SET1 SET2)
(attribute-contains-one-of SET1 SET2) True if there is at least one matching value between the two attribute sets. False if either SET1 or SET2 is empty.
subset
(subset SET1 SET2) True if SET1 is a subset of SET2. In other words, true if every element of SET1 can be found in SET2.
Note that (subset SET1 SET2) is equivalent to (superset SET2 SET1).
superset, attribute-contains-all-of
(superset SET1 SET2)
(attribute-contains-all-of SET1 SET2) True if SET1 is a superset of SET2. In other words, true if SET1 contains at least every element from SET2.
Note that (superset SET1 SET2) is equivalent to (subset SET2 SET1).
equal
(equal SET1 SET2) True if SET1 and SET2 have exactly the same contents.
attribute-set<=, attribute-set<, attribute-set=, attribute-set>, attribute-set>=
(attribute-set<= ORDERED-SET1 ORDERED-SET2)
(attribute-set< ORDERED-SET1 ORDERED-SET2)
(attribute-set= ORDERED-SET1 ORDERED-SET2)
(attribute-set> ORDERED-SET1 ORDERED-SET2)
(attribute-set>= ORDERED-SET1 ORDERED-SET2) In these cases, ORDERED-SETn can contain zero or one element(s). If either ORDERED-SET is empty, the operator returns false. Otherwise, if the single element in ORDERED-SET1 is <=, <, =, >, or >= (depending on the operator) the single element of ORDERED-SET2, the operator returns true. Comparisons are case-sensitive.
The ordering of values is determined by the attribute definition. The ordering is not based on the lexicographical order of the value strings.
At least one of ORDERED-SET1 or ORDERED-SET2 must be an attribute set specification in CONTAINER.ATTRIBUTE-NAME form and ATTRIBUTE-NAME must name an attribute that was previously defined to be ordered.
Example filter expressions
;; The accessing user must have an access level greater than or
;; equal to that of the triple.
(attribute-set>= user.access-level triple.access-level)
;; The accessing user must be a member of all of the departments
;; indicated by the triple.
(attribute-contains-all-of user.department triple.department)
;; The accessing user must be a member of at least one of the
;; departments indicated by the triple.
(overlap user.department triple.department)
;; The accessing user must have a sufficient access level and be a
;; member of at least one of the triple's departments:
(and
(attribute-set>= user.access-level triple.access-level)
(overlap user.department triple.department))
;; Only return triples that are below SuperSecret level.
(attribute-set< triple.access-level "SuperSecret") Getting and Setting Metadata
The attribute and static filter definitions in a store (collectively known as metadata) can be retrieved and then used to specify or add to the metadata of another store. There are many tools available to do this:
agtool export (see the
--save-metadataoption in the Repository Export document) and agtool load (see the--metadataoption in the Data Import document.agtool get-metadata (see agtool.
Using the
GET /repositories/[name]/metadataandPOST /repositories/[name]/metadataservices in the HTTP/REST interface (see the Attributes section of the REST/HTTP interface document.Using the Lisp functions get-metadata, set-metadata, load-metadata, and save-metadata.
When you load/set metadata, it is an error to modify an existing attribute definition (you can only add more definitions). You must commit after loading/setting for the changes to be permanent.
Attributes example
There is a complete example of using attributes and a static filter in [AllegroGraph directory]/doc/java-tutorial/AttributesExample.java. Please look at the Java code for precise details. Here we will discuss the example in general.
The example defines three attributes: "securityLevel", "department" and "accessToken". The Java code defines these. Here are the details of their definitions:
Name: "securityLevel"
Minimum number: 1
Maximum number: 1
Values: "low","medium","high"
Ordered: Yes
Name: "department"
Values: "hr","devel","sales","accounting"
Ordered: No
Name: "acessToken"
Values: "A","B","C","D","E""
Ordered: No
Because securityLevel has min and max 1, there must be exactly one of these attributes for every added triple.
We add a static filter. Again, see the Java code. Here is the filter expression:
(and (attribute-set>= user.securityLevel triple.securityLevel)
(attribute-contains-one-of user.department triple.department)
(attribute-contains-all-of user.accessToken triple.accessToken)) The filter requires that the user.securityLevel be greater than or equal to the triple security level, the user.department is in the list of triple departments, and the list of user.accessTokens contains all the triple accessTokens. Unless these conditions are met, the triple will be invisible to the user.
In the current implementation, individual users cannot be assigned attributes. A static filter can be defined for a repository but in order to use attributes to control which triples are visible, you must write a program which does its own authentication of the user and preparation of user attributes. The program then calls out to AllegroGraph, passing in the user's attributes, to get the visible triples.
In the future, we intend to allow attributes to be assigned to AllegroGraph users and roles. Then the AllegroGraph user can access the database directly, with the static filter comparing the user's attributes with the triple attributes and returning or not returning triples according to the filter.
Querying Attributes using SPARQL
There are two SPARQL Magic Properties that can be used to query triple attributes:
- http://franz.com/ns/allegrograph/6.2.0/attributes
- http://franz.com/ns/allegrograph/6.2.0/attributesNameValue
The first returns all of a triple's attributes in JSON format whereas the second returns each name/value pair in turn. For example, suppose we have these two triples (expressed in NQX format):
<http://www.w3.org/1999/02/22-rdf-syntax-ns#test2> <http://www.w3.org/1999/02/22-rdf-syntax-ns#b> <http://www.w3.org/1999/02/22-rdf-syntax-ns#two> {"department": ["hr", "sales"], "rank": "Low", "label": "test 1"} .
<http://www.w3.org/1999/02/22-rdf-syntax-ns#test1> <http://www.w3.org/1999/02/22-rdf-syntax-ns#b> <http://www.w3.org/1999/02/22-rdf-syntax-ns#one> {"rank": "Low", "label": "test 1"} . Then
select ?s ?attributes {
?attributes <http://franz.com/ns/allegrograph/6.2.0/attributes> (?s ?p ?o) .
} would return
---------------------------------------------------------------------------------
| s | attributes |
=================================================================================
| rdf:test2 | {"department": ["hr", "sales"], "rank": "Low", "label": "test 1"} |
| rdf:test1 | {"rank": "Low", "label": "test 1"} |
--------------------------------------------------------------------------------- Whereas using attributesNameValue
select ?s ?name ?value {
(?name ?value) <http://franz.com/ns/allegrograph/6.2.0/attributesNameValue (?s ?p ?o) .
} would output:
-----------------------------------
| s | name | value |
===================================
| rdf:test2 | label | test 1 |
| rdf:test2 | rank | Low |
| rdf:test2 | department | hr |
| rdf:test2 | department | sales |
| rdf:test1 | label | test 1 |
| rdf:test1 | rank | Low |
----------------------------------- You can use supply values for any of these variables using normal SPARQL mechanisms. E.g.,
select ?s ?name ?value {
bind('label' as ?name)
(?name ?value) <http://franz.com/ns/allegrograph/6.2.0/attributesNameValue (?s ?p rdf:one) .
} would filter the results to a single attribute name/value pair for a single subject:
------------------------------
| s | name | value |
==============================
| rdf:test1 | label | test 1 |
------------------------------ Attributes and SPARQL INSERT
You typically assign attributes at load time or when a triple is added using the WebView interface. Attributes must be specified when a triple is added. Here are the current triples in the repo:
s p o attributes
data1 pred 22 {"att1": "yes"}
data2 pred 44 {"att2": "yes"} Triples can be added during a SPARQL INSERT operation. Here is a SPARQL INSERT command:
Here is a simple INSERT query:
insert {
?s <www.franz.com/newpred> ?o . }
where {
?s <www.franz.com/pred> ?o } That will insert two new triples
data1 newpred 22
data2 newpred 44 but those triples will not have attributes.
This is a problem if you want to protect the new triples similarly to the triples they we created from. You can however cause the new triples to get the same attributes as the triples which caused them to be inserted with the following revised SPARQL INSERT query:
PREFIX attr: <http://franz.com/ns/allegrograph/6.2.0/>
INSERT {
attribute ?attr { ?s <www.franz.com/newpred> ?o . }
} WHERE {
?attr attr:attributes (?s <www.franz.com/pred> ?o ) results in
s p o attributes
data01 pred 22 {"att1": "yes"}
data02 pred 44 {"att2": "yes"}
data02 newpred 44 {"att2": "yes"}
data01 newpred 22 {"att1": "yes"} Aggregating attributes of duplicate triples
AllegroGraph supports duplicate triple suppression which will prevent a triple from being added that duplicates an existing or a to be committed triple at commit time and can be set to spo or spog mode. Additionally, attribute aggregation strategy can be provided along with duplicate suppression mode, and it will control if and how the attribute values of would be duplicate triples are combined.
Since AllegroGraph does not support modifying existing triples, when attribute aggregation is enabled and a duplicate of an existing triple is encountered at commit time, the existing triple will be deleted and the duplicate will not be added, but instead a new triple will be created with the same SPO/SPOG parts and updated attribute values.
Since triples can have multiple values for the same attribute, it is convenient to think of attribute values as multisets of strings. Single string value for an attribute is just a singleton multiset. Attribute aggregation strategy simply associates attribute names with operations which take two string multisets and combine them in a certain way, returning a new attribute value. The following operations are supported:
- retain - keep the attribute values of the existing triple (see triple ordering explanation below for an important caveat); if the existing triple has no values for the given attribute, its value is considered to be an empty multiset and will be retained (i.e. the resulting triple will have no value as well); for example, combining the triples (the existing one is listed first):
<ex:s> <ex:p> <ex:o>. <ex:s> <ex:p> <ex:o> {"a": ["1", "2"]}.
will leave behind the single triple
<ex:s> <ex:p> <ex:o>.
<ex:s> <ex:p> <ex:o> {"a": ["1", "2"]}.
<ex:s> <ex:p> <ex:o>. will leave behind the single triple
<ex:s> <ex:p> <ex:o>.
<ex:s> <ex:p> <ex:o> {"a": "1", "a": "2"}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "2"]}.
<ex:s> <ex:p> <ex:o> {"a": "1"}. will leave behind the single triple
<ex:s> <ex:p> <ex:o> {"a": ["1", "2", "1", "2", "1"]}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "1"]}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "2", "3"]}.
<ex:s> <ex:p> <ex:o> {"a": "3", "a": "4"}. will leave behind one of the following triples
<ex:s> <ex:p> <ex:o> {"a": ["1", "2", "3", "4"]}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "1", "2", "3", "4"]}.
union, this operation does not guarantee removing duplicate elements if they are present in either of the operands; for example, combining the triples
<ex:s> <ex:p> <ex:o> {"a": ["1", "1"]}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "2"]}.
<ex:s> <ex:p> <ex:o> {"a": "3", "a": "1"}. will leave behind one of the following triples
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": ["1", "1"]}.
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": ["2", "3"]}. will leave behind the single triple
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": ["2", "3"]}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "3"}.
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": ["2", "3"]}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "6"}.
<ex:s> <ex:p> <ex:o> {"a": ["2021-02", "2021-02-03"]}.
<ex:s> <ex:p> <ex:o> {"a": "2021-02-03T04:05:06"}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "2021-02"}.
<ex:s> <ex:p> <ex:o> {"a": ["2021-02", "2021-02-03"]}.
<ex:s> <ex:p> <ex:o> {"a": "2021-02-03T04:05:06"}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "2021-02-03T04:05:06"}.
string-to-universal-time Allegro Common Lisp function; values of the form YYYY-MM-DD assume time T00:00:00; values of the form hh:mm:ss assume date 0000-01-01; non-standard date format DD-MM-YYYY is also supported for convenience; see below for what happens if the attribute values cannot be parsed as either date/time values; for example, combining the triples
<ex:s> <ex:p> <ex:o> {"a": ["01:02:03", "2021-02-03"]}.
<ex:s> <ex:p> <ex:o> {"a": "03-02-2021T04:05:06"}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "01:02:03"}. because the value 01:02:03 is interpreted as 0000-01-01T01:02:03 and is therefore the smallest.
<ex:s> <ex:p> <ex:o> {"a": ["01:02:03", "2021-02-03"]}.
<ex:s> <ex:p> <ex:o> {"a": "03-02-2021T04:05:06"}. will leave behind the triple
<ex:s> <ex:p> <ex:o> {"a": "03-02-2021T04:05:06"}.
If the attribute aggregation strategy is not specified or a particular attribute is not included in it, the default behavior is retain: new triples are eliminated and the original triple is kept along with its attributes.
Example of using AllegroGraph Lisp interface to set a duplicate suppression strategy that will aggregate attribute a using sum operation and attribute b using collect (note when using a Lisp form, the suppression mode SPO/SPOG and aggregation operations are specified using keywords rather than strings):
(setf (db.agraph:duplicate-suppression-strategy)
'(:spo (("a" . :sum)
("b" . :collect)))) The same can be done via HTTP interface like this:
curl -X PUT \
http://user:pass@localhost:10035/repositories/test/suppressDuplicates?type=spo \
-d '{ "a": "sum", "b": "collect" }' Specifying attribute aggregation using New WebView
You can also specify attribute aggregation rules using this page for in New WebView:
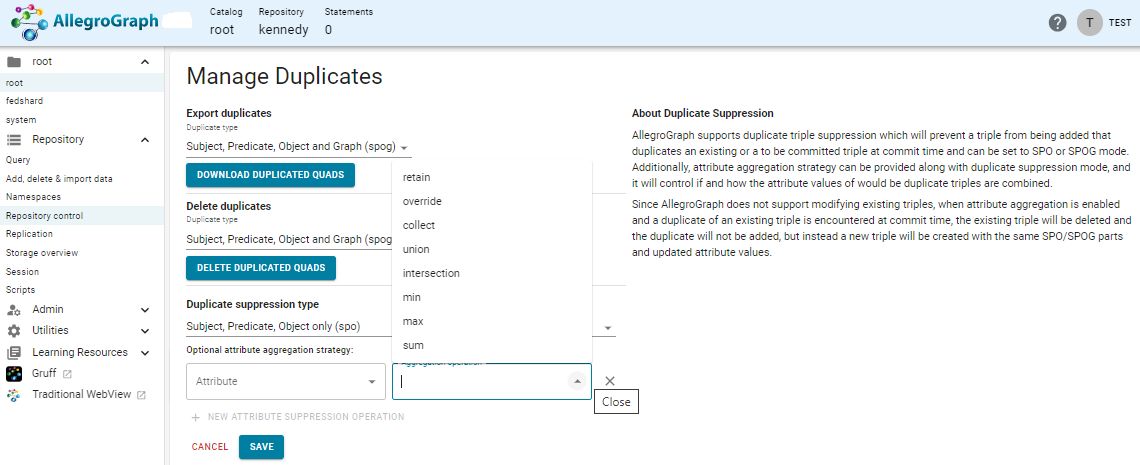
The page is displayed by the Manage Duplicates menu item in the Repository Control menu linked on the left when a repository is open. There are two boxes in the Optional attribute aggregation strategy field at the bottom of the image, one for the attribute name (labeled Attribute) and one for the strategy (in the image displaying the menu of choices). If these are specified, they will be used and when duplicates are suppressed (whether when added or later), new triples with the correct aggregated list of attributes and values will be the result of handling the duplicate triples.
Handling attribute aggregation errors
Attribute definitions may specify value constraints like the set of allowed values and minimum or maximum number of values permitted. When setting attribute aggregation strategy, it is up to the user to ensure that the attribute value constraints will be respected. If the result of the attribute aggregation violates the attribute value constraints, the attribute value will remain unchanged (i.e. the retain behavior). For example, assuming an attribute a with allowed values 1 and 2, combining the triples
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": "1"}. with the sum operation will produce the triple
<ex:s> <ex:p> <ex:o> {"a": "2"}. because 2 is still an allowed value, but combining the triples
<ex:s> <ex:p> <ex:o> {"a": "1"}.
<ex:s> <ex:p> <ex:o> {"a": "2"}. will keep the triple
<ex:s> <ex:p> <ex:o> {"a": "1"}. because value 3 is not allowed for attribute a.
The same thing happens when applying a numeric operation (min, max, sum) or a date/time operation (dtmin, dtmax) to a value that does not represent an integer or a date/time respectively, for example combining the triples (the existing one is listed first)
<ex:s> <ex:p> <ex:o> {"a": "not-a-number"}.
<ex:s> <ex:p> <ex:o> {"a": "1"}. with one of the numeric operations will leave behind the existing triple
<ex:s> <ex:p> <ex:o> {"a": "not-a-number"}. because it is impossible to interpret not-a-number as an integer.
Relative order of the duplicate triples
At commit time, when the duplicate suppression is applied, each new triple being committed into the repository may be a duplicate of a triple that is already committed in the repository or a duplicate of another triple being added in the current commit.
The relative order of the triples can only be determined when one of them is committed and the other is not. This is very important to consider when using the retain or override operations. For example, if the repository contains a committed triple
<ex:s> <ex:p> <ex:o> {"a": "1"}. and we are committing a new triple
<ex:s> <ex:p> <ex:o> {"a": "2"}. then we can know for sure that retain will keep the value 1 and override will keep the value 2, but if we are committing two new triples
<ex:s> <ex:p> <ex:o> {"a": "2"}.
<ex:s> <ex:p> <ex:o> {"a": "3"}. then retain will still always keep 1, but override may keep either 2 or 3 because relative order between new triples is not enforced for performance reasons. If there is no existing duplicate triple, both retain and override will keep either 2 or 3.
For the same reasons, attribute aggregation will be applied to all new triples added in the current commit, but only to one of the triples already committed. For example, assuming the sum aggregation operation, if the repository already contains the following two quads
<ex:s> <ex:p> <ex:o> <ex:g1> {"a": "1"}.
<ex:s> <ex:p> <ex:o> <ex:g2> {"a": "2"}. and we add the two new quads
<ex:s> <ex:p> <ex:o> <ex:g3> {"a": "3"}.
<ex:s> <ex:p> <ex:o> <ex:g4> {"a": "4"}. the resulting triples in the repository will be either
<ex:s> <ex:p> <ex:o> <ex:g1> {"a": "1"}.
<ex:s> <ex:p> <ex:o> <ex:g2> {"a": "9"}. or
<ex:s> <ex:p> <ex:o> <ex:g1> {"a": "8"}.
<ex:s> <ex:p> <ex:o> <ex:g2> {"a": "2"}. depending on which of the initial two triples was returned by the quick committed triple existence check during commit.
Note that there is currently no support for overriding the graph of the retained quad when spo suppression mode is used.
In order to aggregate attributes for all committed triples, one can use the following process (see Deleting duplicate triples for more information):
- Export duplicate triples as an NQX file to include attributes.
- Delete all duplicate triples from the repository.
- Set duplicate suppression strategy which includes the desired attribute aggregation strategy.
- Re-import the duplicate triples file obtained in step (1).