Introduction
AllegroGraph supports its own built in freetext indexer, Apache Solr text indices, and MongoDB indices.
Text-Indexing Features
The built in text indices are based on a locality-optimized Patricia trie, on which we do intelligent trie traversal for fast wildcard and fuzzy searches. The indexing process is fully transactional and is able to easily handle billions of documents.
You may manage AllegroGraph freetext indices through WebView or any of the AllegroGraph client APIs including Lisp, Python, or Java.
Each freetext index has a name, so you can apply it to a query or perform maintenance on it.
An index can be configured to include:
- Only triples with a given set of predicates.
- Only triples in a given set of graphs.
- Only triples
<s p o>for which a triple<s rdf:type t>exists for a given set of typest.
Additionally, an index can be configured to include:
- All literals, no literals, or specific types of literals.
- The full URI of a resource, just the local name of the resource (after the # or /), or ignore resource URIs entirely.
- Any combination of the four parts of a "triple:" the subject, predicate, object, and graph.
Stop words (ignored words) may be specified for each index, or the index can use a default list of stop words.
An index can make use of word filters such as stem.english, drop-accents, and soundex.
- stem.english: Provides stemming of English text.
- drop-accents: Normalizes non-English text by removing accented characters.
- soundex: Indexes words by how they sound, rather than how they are spelled.
From strings to words: Tokenizing
To index freetext, the engine first breaks strings into words (a process called tokenization). There are three built in tokenizers: default, japanese and simple-cjk.
The Default Tokenizer
The default tokenizer works well for most European languages. It defines a word as any run of letters that is at least as long as the minimum-word-size specified for an index. Dashes, underscores and periods do not break words unless they occur at the start or the end. It will also omit the stop words configured for the index. The default list is:
Below are some examples of strings and the words the tokenizer will extract from them:
| Hello there. I am fine. how are you? | "hello" "there" "fine" "how" "are" "you" |
| I think...therefore... I am. | "think...therefore" |
| When indexing, the freetext engine first tokenizes the strings in the triple's object. | "when" "indexing" "the" "freetext" "engine" "first" "tokenizes" "the" "strings" "the" "triple" "object" |
| k = x^{2} + y^{2} defines a circle. | "defines" "circle" |
Indexing words in Japanese
Specifying the :japanese tokenizer allows AllegroGraph to correctly index text from the Japanese language. Here is an example:
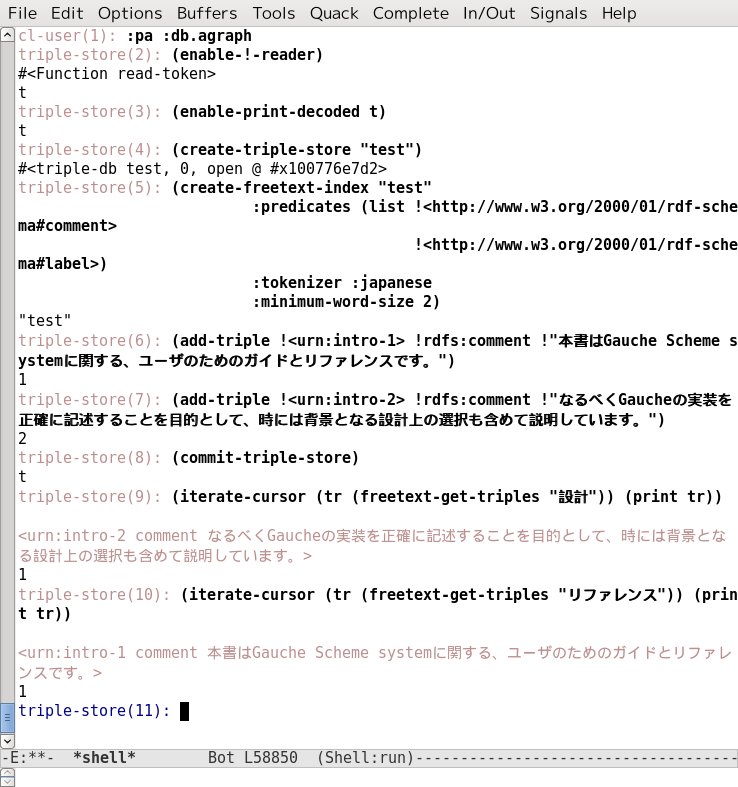
Indexing CJK (Chinese/Japanese/Korean words)
The value :simple-cjk' for the :tokenizer` keyword argument to create-freetext-index indexes Chinese/Japanese/Korean (CJK) text. It uses bigrams for consecutive CJK characters as words. To use this tokenizer, specify :simple-cjk as the tokenizer option when creating or modifying a freetext index.
The bigram tokenizer can be used for CJK mixed text, but its simplicity may result in false positives. It also tends to index a much larger number of words compared to other tokenizers.
Freetext Query Expressions
You can query the freetext indices using any AllegroGraph client and via SPARQL using the fti:match and fti:matchExpression magic properties. Each client uses the same query expression language defined informally below:
"string"- Matches triples containing all the words in the string.
(and <pattern1> <pattern2> ...)- Matches triples that match all of the given patterns.
(or <pattern1> <pattern2> ...)- Matches triples that match any of the given patterns.
(match "strings?*")- Matches triples that match the given string, supporting wildcards, where
?matches any single character, and*matches any number of characters. Note that, in a big triple-store, matching patterns starting with a*or?can be very slow. (fuzzy "string" [N=min(4, ceiling(length("string")/5))])- Matches triples that contain words which are at a Levenshtein distance
Nfrom the given string. ArgumentNis optional and if not given, will be computed as specified. (phrase "string")- Matches triples that contain the exact string given.
(fuzzy-phrase "string" [N=min(4, ceiling(length("string")/5))])- Matches triples that contain a multi-word substrings which are at a Levenshtein distance
Nfrom the given string. ArgumentNis optional and if not given, will be computed as specified. The difference betweenfuzzyandfuzzy-phraseis the latter can match multi-word sequences.
Example queries
- find all the triples whose object contains the word "baseball"
"baseball" - find all triples whose object contains all of the words "baseball", "soccer", and "champions"
"baseball soccer champions" (and "baseball" "soccer" "champions") - find all triples whose object contains at least one of the words "baseball", "soccer", or "champions"
(or "baseball" "soccer" "champions") - find all triples that contain any word ending in "ball" (note that this wildcard match is more expensive than the simple word matches above)
(match "*ball") - find all triples that contain any 8-letter word ending in "ball" (note that this wildcard match is more expensive than the simple word matches above)
(match "????ball") - find all triples that contain words at Levenshtein distance of 1 from the word "hello" (e.g. "hello", "hallo" and "jello")
(fuzzy "hello" 1) - find all triples that contain the exact phrase "baseball champions"
(phrase "baseball champions") - find all triples that contain a multi-word phrase at a Levenshtein distance 6 from the string "from Uzbekistan" (e.g. "from Uzbekistan", "from Kazakhstan" and "from Tajikistan")
(fuzzy-phrase "from Uzbekistan" 6)
The algorithm used to convert a query string into the s-expression format can be accessed either via the Lisp function freetext-parse-query or the http://franz.com/ns/allegrograph/6.5.0/parseFreetextQuery SPARQL magic property. For example:
(freetext-parse-query "\"common lisp\" (programming | devel*)")
==>
(and (phrase "common lisp") (or "programming" (match "devel*"))) This can be convenient when needing to convert user input into a freetext query.
Managing text indices with agtool
Native AllegroGraph text indices can be managed using agtool. The set of commands allows to create, update, delete, inspect, export and query freetext indices:
agtool freetext create REPO INDEX1 INDEX2 ...
agtool freetext create REPO --import path/to/export/file.def
agtool freetext update REPO [INDEX1 INDEX2 ...]
agtool freetext delete REPO INDEX1 [INDEX2 ...]
agtool freetext list REPO
agtool freetext export REPO [INDEX1 INDEX2 ...] path/to/export/file.def
agtool freetext query REPO QUERY [INDEX] See agtool's help messages for more details on supported arguments for all commands:
agtool freetext create --help An existing index configuration can be updated with update command:
agtool freetext update REPO INDEX1 --index-fields SPO Update operation always rebuilds indices. The following commands will rebuild a set of indices or all indices respectively without changing their configurations:
agtool freetext update REPO INDEX1 INDEX2
agtool freetext update REPO Export operation by default exports configuration of all existing indices in a given repository, but it can also export a subset of indices
agtool freetext export REPO INDEX1 INDEX2 EXPORT.def Importing index configuration can be done via create command by omitting index names and using the --import option:
agtool freetext create REPO --import EXPORT.def Export files contain index descriptions in the lineparse format and can be written by hand. Here is an example of creating an index from a lineparse description read from the standard input:
agtool freetext create REPO --import - <<EOF
index
name i1
predicates <http://example.org/p1>
graphs default <http://example.org/g1>
types <http://example.org/T1> <http://example.org/T2>
index-literals <http://example.org/LT1> en
index-resources no
index-fields s p o g
stop-words and or the
tokenizer default
inner-chars digit "ぁ-ゖ"
border-chars " "
word-filters drop-accents soundex
EOF Here is a listing of the supported freetext index fields which can be useful for writing definition files by hand:
name- name of the index; the only required field;predicates- a list of predicate IRIs to restrict indexing to statements with these predicates;graphs- a list of graph IRIs (or a stringdefault) to restrict indexing to statements in these graphs;types- a list of IRIs denoting RDF types to restrict indexing only to statements, for the subject of which there exists a coresponding RDF type declaration;index-literals-yes,noor a list of IRIs and/or language tags to restrict indexing only to literals of given types/languages;index-resources-yes,noorshort(the latter means only index the part after the#or the last/in the IRI);index-fieldsat most 4 valuess/subject,p/predicate,o/object,g/graphdenoting statement fields to index;stop-words- a list of stop words to use;tokenizer- a single string denoting one of the supported tokenizers (see above);border-chars- a list of strings denoting ranges of characters that can appear at word boundaries; allowed values arealpha,digit,alphanumeric, single-character strings (e.g." ","["), or dash-separated pairs of characters to denote character ranges (e.g."a-z","ぁ-ゖ");inner-chars- a list of strings denoting ranges of characters that within words; allowed values are the same as forborder-chars;word-filters- a list of strings denoting word filters to apply (see above).
IRIs must be wrapped in <>. If any field except name is omitted from the description, the default value will be used. The default values for all fields are provided in the output of
agtool freetext create --help Finally, query tool can be used to quickly query any of the existing freetext indices. For convenience both expanded s-expression queries and concise queries are supported interchangeably:
agtool freetext query REPO 'plants|trees'
agtool freetext query REPO '(or plants trees)' If a query string is wrapped in paretheses, it will be treated as an s-expression query, otherwise the tool will try to parse it as a concise query. The result of a query command is a collection of matching triples and the supported output formats match those of a SPARQL's DESCRIBE query.
Solr text indexing
Text indexing using Apache Solr is described the document Solr text indices. In that document, we go into some detail about whether to use the native AllegroGraph freetext indexing or to use Solr. In short (again, see Solr text indices for full details), the native freetext indexer is faster, has a simpler API, and does not require synchronization between the indexer and the database (Solr runs as as a separate program and so has to be told about changes to the database). The native indexer is sufficient for many purpose. Solr has the advantage of using a powerful public product which is always being improved.