Introduction
See the document Large Language Models (LLM) and Vector Databases for general information about Large Language Model support in AllegroGraph.
See the document LLM Embed Specification for definitions of embedding and vector database. In order to create embeddings from arbitrary text documents, we generally want to parse or split the document into smaller text chunks, called windows. We want the individual windows to be large enough to contain meaningful knowledge but small enough to fit under the token limits of the embedding model.
There are many types of documents to split (emails, web pages, PDF documents, Word documents, LaTex documents, and plain text files, to name a few) and many ways to split them (detecting sentences, paragraphs, sections, subsections, and scanning windows over the text, to name a few of those). In this release we provide only 2 types of splitting, by number of characters or number of lines, and only for plain text (.txt) files.
A window is specified by a size and an overlap. The units of size and overlap are in characters or lines, depending on the type of split applied. The splitting function scans the document and windows containing chunks of text of the given size.
We can think of window splitting as more like human reading than document parsing. A window is what the eye can view: a word surrounded by other words in a sentence surrounded by a few other sentences. The eye doesn't care whether its viewing window begins or ends on a word or a sentence or even inside a word. The attention is focused on the sentence in the middle. We scroll our window over the entire document sequentially, just like a person reading the document from top to bottom.
You start with a text file of interest and you create a new, empty repository. Then you give instructions to split the text into triples and those triples are stored in the repository. Once the repo of split text triples has been created, a vector database can be created from that repo which can be queried.
The US Constitution as an example
We will use the United States Constitution as an example. We do not supply this but easily downloadable from many sources including https://constitutioncenter.org/the-constitution/full-text. In this document, we assume you have downloaded a copy into the file usc.txt.
Giving instructions for splitting a text document
LLM split instructions can be specified in two ways:
Using the WebView text split command, described below in the section Using WebView to split text.
Creating a split instruction file (or simply using the defaults) and calling agtool with the command llm split and additional arguments. See Splitting with agtool.
Using WebView to split text
You can use a dialog in WebView to split text. We assume you have the United States Constitution saved as a text file named usc.txt.
Create a repo (we name it usc) and open it in WebView. Choose Add, delete & import data from the repository menu on the left so this page is displayed:

Click on the Import text file as triples link and this page is displayed:
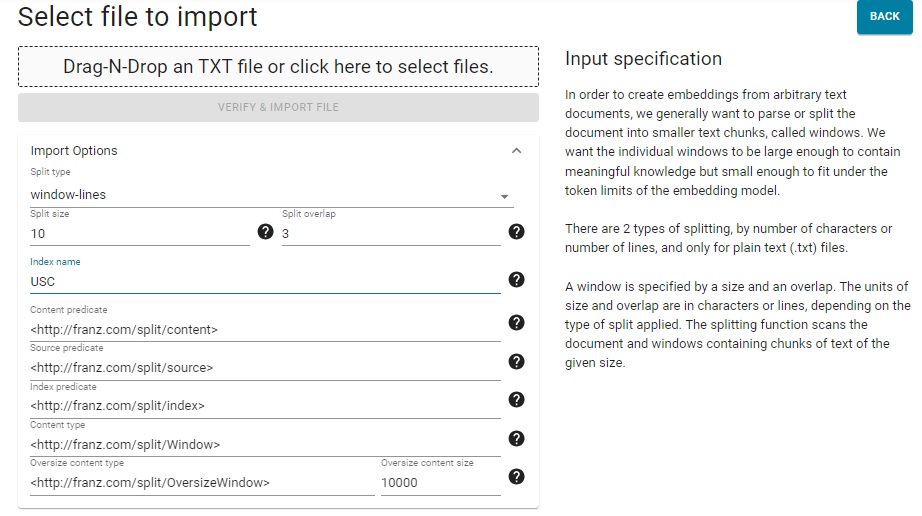
Fill in the Import Options fields, whose meanings are described in the tables in the section below. There are many fields but, at least when starting out, the defaults can be accepted for almost all. For the example detailed below, specify the Index name only: usc. The text file to split is specified by dragging it into the Drag-N-Drop box or by using a file select dialog. We click VERIFY & IMPORT FILE to complete the process. (The example has just one text file but as many as you wish can be specified.)
Splitting with agtool
There is a command-line option for splitting text, using the agtool command tool. (Note agtool is not available with AllegroGraph.cloud.)
The instructions for splitting text are given in an optional file in lineparse format with the extension .def. If a split specification file is not provided, the splitting uses the default values shown in the table below.
Here is the agtool command line for splitting. One or more files containing the text to split are given as the last arguments:
agtool llm split [--split-spec split.def] reponame file.txt ... In the US Constitution example, here is the .def file which we name usc.def:
split
split-type window-lines
split-size 10
split-overlap 3
index-name usc
content-predicate <http://franz.com/split/content>
source-predicate <http://franz.com/split/source>
index-predicate <http://franz.com/split/index>
content-type <http://franz.com/split/Window>
oversize-content-type <http://franz.com/split/OversizeWindow>
oversize-content-size 10000 In fact all values in that file are defaults except index-name usc. We wanted to show the general form of the file. So the command line for this example is (see Repository Specification for how to specify a repository in an agtool command line):
agtool llm split --split-spec usc.def [usc-repo-spec] usc.txt See the Practical example for more details.
Lineparse items in .def specification file
Instructions for splitting text are either specified in the dialog displayed in WebView or in a .def file in lineparse format that is used by agtool. There are defaults for all values. When using agtool the split specification lineparse file is optional. Omitting it entirely results in the splitter choosing the default values shown in the table below. Omitting a specific item results in the splitter using the default for that value. Thus having no line for split-overlap results in split-overlap having the default value of 3.
| item | min | max | required | default |
|---|---|---|---|---|
| split-type | 0 | 1 | no | window-lines |
| split-size | 0 | 1 | no | 10 |
| split-overlap | 0 | 1 | no | 3 |
| index-name | 0 | 1 | no | windowIndex |
| content-predicate | 0 | 1 | no | <http://franz.com/split/content> |
| source-predicate | 0 | 1 | no | <http://franz.com/split/source> |
| index-predicate | 0 | 1 | no | <http://franz.com/split/index> |
| content-type | 0 | 1 | no | <http://franz.com/split/Window> |
| oversize-content-type | 0 | 1 | no | <http://franz.com/split/OversizeWindow> |
| oversize-content-size | 0 | 1 | no | 10000 |
split-typecan bewindow-linesorwindow-chars.split-sizeis the length of each window, in lines (ifsplit-typeiswindow-lines) or characters (ifsplit-typeiswindow-chars).split-overlapis the amount of overlapping text between windows. Its value must be strictly less thansplit-size.index-nameis the name used to form an indexed identifier (subject) for each text chunk window, e.g using the default value:<http://franz.com/split/WindowIndex-0>source-predicateis a predicate to link the split text chunk to its source filename.content-typeidentifies the type of the split text content, useful later for selecting split text for embedding.oversize-content-typeandoversize-content-size: The concept of "oversize" applies to window text chunks that may have too many characters for the LLM's embedding token limit. If a window size exceedsoversize-content-sizecharacters, then the split text window has typeoversize-content-type. (In earlier vesions of the 8.1.1 documentation, this value was incorrectly namedoversize-content-limit.oversize-content-sizeis the correct name.)
for the first indexed window.
Practical Example
We have given partial instructions on splitting the text of the US constitution in the discussion above. We repeat the steps here showing the two methods.
Splitting Using WebView
This method must be used when running AllegroGraph.cloud and is optional when running a locally installed AllegroGraph server.
Create a repository named
usc(Choose a catalog from the list on the left, one typically choosesroot; click on the Create Repository button on the upper right, specify the nameusc. If the repo already exists, delete all its triples.)Open the
uscrepo and click on Add, delete, & import data from the Repository menu on the left.Click on the Import text file as triples choice. This page is displayed:
- Specify
uscas the index name (already done in the illustration). All other values are defaults. Drag-N-Drop usc.txt into the import box (or use a file selection tool) and click Verify and Import File.
After processing completes, split text triples will be stored in the usc as described below.
Splitting Using agtool
Suppose we have an Allegrograph running on localhost:10035 and we have a file usc.txt that contains the United States Constitution (again. we do not supply this but easily downloadable from many sources including https://constitutioncenter.org/the-constitution/full-text).
We write the split specification file usc.def as follows:
split
split-type window-lines
split-size 10
split-overlap 3
index-name usc
content-predicate <http://franz.com/split/content>
source-predicate <http://franz.com/split/source>
index-predicate <http://franz.com/split/index>
content-type <http://franz.com/split/Window>
oversize-content-type <http://franz.com/split/OversizeWindow>
oversize-content-size 10000 Note that this configuration contains the default value for each lineparse item, except for index-name. So we could just as well have written the file as:
split
index-name USC This configuration tells the splitter to use the window-lines splitting method (split the file by lines); the size of each window is 10 lines, with an overlap of 3 lines between adjacent windows. The splitter will create triples with a unique subject ID based on the index-name. The index-predicate will link each ID to an integer index value. The source-predicate will associate each ID to the filename usc.txt (identified when agtool llm split ... is run, see below). The content-predicate links the ID to the text content within the splitting window. The content-type assigns a type to each ID.
The US Constitution is a relatively short document and the selected window sizes are small, so the concept of "oversize" does not come into play in this example. First, we create a destination repository to store the split text (replace localhost:10035 with your actual host and port, if different and http with https if that is how the store was set up):
% agtool repos create http://localhost:10035/repositories/usc --supersede We now run
agtool llm split --split-spec usc.def http://localhost:10035/repositories/usc usc.txt This inserts triples into the repository usc, representing text chunk windows, all with ten lines except the last one, containing text split from the document.
Once splitting is complete
Here are some sample RDF triples resulting from the splitting (output somewhat rearranged for ease of viewing).
<http://franz.com/split/USC-26> <http://franz.com/split/content>
"The Congress shall have power to enforce this article by appropriate legislation.
27th Amendment
No law, varying the compensation for the services of
the Senators and Representatives, shall take effect, until an election
of Representatives shall have intervened.
"
<http://franz.com/split/USC-26> <http://franz.com/split/index> "26"^^<http://www.w3.org/2001/XMLSchema#integer>
<http://franz.com/split/USC-26> <http://franz.com/split/source> "usc.txt" This repo is suitable for embedding as described next.
Embedding split text
To see how the splitting works in relation to retrieval augmented generation (RAG), let's see what happens when we embed the split text. See the document LLM Embed Specification for a description of embedding and definitions of the index specification lineparse items. The embedding process creates a vector database associated with the split text repo usc we have created.
We can embed with WebView, described next, and with agtool. When running AllegroGraph.cloud you must use WebView.
Embedding with WebView
When the usc repo is open, open the Repository control menu and select Create LLM Embedding:
Fill in the dialog, as shown using the following values (see the document LLM Embed Specification for definitions of the index specification items):
- New of existing vector database:
usc-vec. - If Vector Database exits: supersede
- Limit: 1000000
- Embedded: openai
- Model: (this will fill in automatically)
- API key: enter your openaiApiKey.
- Include triples to index by predicate: http://franz.com/split/content
- Incluse triples to index by types: http://franz.com/split/Window
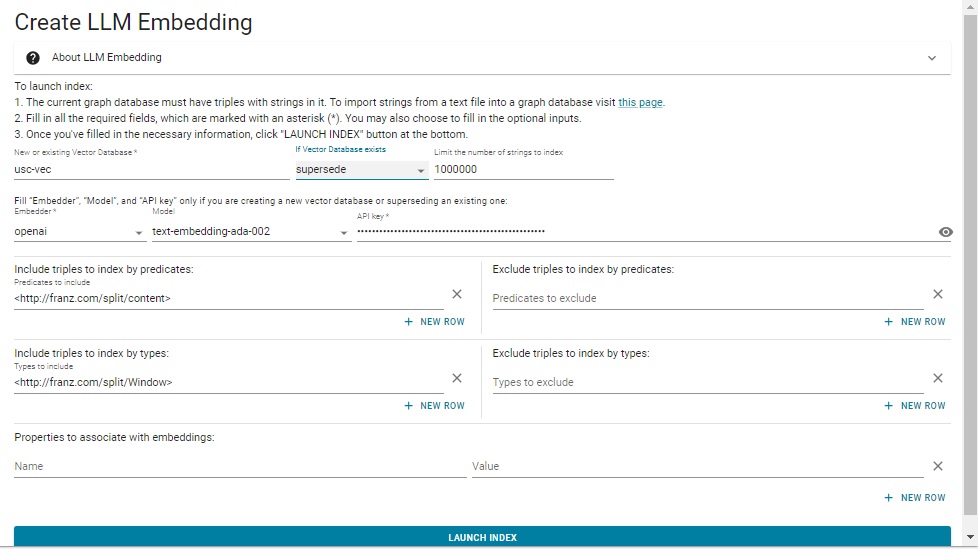
When ready, click Launch Index at the bottom. Creating the index may take some time. When it competes, you are ready to query the database.
Embedding with agtool
First, create an index specification file usc-vec.def (replace localhost:10035 if necessary):
embed
embedder openai
if-exists supersede
api-key "<api key goes here>"
vector-database-name localhost:10035/usc-vec
limit 1000000
splitter list
include-predicates <http://franz.com/split/content>
include-types <http://franz.com/split/Window> See the document LLM Embed Specification for definitions of the index specification lineparse items. This lineparse file creates a vector database called usc-vec. We add the embeddings to the vector database with (the --quiet argument supresses the voluminous output):
agtool llm index --quiet localhost:10035/usc usc-vec.def
Querying a vector database
Finally, after building the usc-vec vector database, we can test it with a query. You can run a query on the vector database from any repository, including the vector database itself, but generally we favor running it in the "knowledge" repository containing the split text, in this case usc.
Here is a sample query. Copy and paste it into the usc repo query page, or use agtool query as we describe below.
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/>
PREFIX franzOption_openaiApiKey: <franz:api key goes here>
SELECT ?response {
bind("Can a state have more than two senators, and if not, why?"
as ?query)
(?response ?score ?citation ?content) llm:askMyDocuments (?query "localhost:10035/usc-vec" 10 0.8).
} LIMIT 1 To use agtool, Place the SPARQL query above in a file query.rq. Then run the query in agtool.
agtool query http://localhost:10035/repositories/usc query.rq --output-format simple-csv And observe the response
"No, a state cannot have more than two senators.
This is outlined in the 17th Amendment of the U.S. Constitution,
which states that the Senate of the United States shall be composed
of two Senators from each State." Updating databases when documents are updated
The US constitution is rarely updated but many documents are revised from time to time. Suppose you have a text document mydoc-1.txt and you split it into a repository and create an associated vector database, as we have described in this document.
Then a revised version, mydoc-2.txt comes out. You can redo the splitting entirely (specify supersede in the If Vector Database exists field of the WebView dialog) and must do so if there are deletions as well as additions. But if there are only additions, you can just update the existing repo by specifying if-exists open in the .def file or specify open instead of supersede in the If Vector Database exists field of the WebView dialog. The embedder will skip embedding any strings already in the vector database. Skipping existing embeddings is much faster than redoing everything when processing additions. Only new text will be used to create new triples in the vector database.