Introduction
AllegroGraph supports multiple full-text indices, each targeted as narrowly as you like on specific fields of specific predicates.
These text indices are based on a locality-optimized Patricia trie, on which we do intelligent trie traversal for fast wildcard and fuzzy searches. The indexing process is fully transactional, and is able to easily handle billions of documents.
Solr text indexing
A text indexing based on Apache Solr is described the document Solr text indices. In that document, we go into some detail about whether to use the native AllegroGraph full-text indexing or to use Solr. In short (again, see Solr text indices for full details), the native full-text indexer is faster, has a simpler API, and does not require synchronization between the indexer and the database (Solr runs as as a separate program and so has to be told about changes to the database). The native indexer is sufficient for many purpose. Solr has the advantage of using a powerful public product which is always being improved.
Text-Indexing Features
You may experiment with full-text indices through AGWebView. Indices may be created, profiled, and used through AGWebView and through the Lisp, Python or Java client APIs. The Lisp function for creating full-text indices is create-freetext-index. The Lisp API is discussed here in the Lisp Reference Guide.
Each full-text index has a name, so you can apply it to a query or perform maintenance on it.
Each index works with one or more specific predicates, including an option to index all predicates.
An index can be configured to include:
- All literals, no literals, or specific types of literals.
- The full URI of a resource, just the local name of the resource (after the # or /), or ignore resource URIs entirely.
- Any combination of the four parts of a "triple:" the subject, predicate, object, and graph.
Stop words (ignored words) may be specified for each index, or the index can use a default list of stop words.
An index can make use of word filters such as stem.english, drop-accents, and soundex.
- stem.english: Provides stemming of English text.
- drop-accents: Normalizes non-English text by removing accented characters.
- soundex: Indexes words by how they sound, rather than how they are spelled.
Text searches may be conducted programmatically using AllegroGraph client APIs (Lisp, Python, Java) or as part of SPARQL and Prolog queries.
Text matches use "?" for single-character wildcards, and "*" for multi-character wildcards.
Text queries may use Boolean operators "and" and "or".
Double-quotes around a piece of text mean that AllegroGraph should search for an exact phrase.
AllegroGraph supports "fuzzy" matching using the Levenshtein distance algorithm. You can adjust the desired "distance" to achieve a harder focus (few matches) or a softer focus (many matches).
Ranking of search results reflects word frequencies, and in the case of fuzzy matches, the closeness of the match.
Indexing words in Japanese
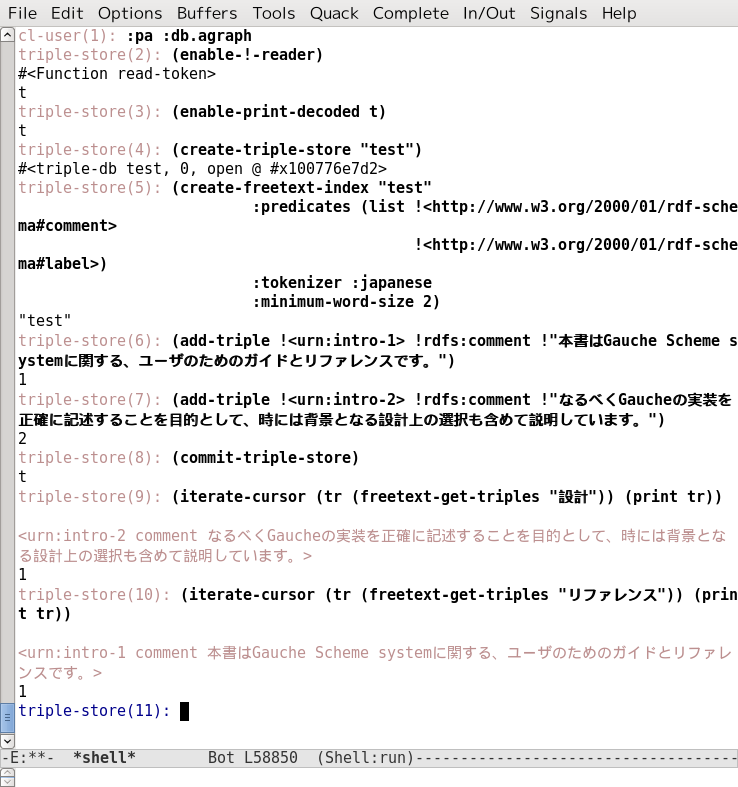
The :tokenizer keyword argument to create-freetext-index specifies the tokenizer to use. :default works for most European languages. :japanese specifies the Japanese language tokenizer, as the following screenshot shows:
Indexing CJK (Chinese/Japanese/Korean words)
The value :simple-cjk' for the :tokenizer` keyword argument to create-freetext-index indexes Chinese/Japanese/Korean (CJK) text. It uses bigrams for consecutive CJK characters as words. To use this tokenizer, specify :simple-cjk as the tokenizer option when creating or modifying a full-text index.
The bigram tokenizer can be used for CJK mixed text, but its simplicity may result in false positives. It also tends to index a much larger number of words compared to other tokenizers.