Introduction
Beginning in version 8.0.0 there is a new way to to specify the structure of a distributed repository. This new method allows one to define the layout of a distributed repository with an agtool command to a running server rather than the static agcluster.cfg file used previously. Thus this is a dynamic way to define a distributed repository.
In version 8.0.0 both methods of creating distributed repositories are supported however the old method is deprecated and will be dropped in a future version of AllegroGraph. The old method is described in Distributed Repositories Using Shards and Federation Setup.
See the Dynamic Distributed Repositories Using Shards and Federation Tutorial for a fully worked out example of a distributed repository.
A database in AllegroGraph is, at least at first, usually initially implemented as a single repository, running in a single AllegroGraph server. This is simple to set up and operate, but problems arise when the size of data in the repository nears or exceeds the resources of the server on which it resides. Problems can also arise when the size of data fits well within the specs of the database server, but the query patterns across that data stress the system.
When the demands of data or query patterns outpace the ability of a server to keep up, there are two ways to attempt to grow your system: vertical or horizontal scaling.
With vertical scaling, you simply increase the capacity of the server on which AllegroGraph is running. Increasing CPU power or the amount of RAM in a server can work for modest size data sets, but you may soon run into the limitations of the available hardware, or find the cost to purchase high end hardware is prohibitive.
AllegroGraph provides an alternative solution: a cluster of database servers, and horizontal scaling through sharding and federation, which combine in AllegroGraph's FedShard™ facility. An AllegroGraph cluster is a set of AllegroGraph installations across a defined set of machines. A distributed repository is a logical database comprised of one or more repositories spread across one or more of the AllegroGraph nodes in that cluster. A distributed repo has a required partition key that is used when importing statements. When adding statements to your repository, the partition key is used to determine on which shard each statement will be placed. By carefully choosing your partition key, it is possible to distribute your data across the shards in ways that supports the query patterns of your application.
Data common to all shards is placed in knowledge base repositories which are federated with shards when queries are processed. This combination of shards and federated knowledge base repos, called FedShard™, accelerates results for highly complex queries.
This diagram shows how this works:
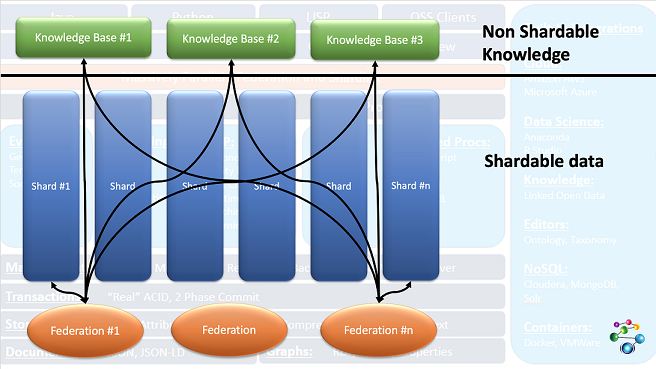
The three Knowledge Base repos at the top contain data needed for all queries. The Shards below contain partitionable data. Queries are run on federations of the knowledge base repos with a shard (and can be run of each possible federation of a shard and the knowledge bases with results being combined when the query completes). The black lines show the federations running queries.
The shards need not reside in the same AllegroGraph instance, and indeed need not reside on the same server, as this expanded images shows:
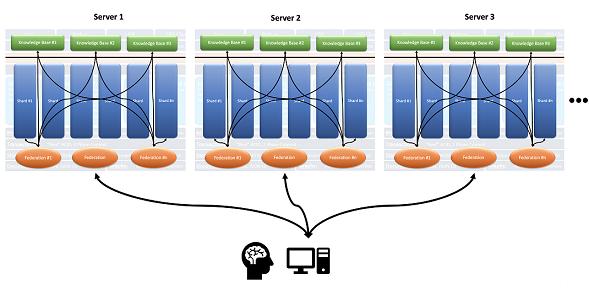
The Dynamic Distributed Repositories Using Shards and Federation Tutorial walks you through how to define and install to a cluster, how to define a distributed repo, and how various utilities can be used to manipulate AllegroGraph clusters and distributed repos.
This document describes all the options when setting up a distributed repo (the tutorial just uses some options). The last section, More information on running the cluster, has links into the Tutorial document where things like running a SPARQL query on a cluster are discussed.
The basic setup
You have a very large database and you want to run queries on the database. With the data in a single repository in a single server, queries may take a long time because a query runs on a single processor. At the moment, parallel processing of queries using multiple cores is not supported for a single repository.
But if you can partition your data into several logical groups and your queries can be applied to each group without needing information from any other group, then you can create a distributed repo which allows multiple servers to run queries on pieces of the data effectively in parallel.
Let us start with an example. We describe a simplified version of the database used in the tutorial.
The data is from a hospital. There is diagnosis description data (a list of diseases and conditions) and administration data (a list of things that can happen to a patient while in the hospital -- check in, check out, room assignment, etc.) and there is patient data. Over the years the hospital has served millions of patients.
Each patient has a unique identifier, say pNNNNNNNNN, that is the letter p followed by nine decimal digits. Everything that happened to that patient is recorded in one or more triples, such as:
p001034027 checkIn 2016-11-07T10:22:00Z
p001034027 seenBy doctor12872
p001034027 admitted 2016-11-07T12:45:00Z
p001034027 diagnosedHaving condition5678
p001034027 hadOperation procedure01754
p001034027 checkOut 2016-11-07T16:15:00Z This is quite simplified. The tutorial example is richer. Here we just want to give the general idea. Note there are three objects which refer to other data: condition5678 (broken arm), doctor12872 (Dr. Jones), and procedure01754 (setting a broken bone). We will talk about these below.
So we have six triples for this hospital visit. We also have personal data:
p001034027 name "John Smith"
p001034027 insurance "Blue Cross"
p001034027 address "123 First St. Springfield" And then there are other visits and interactions. All in all, there are, say, 127 triples with p001034027 as the subject. And there are 3 million patients, with an average of 70 triples per patient, or 210 million triples of patient data.
Suppose you have queries like:
- How many patients were admitted in 2016?
- How many patients had a broken arm (condition5678)?
- How many broken arm patients were re-admitted within 90 days?
- How many patients stayed in the hospital longer than 2 days?
All of those queries apply to patients individually: that is those questions can be answered for any patient, such as p001034027, without needing to know about any other patient. Contrast that with the query
- What was the next operation in the operating room where
p001034027was treated?
For that query, you need to know when p001034027 used the operating room and what was the next use, which would have been by some other patient. (In the simple scheme described, it is not clear we know which operating room was used and when, but assume that data is in triples not described, all with p001034027 as the subject.) This query is not, in its present form, suitable for a distributed repo since to answer it, information has to be collected from the shard containing p001034027 and then used in retirieving data from other shards.
So if your queries are all of the first type, then your data is suitable for a distributed repo.
Some data is common to all patients: the definition of conditions, doctors, and procedures. You may need to know these data when answering queries. Not if the query is How many patients were diagnosed with condition5678?' but if it is How many patients had a broken arm? as the latter requires knowing that condition5678` is a broken arm. Thus, triples like
condition5678 hasLabel "broken arm" are needed on all shards so that queries like
SELECT ?s WHERE { ?c hasLabel "broken arm" .
?s diagnosedHaving ?c . } will return results. As we describe, we have an additional repository. the kb (knowledge base) repo which is federated with all shards and provides triples specifying the general taxonomy and ontology.
Resource requirements
The Memory Usage document discusses requirements for repos. Each shard in a distributed repo is itself a repo so each must have the resources discussed in that document.
Also distributed repos use many file descriptors, not only for file access but also for pipes and sockets. When AllegroGraph starts up, if the system determines that there may be too few file descriptors allowed, a warning is printed:
AllegroGraph Server Edition 8.0.0
Copyright (c) 2005-2023 Franz Inc. All Rights Reserved.
AllegroGraph contains patented and patent-pending technologies.
Daemonizing...
Server started with warning: When configured to serve a distributed
database we suggest the soft file descriptor limit be 65536. The
current limit is 1024.
The distributed repository setup
A distributed repo has the following components:
A set of one or more AllegroGraph servers. Each server is specified by a host, a scheme (i.e.
httporhttps), and a port. Those three elements uniquely define the server. In the new Fedshard system the user is responsible for installing and starting the servers. They will not be automatically installed. This then offers greater flexibility in where the servers are installed on each machine.A distributed repo. This is a special type of repository. It is specified in a file in lineparse format and then that definition is made know to the server by running
agtool fedshard define myfile.txt. The repo will appear to be located in the pseudo catalogfedshardthus distributed repomydbis named in create and open commands withfedshard:mydbIt appears as a repository on each cluster server but does not itself contain triples. Instead it contains information about the cluster (the servers, the shards, and so on) which is used by the server to manage queries, insertions, and deletions. Queries applied to the distributed repo are applied to each shard and the results and collected and returned, perhaps after some editing and further modification. Distributed repos are created using specifications in a lineparse formatted file. (To be clear about terminology: the distributed repo definition is the whole complex specified in a lineparse file file: shards, kb repositories, and the distributed repo.)A set of cluster shards. A shard is a special type of repository. Shards are named implicitly in a lineparse formatted file. Shards are created when a distributed repo is created using specifications in definition of the distributed repo which has already be loaded into the server using
agtool fedshard define myfile.txt. Once defined the definitions are persistent and need not be loaded in each time the server startsA partition key. The key identifies which triples belong in the same shard. The key can be a part or attribute. If the key is part then the secondary-key is
subject,predicate,object, orgraph. If the key is attribute then the secondary-key is an attribute name (see the Triple Attributes document). If it is a part, all triples with the same part value are placed in the same shard (all triples have a graph even if it is the default graph so if the key is part and the secondary-key is graph, all triples with the default graph go into the same shard, all with graph XXX into the same shard, and so on). For key attribute and all triples with the same value for the attribute name given as the secondary-key will go into the same shard.The common kb repository or repositories. These are one or more ordinary repositories which will be federated with each shard when processing a SPARQL query. They are specified in the lineparse formatted distributed repo wdefinition file. In general triples can be added and deleted in the usual manner and queries can be executed as usual unrelated to the distributed repo. (When a query is run on a distributed repo, the common kb repositories are treated as if read only and so calls to delete triples or SPARQL-DELETE clauses will not delete triples in these common kb repos.) You can have as many common repos as you like and need not have any.
Keep these requirements in mind in the formal descriptions of the directives below.
The fedshard definition file
In the old distributed repository implementation the user edited the agcluster.cfg file to describe all distributed repositories. In the new system the user defines the repositories in a file (with any name, we use definition.txt in the example below) in lineparse format and then installs the definition on the server with this agtool command
agtool fedshard define definition.txt Once the definition is installed on the server the file definition.txt in lineparse format is not needed and may be discarded.
The syntax for the fedshard definition file is described here.
You can redefine a fedshard repo definition by passing the --supersede argument in the agtool fedshard define command. You should not redefine a fedshard repo if that repo already exists on the server. That is not supported as it usually will result in the assignments of triples to shards to change resulting in some triples becoming inaccesible.
The only repo configution change permitted for an existing fedshard repo is the splitting of a shard. If a shard gets too big you can tell AllegroGraph to split it into two shards using agtool fedshard split-shard. This should only be done when no process has the database open since you want all processes to have an up to date configuration when they access the repo.
Using agtool utilities on a distributed repository
The agtool General Command Utility has numerous command options that work on repositories. Most of these work on distributed repos just as they work on regular repositories. But here are some notes on specific tools.
Using agtool fedshard on a distributed repository
We will demonstrate the agtool commands you'll find useful when working with distributed repos.
We will begin with a very simple four shard distributed db with all shards on a server listening on port 20035 for HTTP connections
% cat sample.def
fedshard
repo mydb
key part
secondary-key graph
host 127.1 ; port 20035
user test; password xyzzy
server
host 127.1
shards-per-server 4
We specify the server that should be given the definition
% agtool fedshard define --server test:[email protected]:20035 sample.def
Defined mydb It's an error to attempt to define a distributed repo that's already defined unless you add the --supersede option on the command line. Note that it is a bad idea (and often a fatal bad idea) to redefine a distributed repo that already has been created. Then the agraph server will likely get confused about where the shards are located.
We can verify that the definition has been made
% agtool fedshard list --server test:[email protected]:20035
| Name | Shard Count |
|------|-------------|
| mydb | 4 |
And we can use agtool repos to create all of the shards of the distributed repo bringing the distributed repo into existence..
% agtool repos create test:[email protected]:20035/fedshard:mydb
This time we ask to list just our mydb repo which will give us more details since we refer to a single repo. We also add --count and we will see the number of triples in each shard:
% agtool fedshard list --server test:[email protected]:20035 --count mydb
Name: mydb
Key: part
Secondary Key: graph
Servers:
| Server ID | Scheme | Host | Port | User | Catalog | Shard Count |
|-----------|--------|-------|-------|------|---------|-------------|
| 0 | http | 127.1 | 20035 | test | root | 4 |
Shards:
| Shard ID | Server ID | Repo | Count |
|----------|-----------|-------------------|-------|
| 0 | 0 | shard-mydb-s0-sh0 | 0 |
| 1 | 0 | shard-mydb-s0-sh1 | 0 |
| 2 | 0 | shard-mydb-s0-sh2 | 0 |
| 3 | 0 | shard-mydb-s0-sh3 | 0 |
Since we've just created the repo there are no triples. We load in some sample data that has values in the graph node (as we are splitting into shards based on the graph value)
% agtool load test:[email protected]:20035/fedshard:mydb somedata.nquads
2023-03-30T13:58:13| Processed 0 sources, triple-count: 520,147, rate: 54363.19 tps, time: 9.57 seconds
2023-03-30T13:58:18| Load finished 1 source in 0h0m15s (15.53 seconds). Triples added: 1,000,000, Average Rate: 64,408 tps.
Now when we list we'll see actual counts of triples in each shard. The first shard will always have fewer triples than other shard as we do not allow the first shard to be split.
% agtool fedshard list --server test:[email protected]:20035 --count mydb
Name: mydb
Key: part
Secondary Key: graph
Servers:
| Server ID | Scheme | Host | Port | User | Catalog | Shard Count |
|-----------|--------|-------|-------|------|---------|-------------|
| 0 | http | 127.1 | 20035 | test | root | 4 |
Shards:
| Shard ID | Server ID | Repo | Count |
|----------|-----------|-------------------|--------|
| 0 | 0 | shard-mydb-s0-sh0 | 1039 |
| 1 | 0 | shard-mydb-s0-sh1 | 332638 |
| 2 | 0 | shard-mydb-s0-sh2 | 333070 |
| 3 | 0 | shard-mydb-s0-sh3 | 333253 |
These shards have very few triples in them so you would not be tempted to split one but just as a demonstration we'll show how to split one of the shards into two new shards. The table above assigns each shard a shard ID. We'll split shard number 2
% agtool fedshard split-shard test:[email protected]:20035/fedshard:mydb 2
and now list the counts to see that shard 2 is gone and we now have shards 4 and 5.
% agtool fedshard list --server test:[email protected]:20035 --count mydb
Name: mydb
Key: part
Secondary Key: graph
Servers:
| Server ID | Scheme | Host | Port | User | Catalog | Shard Count |
|-----------|--------|-------|-------|------|---------|-------------|
| 0 | http | 127.1 | 20035 | test | root | 5 |
Shards:
| Shard ID | Server ID | Repo | Count |
|----------|-----------|---------------------|--------|
| 0 | 0 | shard-mydb-s0-sh0 | 1039 |
| 1 | 0 | shard-mydb-s0-sh1 | 332638 |
| 3 | 0 | shard-mydb-s0-sh3 | 333253 |
| 4 | 0 | shard-mydb-s0-sh2-0 | 167127 |
| 5 | 0 | shard-mydb-s0-sh2-1 | 165943 |
Unless the old distributed system the shard repos are not hidden. If you ask to see all the repo names you will see the shards too:
% agtool repos list test:[email protected]:20035
| REPO | CATALOG | TYPE |
|---------------------|----------|------|
| shard-mydb-s0-sh0 | root | - |
| shard-mydb-s0-sh1 | root | - |
| shard-mydb-s0-sh2 | root | - |
| shard-mydb-s0-sh2-0 | root | - |
| shard-mydb-s0-sh2-1 | root | - |
| shard-mydb-s0-sh3 | root | - |
| mydb | fedshard | - |
| system | system | - |
The delete command for the distribute repo will delete all the shards:
% agtool repos delete test:[email protected]:20035/fedshard:mydb The shard that was split is no longer considered part of the repo so it doesn't get deleted:
% agtool repos list test:[email protected]:20035
| REPO | CATALOG | TYPE |
|-------------------|---------|------|
| shard-mydb-s0-sh2 | root | - |
| system | system | - |
You can tell the server to forget a definition exists:
% agtool fedshard delete-definition test:[email protected]:20035/fedshard:mydb and then you can confirm that the definition no long exists
% agtool fedshard list --server test:[email protected]:20035
| Name | Shard Count |
|------|-------------|
Using agtool export on a distributed repository
agtool export (see Repository Export) works on distributed repos just like it does with regular repositories. All data in the various shards of the distributed repo is written to a regular data file which can be read into a regular repository or another distributed repo with the same number of shards or a different number of shards. (Nothing in the exported file indicates that the data came from a distributed repo).
The kb (knowledge base) repos associated with a distributed repo are repos which are federated with shards when SPARQL queries are being processed. kb repos are not exported along with a distributed repo. You must export them separately if desired.
Using agtool archive on a distributed repository
The agtool archive command is used for backing up and restoring databases. For backing up, it works similarly to backing up a regular repo (that is, the command line and arguments are essentially the same).
A major difference is that the backup actually consists of a sequence of backups, one of each shard. This is invisible to the user.
When restoring a distributed repo backup one must restore it to a pre-defined distributed repo with the exact same number of shards and those shards must have the same topology. For example if you create a distributed repo of four shards, split the third shard, and then do a backup of the five shards then you can only restore this backup into a distribute repo that started with four shards with the third shard then split.
For this reason if the distibuted repo has had shards split it's often easier to export the whole repository to an ntriple or nquad file and then it can be imported into a distributed repository of any structure.
Upgrading to a new version
Upgrading to a new version is described in the Repository Upgrading document. It works with distributed repos as with regular repos with the exception that the later version must have a sufficiently similar agcluster.cfg file, with the same servers and specifications for existing distributed repos as the older version.
Distributed repos in AGWebView
New WebView and traditional AGWebView are the browser interfaces to an AllegroGraph server. For the most part, a distributed repo looks in AGWebView like a regular repo. The number of triples (called by the alternate name Statements and appearing at the top of the Repository page) is the total for all shards and commands work the same as on regular repos.
You do see the difference in Reports. In many reports individual shards are listed by name. (The names are assigned by the system and not under user control). Generally you do not act on individual shards but sometimes information on them is needed for problem solving.
More information on running the cluster
See the Dynamic Distributed Repositories Tutorial using Shards and Federation Tutorial for information on using a cluster once it is set up. See particularly the sections:
SPARQL on a Distributed versus Federated Repository and also the Running SPARQL section.