Overview
AllegroGraph is a database and application framework for building Enterprise Knowledge Graph solutions based on a high performance triple store.
Data and metadata can be managed using Java, Python, Lisp and HTTP interfaces, and queried using SPARQL and Prolog. AllegroGraph comes with Social Network Analysis, geospatial, temporal and reasoning capabilities.
AllegroGraph FedShard™ is our newest feature offering massive horizontal scalability.
The following diagram shows the AllegroGraph architecture:
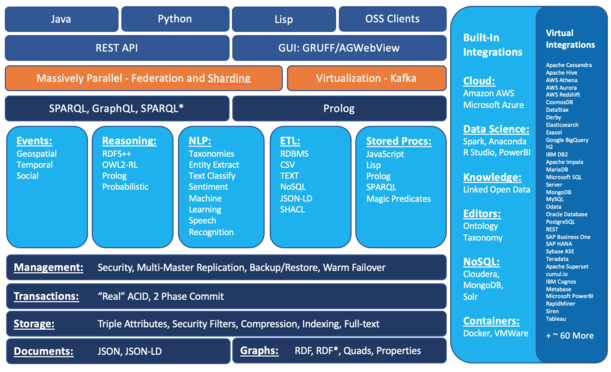
Graph Database
AllegroGraph is optimized for storing and retrieving information that has a graph structure, like:
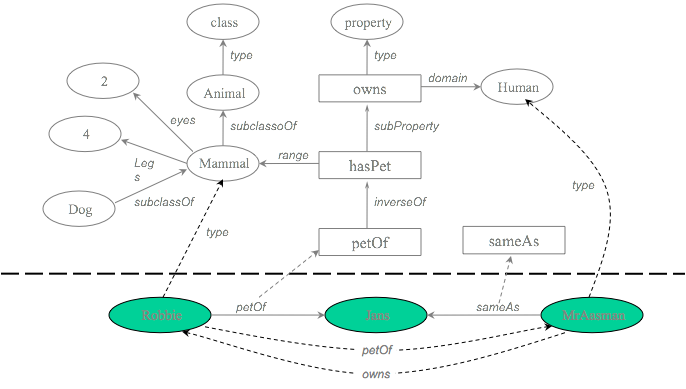
The figure above represents concrete statements about people and their animals represented as nodes and directed edges:
Jans is a human
Robbie is a pet of Jans
Jans is also called Mr. Aasman and in addition there are statements about concepts:
"is the pet of" is the inverse of "has pet"
A dog is a kind of mammal It's easier to store and query such information in a graph database than in a relational database (RDBMS) because:
you can add new predicates without changing any schema, providing you with flexibility and adaptablility in data modeling;
one-to-many and many-to-many relations are modeled directly, instead using intermediate tables;
in query languages like SPARQL the graph relations to search for are expressed directly, rather than in terms of join as in SQL;
all relations are indexed leading to very efficient edge traversal.
RDF, Quads, Properties
The W3C has standardized on the Resource Description Framework (RDF) as a way to model information as nodes and edges. Statements are written as triples of the form:
{ <subject> <predicate> <object> } This can be thought of as: "<subject> has a property; the name of the property is <predicate>; and the value of the property is <object>".
There is an additional component that can be added to an assertion to provide context information. This component is called the graph:
{ <subject> <predicate> <object> <graph> } Even though assertions are now quads, they are still called triples. Here is a triple representation of the above information:
subject predicate object graph
----------------------------------------------
Jans Type Human Jans's home page
Robbie petOf Jans Jans's home page
Jans sameAs MrAasman Jans's home page
petOf inverseOf hasPet English grammar
Dog subClassOf Mammal Science AllegroGraph supports standards like RDF, RDFS, SPARQL and OWL.
Triple indices and freetext indices enable efficient query handling, and AllegroGraph also offers powerful geospatial reasoning, temporal reasoning and social network analysis.
AllegroGraph goes beyond RDF
AllegroGraph as a platform does not restrict the contents of its triples to pure RDF. In RDF the subject of a triple is a resource or blank node, and cannot be for example a string or number; and the predicate, must be a resource. AllegroGraph can be used as a non-RDF store where triples are added with e.g. a string as subject, and a number as predicate. Used this way, AllegroGraph becomes a powerful generic graph database. Instead of the SPARQL query language designed for RDF, you would implement database operations using the general features of AllegroGraph that manipulate triples.
Distributed and Federated Repositories
Data Center Coordination
AllegroGraph can be run on multiple servers in widely separated locations.
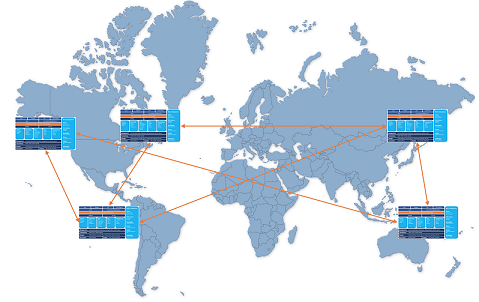
AllegroGraph supports MultiMaster Replication (MMR) which allows repositories in each data center to be synchronized so all see the same data (of course allowing for network communication time).
Handling Very Large Datasets using AllegroGraph FedShard™
AllegroGraph FedShard™ enables scaling using multiple repositories on multiple servers. A large datasets is partitioned into shards based on some classifying criterion, and each shard can have access to a common knowledge-base.
For example in a hospital setting all data relating to a specific patient would be assigned to the same shard. The knowledge base would include medical ontologies, stored in a separate repository.
Queries issued against the distributed repository are run in parallel on each of the shards and afterwards the results are combined. This unique data federation capability allows running highly complex queries across highly distributed datasets and knowledge bases very efficiently.
The following image shows how this works:
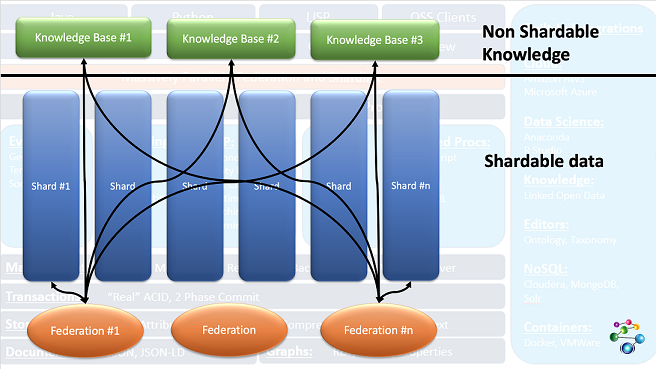
The three Knowledge Base repos at the top contain unshardable knowledge bases needed for all queries. The six shards below contain partitionable data. Each of the shards is federated with all knowledge bases. Queries are run in parallel on each of the federations. The black lines show how each shard is federated with the knowledge bases.
The shards need not reside in the same AllegroGraph instance, and indeed need not reside on the same server, as this expanded images shows:
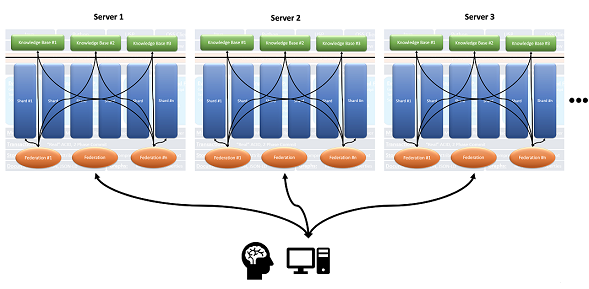
The Distributed Repositories Using Shards and Federation Tutorial has a fully worked out example showing how very large datasets of patient data can be broken into shards which reside on different AllegroGraph servers but are combined using AllegroGraph's FedShard™ capability to provide fast query results.
Triple Level Security
As RDF stores become more entrenched in enterprise applications, increased security and fine-grained data access control is required. To support this, AllegroGraph is an industry leader for data security via Triple Attributes and Security Filters.
There are many potential uses of triples attributes, including access control. Attributes can specify which users can access which triples. Users can also be given attributes, which can be compared to the triple attributes. Suppose for example there is an attribute named security-level with values high, medium and low. Then a user with security-level attribute medium can be prevented from viewing triples with security-level attribute high.
Because triples can have as many attributes as desired and attributes can have as many values as desired (there are configurable limits but the defaults are much larger than any conceivable application), access control can be as finely tuned as desired.
With Security Filters the system administrator is able to grant user access to the entire repository, or restrict access to a limited and filtered view of a repository.
Transactions
AllegroGraph implements the ACID properties of transaction processing (atomicity, consistency, isolation, and durability) similarly to other database products. This section describes the details of how these properties are implemented and what guarantees developers can expect.
Atomicity
The atomicity property defines that all updates within one transaction are persisted together. A transaction either completely fails or completely succeeds.
With AllegroGraph, when an application calls rollback, the changes that it has made to the triple store since the last commit or rollback are discarded. Likewise, when an application calls commit, all changes since the last commit or rollback are persisted. No partial transaction results will ever be seen by other clients of the database.
Consistency
The consistency property defines that every transaction takes the database as a whole from one consistent state to another. The database itself will never be inconsistent, according to its own consistency rules.
AllegroGraph does not allow for user-defined consistency rules (like, say, foreign key constraints in a relational database). That means that the database has no influence on the application-level consistency of the data stored in a triple store. It is up to the user to make sure that transactions create and maintain a consistent application-level state. At the same time, AllegroGraph guarantees that every commit operation will take the database from one consistent internal state to another consistent internal state.
It is possible for two concurrent transactions to attempt contradictory changes to triple store metadata, such as mapping the same predicate to two different datatypes, or defining the same freetext index using different parameters. The first transaction to commit will succeed normally. Those changes become visible to the second transaction when it attempts to commit. (No rollback is necessary.) AllegroGraph will signal metadata errors at that point, preventing the second transaction from committing.
Isolation
The isolation property defines that every transaction only sees data of other completed transactions, and not partial results of transactions running concurrently.
AllegroGraph implements the snapshot isolation model. In this model, every transaction sees a snapshot of the persistent database state as of the time when the transaction has been started by a commit or rollback operation. During the course of executing transaction code, other transactions can commit and change the persistent state without affecting the snapshot of this transaction. Once the transaction commits, any updates made by concurrent transactions will be made visible as part of the snapshot of the next transaction.
As no triple locking is performed by AllegroGraph, it is possible that a triple that is being read in a transaction could be deleted in a concurrent transaction. Developers need to be aware of this and similar possibilities and make sure that transactions are properly sequenced if such concurrent updates could have an impact on application-level consistency.
Durability
The durability property defines that once the database system signals the successful completion of a transaction to the application, the changes made by the transaction will persist even in the presence of hardware and software failures. (Obviously, the durability property cannot guarantee the persistence of data after a hard disk failure that destroyed data.)
When the commit operation of AllegroGraph returns, the database server will have written the updates made by the transaction to the transaction log and waited for the log I/O operation to finish. Therefore, the application can be sure that every committed transaction will have a permanent effect on the persistent database state.
Adding Triple Data
You can manage triple stores using several interfaces (e.g. Java, Python, Lisp and HTTP). Each interface provides functionality to create and open triple stores; import triple data; enable RDFS++ reasoning); query for triples that match simple or complex constraints; export triples in many formats; and understand and manage server performance.
AllegroGraph can load data in the following RDF formats:
as well as in several non-RDF formats, listed here. Data loading is described in the Data Import document. If your data is in a format that AllegroGraph does not support, you may be able to use the open source tool rapper to convert your data into a format that AllegroGraph can use.
You can also load triples into AllegroGraph programmatically. This can be used to import custom data formats, or to build a triple store incrementally. Triples can be added using e.g. RDF syntax or AllegroGraph's special encoded data-types. See e.g. Lisp functions add-triples, load-ntriples and load-turtle.
Programmatically added triples can also make use of the triple-id function to perform efficient reification.
Triple data is automatically added to triple indices and freetext indices to enable efficient query handling. There are options to control handling of duplicate triples.
Example of N-Triples data format
<http://franz.com/simple#Animal> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2002/07/owl#Class> .
<http://franz.com/simple#Mammal> <http://www.w3.org/2000/01/rdf-schema#subClassOf> <http://franz.com/simple#Animal> .
<http://franz.com/simple#Mammal> <http://franz.com/simple#eyes> "two" . Example of RDF/XML data format
<?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xml:base="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl="http://www.w3.org/2002/07/owl#">
<Description rdf:about="http://franz.com/simple#Animal">
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/>
</Description>
<Description rdf:about="http://franz.com/simple#Mammal">
<rdfs:subClassOf rdf:resource="http://franz.com/simple#Animal"/>
<ns1:eyes>two</ns1:eyes>
</Description>
</RDF> Querying the Database
SPARQL
SPARQL is the query language of choice for triple stores. AllegroGraph's SPARQL query engine adheres to the SPARQL 1.1 standard. For more information on using SPARQL with AllegroGraph, see the tutorial and SPARQL reference guide.
Triple queries
AllegroGraph provides numerous methods for retrieving triples from a triple store. The simplest is to ask for triples matching a pattern of subject, predicate, object and graph. Each part of the pattern can be an exact match, a range specifier, or a wild card (don't care). For example, the pattern:
subject : <http://www.example.com/people/jans>
predicate:
object :
graph : <http://www.example.com/context/initial> would retrieve all triples with subject jans from the graph named initial. We could retrieve someone's phone numbers using:
subject : <http://www.example.com/people/jans>
predicate: <http://www.example.com/telephone/>
object :
graph : and learn about everyone born in the first half of 1964 with:
subject :
predicate : <http://www.example.com/birth>
object-start : "1964-01-01"^^<http://www.w3.org/2000/01/XMLSchema#date>
object-end : "1964-06-30"^^<http://www.w3.org/2000/01/XMLSchema#date>
graph : You can use these pattern-based queries in your own programs to query triple stores at a level that is lower than e.g. SPARQL. The result is a triple cursor. See e.g. Lisp function get-triples.
AllegroGraph's other query interfaces such as SPARQL, Prolog and the RDFS++ reasoner all use triple cursors under the hood.
RDFS++ Reasoning
Description logic or OWL reasoners are good at handling (complex) ontologies, they are usually complete (give all the possible answers to a query) but have completely unpredictable execution times when the number of individuals increases beyond millions.
AllegroGraph's RDFS++ reasoning (see RDFS++ Reasoning) supports all the RDFS predicates and some of OWL's. It is not complete but it has predictable and fast performance. Here are the supported predicates:
- rdf:type and rdfs:subClassOf
- rdfs:range and rdfs:domain
- rdfs:subPropertyOf
- owl:sameAs
- owl:inverseOf
- owl:SymmetricProperty
- owl:TransitiveProperty
The reasoner tutorial provides a quick introduction of how each predicate behaves and describes the reasoner in more detail. AllegroGraph also includes an optional OWL restriction reasoning module that supports owl:hasValue, owl:someValuesFrom and owl:allValuesFrom (see the hasValue reasoning tutorial).
Prolog
Prolog is an alternative query mechanism for AllegroGraph. With Prolog, you can specify queries declaratively. The Prolog tutorial provides an introduction to using Prolog and AllegroGraph together.
Our Prolog is implemented in Lisp so for Lispers, the combination of Lisp, Prolog, and AllegroGraph are a natural triad. See the Lisp Reference.
You can also send Prolog queries to the server using e.g. Java or HTTP.
More on AllegroGraph Federation
We have already talked about federation in the context of querying very large databases using the FedShard™ facility. In this section, we give more details about federation in general.
AllegroGraph uses that same programming API for both stand-alone and federated triple stores. A federated store collects multiple AllegroGraph triple stores of any kind (local, remote, reasoning, etc) into a single read-only logical store that can be manipulated as if it were a simple local store.
Federation provides three big benefits:
- it scales,
- it makes triple stores more manageable, and
- it makes data archive almost trivial.
SPARQL federated queries
There is another kind of federation, namely by the use of SERVICE in a SPARQL query. This directs a portion of the original query to another SPARQL endpoint. This is a standard feature in SPARQL, and is fully supported by AllegroGraph. However it is independent from the concept of federating repositories.
Federation: Scalable triple stores
Since federation provides a natural mechanism to join disparate triple stores, we can use separate instances of AllegroGraph to load data on multiple CPUs and then combine them at query time. Loading triples is an extremely parallelizable task in that using N CPUs decreases the total time by a factor of N.
Federation: Data Management
AllegroGraph's federation mechanism and flexible triple store architecture combine to make it easy to connect multiple stores (in the same AllegroGraph instance, multiple AllegroGraph instances on the same machine, or multiple AllegroGraph instances on a cluster of machines) together and treat them as one. When a user creates an AllegroGraph federated repository, a virtual index of the constituent stores is created and maintained in the client session to facilitate intelligent query processing and maximum performance. For example, we can combine the dbPedia, the USGS Geonames database and Census information into a single virtual store and explore the interconnections between these datasets without worrying about where the triples originate. Even better, we can keep different kinds of triples separate and combine them as needed. E.g., we can keep known facts, inferred triples, provenance information, ontologies, metadata and deleted triples in separate, easily manageable stores and combine and re-combine the data as necessary.
Federation: Data warehousing
Enterprise data volumes are growing without bound making it essential to enable the accumulation and archiving of multi-billions of triples. Federation lets you segment your data into usable chunks that can be swapped in and out as needed.

The figure illustrates how an enterprise data center can use federation to easily work with the three most current months of data. Since federated data stores can be built easily and easily changed, it is just as simple to look at historical data whenever that is necessary.
See Complex Repository Specification in the Repository Specification document for more information on and examples of federation specification.
Advanced Capabilities
AllegroGraph supports several specialized datatypes for efficient storage, manipulation, and search of Social Network, Geospatial and Temporal information. AllegroGraph also supports the xsd:date, xsd:dateTime types, and the xsd:integer and xsd:decimal types.
Social Network Analysis
By viewing interactions as connections in a graph, we can treat a multitude of different situations using the tools of Social Network Analysis (SNA). SNA lets us answer questions like:
How closely connected are any two individuals?
What are the core groups or clusters within the data?
How important is this person (or company) to the flow of information
How likely is it that this person and that person know one another
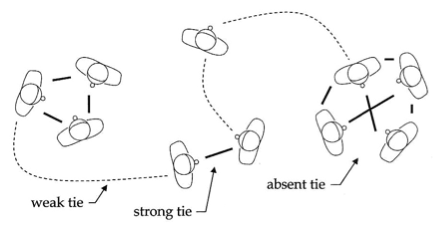
The field is full of rich mathematical techniques and powerful algorithms. AllegroGraph's SNA toolkit includes an array of search methods, tools for measuring centrality and importance, and the building blocks for creating more specialized measures.
Geospatial Primitives
AllegroGraph provides efficient handling of multi-dimensional data, in particular location data. We often refer to this kind of data as "geospatial", although that term refers specifically to positions on or around the earth's surface.
AllegroGraph supports a more general notion of N-dimensional ordinates systems where the user controls the precision. See the document N-dimensional Geospatial for a description and a tutorial on the new nD geospatial facility.
Temporal Primitives
AllegroGraph supports efficient storage and retrieval of temporal data including datetimes, time points, and time intervals:
- datetimes in ISO8601 format: "2008-02-01T00:00:00-08:00"
- time points: ex:point1, ex:h-hour, ex:when-the-meeting-began, etc
- time intervals: ex:delay-interval (say, from point ex:point1 to ex:h-hour)
Once data has been encoded, applications can perform queries involving a broad range of temporal constraints on data, including relations between:
- points and datetimes
- intervals and datetimes
- two points
- two intervals
- points and intervals
See the temporaral magic properties for more information.
Freetext Indexing
AllegroGraph can build freetext indices of the strings of the objects associated with a set of predicates that you specify. Given a freetext index, you can search for text using:
- boolean expressions ("market" AND "housing")
- wild cards ("science*" OR "math*")
- phrases ("Semantic Web search")
See Freetext Indices for more information.
Replication in AllegroGraph
AllegroGraph Replication is a real-time transactionally consistent data replication and data synchronization solution (replication is making new copies and synchronization ensures existing copies are updated to be identical). It allows businesses to move and synchronize their semantic data across the enterprise. This facilitates real-time reporting, load balancing, disaster recovery, and high availability configurations. It assists organizations in mission critical challenges, such as managing liability or fraud, eliminating the risk of distributed enterprise scale environments, and reducing the costs.
AllegroGraph replication is documented in Replication.
Programming AllegroGraph
AllegroGraph comes in multiple flavors and works with multiple programming languages and environments.
- Java
- The Java client interface implements most of the RDF4J and Jena interfaces for accessing remote RDF repositories. Because AllegroGraph provides functionality not found in other triple stores, we have implemented extensions where applicable. See the pre-release Jena page for information on our Jena support. (See the tutorial and Javadocs for more information). Note that Java 8 (or later) is required for the java client.
- Python
- The Python API offers convenient and efficient access to an AllegroGraph server from a Python-based application. This API provides methods for creating, querying and maintaining RDF data. The Python tutorial provides an overview of the API.
- HTTP
- It is now possible for web developers and programmers alike to interact with AllegroGraph 7.3.1 completely using a RESTful HTTP protocol (using GET, PUT, POST) to add and delete triples, to query for individual triples and to do SPARQL and Prolog selects using the Sesame 2.0 HTTP-interface with some extensions. See REST/HTTP interface and HTTP reference for more information.
- Javascript
- The AllegroGraph RDF server can be scripted using the JavaScript language. The easiest way to get started with this is to open a repository in WebView and select 'Utilities->Scripts' from the navigation bar. Javascript documentation is in JavaScript. Browser-based Javascript applications may interact with AllegroGraph using the HTTP interface. It might be necessary to configure cross-origin resource sharing (CORS) on the server due to same-origin policy (SOP) restrictions enforced by web browsers. See here in the REST/HTTP interface document for more information. The configuration options necessary to enable CORS are described here in the Server Configuration and Control document.
- Lisp
- Lisp programmers can open and use triple stores from within Lisp. Lispers can create applications in the same image that the AllegroGraph server is running or use a
remote triple storeto access data in client/server mode. See Lisp Quickstart and Lisp Reference for more information.
3rd-party Integration
AllegroGraph works with various other database tools, some of which organize data stores and others of which provide specialized indexes. Here are some of the tools provided by other sources and vendors which work with AllegroGraph:
- PoolParty
- PoolParty Semantic Suite is the most complete and advanced semantic middleware platform on the global market. It uses innovative means to help organizations build and manage enterprise knowledge graphs as a basis for their AI strategy.
- Cloudera
- Cloudera provides Apache Hadoop tools. AllegroGraph supports loading files from Hadoop Distributed File Systems,such as supplied by Cloudera.
- MongoDB
- MongoDB is a cross-platform document-oriented NoSQL database. See MongoDB integration for information on AllegroGraph's integration with MongoDB.
- Apache Solr
- Apache Solr is an open-source freetext indexing/searching platform from the Apache Lucene project. Lucene is a Java Based Freetext Indexer with many features. Solr is an XML database wrapper around Lucene. See Solr text Indices.
- Top Braid Composer
- Top-Braid Composer (TBC), a product of TopQuadrant, Inc., is a graphical development environment for modeling data, connecting data sources, and designing queries, rules and semantic data processing chains. See TopBraid Composer Plugin.
- Anaconda
- Anaconda® is a data science platform consisting of a package manager, an environment manager, a Python distribution, and a collection of open source packages. See AllegroGraph and Anaconda for information on AllegroGraph's integration with Anaconda.
- Racer
- AllegroGraph includes its own RDFS++ reasoner. If more powerful reasoning is required, AllegroGraph can integrate with Racer and its full description logic.
AllegroGraph Documentation
The AllegroGraph website is allegrograph.com. AllegroGraph is a product of Franz Inc..
Documentation for AllegroGraph is available at
http://franz.com/agraph/support/documentation/<version>/ where <version> is vX.Y[.Z], 7.3.1 for the current version.
There is a search tool in the upper left corner of each documentation page. That tool uses Google to search for the desired phrase in the documentation on the Franz Inc. website noted just above. That means that even if you have a local copy of the documentation, the search is done on the web copy.
http://franz.com/agraph/support/documentation/current/ always links to the documentation for the latest release.
AllegroGraph examples
See the AllegroGraph examples document. Some examples can be found in tutorial/ subdirectory of the installation directory (that is, the directory into which AllegroGraph is installed). Further examples can be found in the franzinc/agraph-examples repository on Github, among them examples which focus on infrastructure as code, automating distributed databases, and examples of using multi-master replication clusters for load balancing.