








AllegroGraph RDFStore TM
AllegroGraph RDFStore is a modern, high-performance, persistent RDF graph database. AllegroGraph uses disk-based storage, enabling it to scale to billions of triples while maintaining superior performance. AllegroGraph supports SPARQL, RDFS++, and Prolog reasoning from Java applications.
AllegroGraph RDFStore Architecture
There are many ways to work with AllegroGraph:
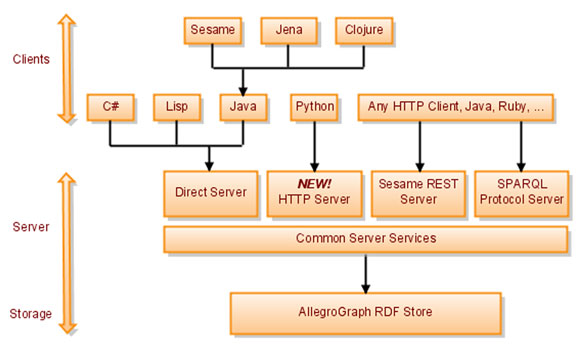
- Java. There are several ways to work with AllegroGraph from Java: we supply Java classes that allow direct access to all the features of AllegroGraph; we also supply adapters that allow access through Jena library calls, and through Sesame 2.x library calls. Another way is through the HTTP facilities in the next paragraph.
- Sesame HTTP client protocol. It is possible for developers to interact with AllegroGraph using the Sesame 2.1 HTTP protocol to add and delete triples, to query for individual triples and to do SPARQL and Prolog selects. We extended the protocol so that it can do additional database management functions.
- Python, Ruby, JavaScript, etc. The HTTP interface can be used from any language that knows how to make HTTP client requests. This way, you can easily use AllegroGraph from Ruby, Python and many other languages.
- Lisp. The AllegroGraph client API is another view of the triple store for a Lisp application. The server runs in another process and may be located on a separate host located far from the client.
- AllegroGraph Lisp Edition - Standalone. In addition to using Lisp as a client to the AllegroGraph Server, as noted above, you have the full power of a Lisp-REPL Development Environment.
- TopBraid Composer. This is a commercially supported tool for modeling and editing ontologies. You can connect TopBraid composer to AllegroGraph and visually inspect your RDF/OWL data. For details see TopBraid Composer
| Copyright © Franz Inc., All Rights Reserved | Privacy Statement | 
|

|

|

|
|