Introduction
We have a simple natural language interface for querying vector databases, which we illustrate in this document. The interface simply builds SPARQL queries from the user input and displays the results.
We have various examples of vector database. In this document we will repeat (since they appear in other documents as well) the Historical Figures. The Chomsky47 example (described in the LLM Examples document can also be used with this feature.
In the Historical Figures example, we generate a list of historical figures and then try to find connections among them.
To make this document stand alone, we repeat the steps to creating the vector database to be used.
Historical Figures
(This example is repeated in several documents where different uses of of the resulting repos and vector repos are emphasized. The text is identical from here to the note below in every document where it is used.)
For this example, we first create a new repo historicalFigures. Here is the New WebView dialog creating the repo:
Next we have to associate our OpenAI key with the repo. Go to Repository | Repository Control | Query execution options (selecting Manage queries displays that choice as does simply typing "Query" into the search box after Repository control is displayed) and enter the label openaiApiKey and your key as the value, then click SAVE QUERY OPTIONS:

(The key in the picture is not valid.) You can also skip this and use this PREFIX with every query (using your valid key, of course):
PREFIX franzOption_openaiApiKey: <franz:sk-U01ABc2defGHIJKlmnOpQ3RstvVWxyZABcD4eFG5jiJKlmno> Now we create some data in the repo. Go to the Query tab (click Query in the **Repository menu on the left). We run a simple query which uses LLM to add historical figures triples to out repository. Note we define the llm: prefix. (These set-up steps, associating the openaiApiKey with the repo and defining the llm: prefix are taken care of automatically in the llm-playground repos. Here we show what you need to do with a repo you create and name.)
PREFIX llm: <http://franz.com/ns/allegrograph/8.0.0/llm/>
INSERT {
?node rdfs:label ?name.
?node rdf:type <http://franz.com/HistoricalFigure>.
} WHERE {
(?name ?node) llm:response "List 50 Historical Figures".
} Triples are added but the query itself does not list them (so the query shows no results). View the triples to see what figures have been added. We got 96 (you may get a different number; each has a type and label so 48 figures, each using two triples). Here are a bunch:
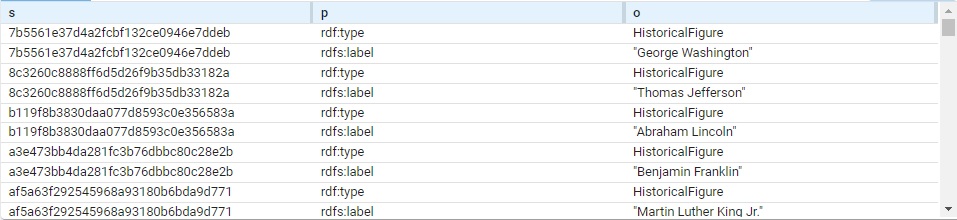
The subject of each triple is a system-created node name. (These are actual values, not blank nodes.) Each is of type HistoricalFigure and each has a label with the actual name.
This query will just list the names (the order is different from above):
# View triples
SELECT ?name WHERE
{ ?node rdf:type <http://franz.com/HistoricalFigure> .
?node rdfs:label ?name . }
name
"Aristotle"
"Plato"
"Socrates"
"Homer"
"Marco Polo"
"Confucius"
"Genghis Khan"
"Cleopatra"
...
(Note: this comes from an chat program external to Franz Inc. The choice and morality of the figures selected are beyond our control.)
Now we are going to use these triples to find associations among them. First we must create a vector database. Create a file historicalFigures.def that looks like this (inserting your aiApi key where indicated):
gpt
embedder openai
if-exists supersede
api-key "sk-U43SYXXXXXXXXXXXXXmxlYbT3BlbkFJjyQVFiP5hAR7jlDLgsvn"
vector-database-name ":10035/historicalFigures-vec"
# The :10035 can be left out as it is the default.
# But you must specify the port number if it is not 10035.
if-exists supersede
limit 1000000
splitter list
include-predicates <http://www.w3.org/2000/01/rdf-schema\#label> Note the # mark in the last line is escaped. The file in Lineparse format so a # is a comment character unless escaped. (We have a couple of comment lines which discuss the default port number.)
Pass this file to the agtool llm index command like this (filling in the username, password, host, and port number):
% agtool llm index --quiet http://USER:PW@HOST:PORT/repositories/historicalFigures historicalFigures.def Without the --quiet option this can produce a lot of output (remove --quiet to see it).
This creates a vector database repository historicalFigures-vec.
(End of example text identical wherever it is used.)
Now we have a vector database historicalFigures-vec make that the current repo in new AGWebView. We need to specify the openaiApiKey in a query option that will be used for all queries in that repo. We did this above for the historicalFigures repo. Here is how to do it for historicalFigures-vec.
When historicalFigures-vec is the current repo, go to Repository | Repository Control | Query execution options (type "Query" into the search box after Repository control is displayed) and enter the label openaiApiKey and your key as the value, then click SAVE QUERY OPTIONS:
Now to ask a natural language query, go to the Query page (click Query in the Repository menu) and select ChatStream - Natural Language from the NEW QUERY menu:
Ask the question Who is connected to cleopatra? and here are the results:
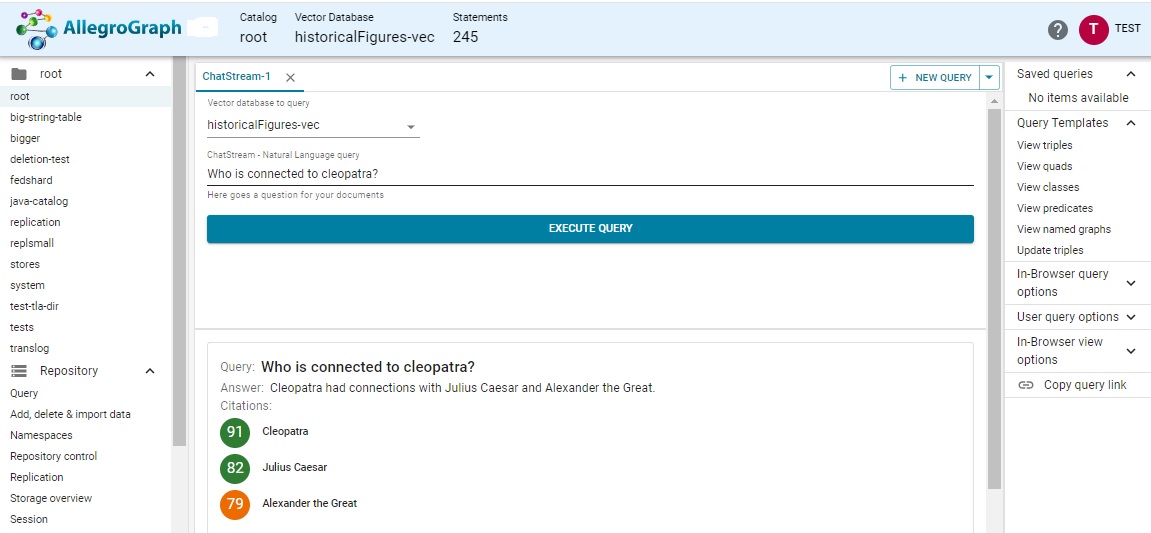
The connections seem right: Cleopatra's sometime boyfriend, and the man whose conquests resulted in the founding of her dynasty.
The natural language processor is just wrapping the query in an appropriate SPARQL query, but this interface is much easier to use.
Try it with other vector databases, such as the Chomsky47-vec created here.