This is the reference guide for AllegroGraph 3.0. The overview tutorial can be found here. An introduction to AllegroGraph covering all of its many features at a high-level is in the AllegroGraph Introduction.
Conceptual Triple-Store Structure
AllegroGraph is a graph database that makes an excellent RDF triple-store. This is a conceptual diagram of the data AllegroGraph manages:
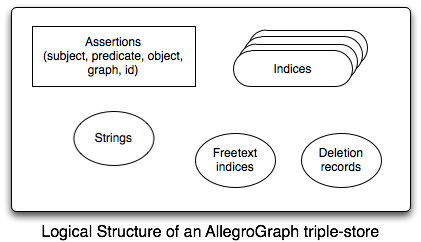
- The bulk of an AllegroGraph triple-store is composed of assertions called triples. For historical reasons, each triple has five fields:
- subject (s)
- predicate (p)
- object (o)
- graph (g)
- triple-id (i)
All of s, p, o, and g are strings of arbitrary size. String data is associated with Unique Part Identifiers (UPIs) and managed by the string dictionary.
To speed queries, AllegroGraph creates indices which contain the assertions plus additional information (see below for more details).
AllegroGraph can also perform freetext searching in the assertions using its freetext indices (see the section on freetext indexing for details).
and Finally, AllegroGraph keeps track of deleted triples
Each assertion can be viewed as an edge p between graph nodes s and o with additional data g or as the statement "subject predicate object (in the context of graph)".
Triple-data generally comes into AllegroGraph as strings either from pure RDF/XML or as the more verbose but simpler N-Triple format. Once the triples are in AllegroGraph, it is possible to manipulate them, perform logical inference, and execute extremely fast queries.
The string dictionary manages efficient storage and fast lookup of the strings in the triple-store. We call the process of hashing a string into its UPI and storing it in the string dictionary interning.
Basic Triple-Store Operations
Adding Triples
Triples stored in files using the N-Triples 1 , RDF/XML 2 , and other formats can be loaded into the triple-store with the following functions.
Add triples from source to the triple store.
source- can be a stream, a pathname to an N-Triples file or a string that can be coerced into a pathname to an N-Triples file. Source can also be a list of any of these things. In this case, each item in the list will be imported in turn. This can be more efficient than iterating over the items yourself since AllegroGraph will only synchronize at the end of the loading.
The following keyword parameters can be used to control the loading process:
:db- specifies the triple-store into which triples will be loaded. This defaults to the value of *db*.:graph- the graph to which the triples fromsourcewill be placed. It defaults tonilwhich is interpreted asdb's default graph. If supplied, it can be:a string representing a URIref, or a UPI or future-part encoding a URIref, which adds the triples in source to a graph named by that URI
the keyword
:source(in which case the source argument will be interned as a URI and the loaded triples added to a graph named by that URI). This has the effect of associating the file or URL of source with the new triples.
:verbose- specifies whether or not progress information is printed as triples are loaded. It defaults to the value of (ag-property:verbose).:always-save-string-literals- determine whether or not to save the strings of a triple's object field when the object can be encoded directly into the triple. If true (the default) then the strings will be saved. If false, then only the encoded values will be preserved (this may prevent exact round-trips if data is coerced during the encoding process).
load-ntriples returns the number of triples added, and the graph used, as multiple values.
Add all of the triples from the string to the triple store.
The following keyword parameters can be used to control the loading process:
:db- specifies the triple-store into which triples will be loaded. This defaults to the value of *db*.:graph- the graph to which the triples fromsourcewill be placed. It defaults tonilwhich is interpreted asdb's default graph. If supplied, it can be:a string representing a URIref, or a UPI or future-part encoding a URIref, which adds the triples in source to a graph named by that URI
the keyword
:source(in which case the source argument will be interned as a URI and the loaded triples added to a graph named by that URI). This has the effect of associating the file or URL of source with the new triples.
:verbose- specifies whether or not progress information is printed as triples are loaded. It defaults to the value of (ag-property:verbose).:always-save-string-literals- determine whether or not to save the strings of a triple's object field when the object can be encoded directly into the triple. If true (the default) then the strings will be saved. If false, then only the encoded values will be preserved (this may prevent exact round-trips if data is coerced during the encoding process).
load-ntriples-from-string returns the number of triples added, and the graph used, as multiple values.
Add triples from the named RDF/XML file to the triple-store. The additional arguments are:
:db- specifies the triple-store into which triples will be loaded; defaults to the value of *db*.:base-uri- this defaults to the name of the file from which the triples are loaded. It is used to resolve relative URI references during parsing. To use no base-uri, use the empty string "".:graph- the graph to which the triples fromsourcewill be placed. It defaults tonilwhich is interpreted asdb's default graph. If supplied, it can be:a string representing a URIref, or a UPI or future-part encoding a URIref, which adds the triples in source to a graph named by that URI
the keyword
:source(in which case the source argument will be interned as a URI and the loaded triples added to a graph named by that URI). This has the effect of associating the file or URL of source with the new triples.
use-rapper-p- Ifuse-rapper-pis true, then the RDF/XML file will be piped through the open source tool rapper using run-shell-command. Obviously, rapper must be both installed and in your path for this to work. If rapper is not in your path, you can supply it explicitly as the value ofuse-rapper-p.
Treat string as an RDF/XML data source and add it to the triple-store. For example:
(load-rdf/xml-from-string
"<?xml version="1.0"?>
<rdf:RDF xmlns:rdf=\"http://www.w3.org/1999/02/22-rdf-syntax-ns#\"
xmlns:ex=\"http://example.org/stuff/1.0/\">
<rdf:Description rdf:about=\"http://example.org/item01\">
<ex:prop rdf:parseType=\"Literal\"
xmlns:a=\"http://example.org/a#\"><a:Box required=\"true\">
<a:widget size=\"10\" />
<a:grommit id=\"23\" /></a:Box>
</ex:prop>
</rdf:Description>
</rdf:RDF>
")
See load-rdf/xml for details on the parser and the other arguments to this function.
RDF in the form of named graphs can also be loaded using load-trix, which understands the TriX format.
Load a TriX document into the triple store named by db.
source- a string or pathname identifying a file, or a stream.:db- specifies the triple-store into which triples will be loaded; defaults to the value of *db*.:verbose- if true, information about the load progress will be printed to*standard-output*.:default-graph- a future-part or UPI that identifies a graph, ornil. If it is non-null, any graphs in the TriX document that are equal to the given URI will be treated as the default graph indb.default-graphcan also be the symbol:source, in which casenamestringis called on the source and treated as a URI.
We have implemented a few extensions to TriX to allow it to represent richer data:
Graphs can be named by
<id>, not just<uri>. (A future revision might also permit literals.)The default graph can be denoted in two ways: by providing
<default/>as the name for the graph; or by providing a graph URI as an argument toload-trix.- In the interest of generality, the predicate position of a triple is not privileged: it can be a literal or blank node (just like the subject and object), not just a URI.
Load a string containing data in TriX format into db
string- a string containing TriX data:db- specifies the triple-store into which triples will be loaded; defaults to the value of *db*.:verbose- if true, information about the load progress will be printed to*standard-output*.:default-graph- a future-part or UPI that identifies a graph, ornil. If it is non-null, any graphs in the TriX document that are equal to the given URI will be treated as the default graph indb.
See load-trix for more details.
If you need to load a format that AllegroGraph does not yet support (for example, Turtle) we suggest you use the excellent free tool rapper from http://librdf.org/raptor/rapper.html to create either an N-Triples or RDF/XML file that AllegroGraph can load.
Note that both load-rdf/xml* and load-ntriples* have been removed from AllegroGraph 3.0 and beyond because their ability to load multiple triples sources simultaneously has been incorporated directly into load-rdf/xml and load-ntriples
Adding Programmatically
You can also add triples to a triple-store programatically with the function add-triple. The three required arguments, representing the subject, predicate, and object of the triple to be added can be expressed either as:
strings in the N-Triples syntax for URI references and literals;
UPIs such as are returned by the functions intern-resource, intern-literal, intern-typed-literal, and new-blank-node;
Encoded-UPIs created with functions like value->upi; or
future-parts created using the !-reader..
Add a new triple to the triple-store with the given subject, predicate and object and graph, specified either as UPIs or strings in N-Triples format. The :db keyword argument specifies the triple store to which the triple will be added and defaults to the value of *db*. Returns the numeric id of the new triple.
Note that duplicate triples can be added to a triple-store but indices will only refer to the same triple once.
Triple Manipulation
Triple parts: Resources, Literals, UPIs and more
Each triple has five parts (!), a subject, a predicate, an object, a graph and a (unique, AllegroGraph assigned) ID. In RDF, the subject must be a "resource", i.e., a URI or a blank node. The predicate must be a URI. The object may be a URI, a blank node or a "literal". Literals are represented as strings with an optional type indicated by URI or with a (human) language tag such as en or jp.
3 ; Blank nodes are anonymous parts whose identity is only meaningful within a given triple-store.
Resources, literals and blank nodes are represented as strings in RDF/XML or N-Triple syntax. AllegroGraph stores these strings in a string dictionary and hashes them to compute a Unique Part Identifier (UPI) for each string. A UPI is a length 12 octet array. One byte of the array is used to identify its type (e.g., is it a resource, a literal, or a blank node). The other 11-bytes are used to either store a hash of the string or to store an encoding of the UPIs contents (see type mapping below for more information about encoded UPIs).
From Strings to Parts
Resources and literals can be denoted with plain Lisp strings in the syntax used in N-Triples files. However this isn't entirely convenient since the N-Triples syntax for literals requires quotation marks which then need to be escaped when writing a Lisp string. For instance the literal whose value is "foo" must be written in N-Triples syntax as "\"foo\"". Similarly -- though not quite as irksome -- URIs must be written enclosed in angle brackets. The string "http://www.franz.com/simple#lastName", passed as an argument to add-triple will be interpreted as a literal, not as the resource indicated by the URI. To refer to the resource in N-Triples syntax you must write "<http://www.franz.com/simple#lastName> ". Literals with datatypes or language codes are even more cumbersome to write as strings, requiring both escaped quotation marks and other syntax.
To make it easier to produce correctly formatted N-Triple strings we provide two functions resource and literal. (The ! reader macro, discussed below, can also be used to produce future-parts and UPIs suitable to use as arguments for most of AllegroGraph's API.):
Create a new future-part with the provided values.
:language- If provided,languageshould be a valid RDF language tag.:datatype- If provided, thedatatypemust be a resource. I.e., it can be a string representation of a URI (e.g., "http://foo.com/") or a future-part specifying a resource (e.g., !<http://foo.com>). If it does not specify a resource, a condition of type invalid-datatype-for-literal-error is signaled. An overview of RDF datatypes can be found in the W3C's RDF concepts guide.
Only one of datatype and language can be used at any one time. If both are supplied, a condition of type datatype-and-language-specified-error will be signaled.
Return the provided string as a future-part naming a resource. If namespace is provided, then string will be treated as a fragment and the future-part returned will be the URIref whose prefix is the string to which namespace maps and whose fragment is string. I.e., if the namespace prefix rdf maps to <http://www.w3.org/1999/02/22-rdf-syntax-ns#>, then the parts created by
(resource "Car" "rdf")
and
(resource "http://www.w3.org/1999/02/22-rdf-syntax-ns#Car")
will be the same.
Some examples (we will describe and explain the ! notation below):
> (resource "http://www.franz.com/")
!<http://www.franz.com/>
> (literal "Peter")
!"Peter"
> (literal "10" :datatype
"http://www.example.com/datatypes#Integer")
!"10"^^<http://www.example.com/datatypes#Integer>
> (literal "Lisp" :language "EN")
!"Lisp"@en
Another issue with using Lisp strings to denote literals and resources is that the strings must, at some point, be translated to the UPIs used internally by the triple-store. This means that if you are going to add a large number of triples containing the same resource or literal and you pass the resource or literal value as a string, add-triple will have to repeatedly convert the string into its UPI.
To prevent this repeated computation, you can use functions like intern-resource, intern-literal, or intern-typed-literal to compute the UPI of a string outside of the add-triple loop. The function new-blank-node (or the macro with-blank-nodes) can be used to produce the UPI of a new anonymous node for use as the subject or object of a triple.
Returns true if upi is a blank node and nil otherwise. For example:
> (blank-node-p (new-blank-node))
t
> (blank-node-p (literal "hello"))
nil
Compute the UPI of the string URI, make sure that it is stored in the string dictionary, and return the UPI.
:db- specifies the triple-store into which theuriwill be interned. This defaults to the value of *db*.:upi- if supplied, then thisupiwill be used to store theuri's UPI; otherwise, a new UPI will be created using make-upi.
Compute the UPI of value treating it as an untyped literal, possibly with a language tag. Ensure that the literal is in the store's string dictionary and return the UPI.
:language- if supplied, then this language will be associated with the literalvalue. See rfc-3066 for details on language tags.:db- specifies the triple-store into which theuriwill be interned. This defaults to the value of *db*.:upi- if supplied, then thisupiwill be used to store theuri's UPI; otherwise, a new UPI will be created using make-upi.
Compute the UPI of value treating it as an typed literal with datatype datatype. Ensure that the literal is in the store's string dictionary and return the UPI.
value- must be a stringdatatype- a URI, a future-part specifying a URI or a UPI specifying a URI.:db- specifies the triple-store into which theuriwill be interned. This defaults to the value of *db*.:upi- if supplied, then thisupiwill be used to store theuri's UPI; otherwise, a new UPI will be created using make-upi.
db and return the UPI. If a upi is not passed in with the :upi parameter, then a new UPI structure will be created.
This convenience macro binds one or more variables to new blank nodes within the body of the form. For example:
(with-blank-nodes (b1 b2)
(add-triple b1 !rdf:type !ex:Person)
(add-triple b1 !ex:firstName "Gary")
(add-triple b2 !rdf:type !ex:Dog)
(add-triple b2 !ex:firstName "Abbey")
(add-triple b2 !ex:petOf b1))
The following example demonstrates the use of these functions. We use intern-resource to avoid repeatedly translating the URIs used as predicates into UPIs and then use new-blank-node to create a blank node representing each employee and intern-literal and intern-typed-literal to translate the strings in the list employee-data into UPIs. (We could also use literal to convert the strings but using intern-literal is more efficient.)
(defun add-employees (company employee-data)
(let ((first-name (intern-resource "http://www.franz.com/simple#firstName"))
(last-name (intern-resource "http://www.franz.com/simple#lastName"))
(salary (intern-resource "http://www.franz.com/simple#salary"))
(employs (intern-resource "http://www.franz.com/simple#employs"))
(employed-by (intern-resource "http://www.franz.com/simple#employed-by")))
(loop for (first last sal) in employee-data do
(let ((employee (new-blank-node)))
(add-triple company employs employee)
(add-triple employee employed-by company)
(add-triple employee first-name (intern-literal first))
(add-triple employee last-name (intern-literal last))
(add-triple
employee salary
(intern-typed-literal sal "http://www.franz.com/types#dollars"))))))
Note that the only difference between resource and intern-resource is that the former only computes the UPI of a string whereas the latter both does this computation and ensures that the string (and its UPI) are present in the triple-store's string dictionary.
Working with Triples
The functions subject, predicate, object, graph, and triple-id provide access to the part UPIs of triples returned by the cursor functions cursor-row and cursor-next-row or collected by get-triples-list.
Sets and gets the graph UPI of a triple.
In addition to being returned, the optional upi argument will be filled in with the graph's UPI. If not passed in, a new UPI will be created.
Sets and gets the object UPI of a triple.
In addition to being returned, the optional upi argument will be filled in with the object's UPI. If not passed in, a new UPI will be created.
Sets and gets the predicate UPI of a triple.
In addition to being returned, the optional upi argument will be filled in with the predicate's UPI. If not passed in, a new UPI will be created.
Sets and gets the subject UPI of a triple.
In addition to being returned, the optional upi argument will be filled in with the subject's UPI. If not passed in, a new UPI will be created.
triple.
Working with UPIs
You can also create UPIs and triples programmatically; determine the type-code of a UPI, and compare them. You may want to make your own copy of a triple or UPI when using a cursor since AllegroGraph does not save triples automatically (see, e.g., iterate-cursor for more details).
If using encoded-triples or UPIs, then the functions upi->value and value->upi will be essential. You can also check the type of a UPI with either upi-type-code or upi-typep (see type-code->type-name and its inverse type-name->type-code for additional information.)
Copy a triple.
triple- the triple to copynew- (optional) If supplied, then this must be a triple and the copy oftriplewill be placed into it. Otherwise, a new triple will be created.
This function is useful if you want to keep a reference to a triple obtained from a cursor returned by query functions such as get-triples since the cursor reuses the triple data structure for efficiency reasons.
Create a copy of a UPI.
upi- the UPI to copy.
triple1 and triple2 and returns true if they have the same contents and triple-id and false otherwise. See triple-contents= if you need to compare triples regardless of their IDs.
Decodes UPI and returns the value, the type-code and any extra information as multiple values.
upi- the UPI to decode:db- specifies the triple-store from which the UPI originates.
The value, type-code, and extra information are interpreted as follows:
- value - a string representing the contents of the UPI
- type-code - an integer corresponding to one of the defined UPI types (see supported-types for more information). You can use type-code->type-name to see the English name of the type.
- extra - Some encoded UPIs contain additional information which will be placed in
extraif it is there. Examples include the language code or datatype of a literal. If no extra information is present, thennilwill be returned as the extra information.
Examples:
> (upi->value (value->upi 22 :byte))
22
18
nil
> (upi->value (upi (literal "hello" :language "en")))
"hello"
3
"en"
See value->upi for additional information.
type-code of a UPI. This is a one-byte tag that describes how the rest of the bytes in the UPI should be interpreted. Some UPIs are hashed and their representation is stored in a string-table. Other UPIs encode their representation directly (see upi->value and value->upi for additional details).
Returns true if upi has type-code type-code.
upi- a UPItype-code- either a numeric UPI type-code or a keyword representing a type-code. See type-code->type-name and type-name->type-code for more information on type-codes and their translations.
upi-1 and upi-2 bytewise and return true if upi-1 is less than upi-2.
thing appears to be a UPI. Recall that every UPI is a octet array 12 bytes in length but not every length 12 octet array is a UPI. It is possible, therefore, that upip will return true even if thing is not a UPI.
value into UPI as type of encode-as. The encode-as argument can be a type code or a type name (see supported-types and type-name->type-code for details. If a upi keyword argument is not supplied, then a new UPI will be created. See upi->value for information on retrieving the original value back from an encoded UPI.
Comparing parts of triples
triple is the same as part using part= for comparison. The part may be a UPI, a string (in N-Triples syntax) that can be converted to a UPI, or a future-part. See graph-upi= if you know that you will be comparing UPIs.
triple is the same as part using part= for comparison. The part may be a UPI, a string (in N-Triples syntax) that can be converted to a UPI, or a future-part. See object-upi= if you know that you will be comparing UPIs.
triple is the same as part using part= for comparison. The part may be a UPI, a string (in N-Triples syntax) that can be converted to a UPI, or a future-part. See predicate-upi= if you know that you will be comparing UPIs.
triple is the same as part using part= for comparison. The part may be a UPI, a string (in N-Triples syntax) that can be converted to a UPI, or a future-part. See subject-upi= if you know that you will be comparing UPIs.
triple is the same as upi using upi= for comparison. The upi must be a UPI. See graph-part= if you need to compare future-parts or convert strings into UPIs.
triple is the same as upi using upi= for comparison. The upi must be a UPI. See object-part= if you need to compare future-parts or convert strings into UPIs.
triple is the same as upi using upi= for comparison. The upi must be a UPI. See predicate-part= if you need to compare future-parts or convert strings into UPIs.
triple is the same as upi using upi= for comparison. The upi must be a UPI. See subject-part= if you need to compare future-parts or convert strings into UPIs.
Future-Parts and UPIs
Future-parts (which are discussed in detail in their own section) can take the place of UPIs in many of the functions above. For efficiencies sake, functions like upi= assume that they are called with actual UPIs. AllegroGraph provides more general functions for the UPI only variants when it makes sense to do so. For example, future-part= works only with future-parts whereas part= works equally well with any combination of UPIs, future-parts or even strings.
Return whatever is extra in the string of the future-part. The meaning of extra depends on the type of the part:
- resource - the prefix (if applicable)
- typed-literal - the datatype
- language-literal - the language
- other - the value will always be
nil
See future-part-type and future-part-value if you need to access the part's other parts.
Return the value of the future-part. The meaning of value depends on the type of the part:
- resource - the namespace (if any)
- typed-literal - the literal without the datatype
- language-literal - the literal without the language
- other - the value will always be
nil
See future-part-type and future-part-extra if you need to access the others parts (no pun intended) of the part.
Returns the UPI associated with the future-part future-part.
If the future-part uses namespaces, then calling upi will resolve the namespace mapping. An error will be signaled if upi is called and there is no namespace mapping defined. You can use the errorp keyword parameter to disable the error and return nil instead.
Querying Triples
You can get triples out of a triple-store as a list or a cursor. The list structure is convenient but unwieldy if your query returns millions of triples (since every triple must be returned before you will see any of them). A cursor is like a database cursor from the RDBMS-world. It lets you traverse through the results of your query one step at a time.
Cursors
Cursors supply the functions cursor-next, cursor-row, and cursor-next-p for basic forward iteration. For convenience we include cursor-next-row which advances the cursor and returns the next row immediately. Cursors reuse the triple data-structure as they move through the result set so if you want to accumulate triples, make sure to use the copy-triple function.
cursor has at least one more triple in it. Note that cursor-row, cursor-next and cursor-next-p are lower-level cursor manipulation routines. You may be better served by using collect-cursor, count-cursor, map-cursor and iterate-cursor.
Moves cursor forward to the next triple in the collection.
Returns t if there was another row on which to move and nil if the cursor is exhausted. I.e., if cursor-next returns t, then cursor-row will return a triple.
Note that cursor-row, cursor-next and cursor-next-p are lower-level cursor manipulation routines. You may be better served by using collect-cursor, count-cursor, map-cursor and iterate-cursor.
Returns the next triple from the cursor. The actual triple object returned is always the the same (eql) object. If you want to hold onto a triple for use after you advance the cursor, use the function copy-triple to make a copy of the value returned by cursor-next-row
Note that cursor-row, cursor-next, cursor-next-row and cursor-next-p are lower-level cursor manipulation routines. You may be better served by using collect-cursor, count-cursor, iterate-cursor and map-cursor.
Returns the triple that cursor is currently pointing at.
If the cursor is exhausted, then cursor-row returns nil.
Note that cursor-row, cursor-next and cursor-next-p are lower-level cursor manipulation routines. You may be better served by using collect-cursor, count-cursor, map-cursor and iterate-cursor.
There are several natural cursor idioms, the following functions handle many of them. We suggest building your own functions using these as building blocks since there may be internal optimizations made possible only through these. 4
cursor and collect a list of its triples. The :transform keyword can be used to modify the triples as they are collected. It defaults to the copy-triple function but you can use any function that takes one triple as an argument. (collect-cursor reuses the row argument so make sure that you use copy-triple in your own code if necessary).
Iterate over the triples in cursor binding var to each triple. Use the :count keyword with a fixnum value to limit the maximum number of triples that iterate-cursor visits. The binding to var is the same EQ triple in each iteration. Make sure to use copy-triple if you are retaining any of the triples that you visit.
The macro creates a block nil around its expansion. If iteration finishes normally by satisfying the count or by exhausting the cursor, iterate-cursor returns the number of triples visited.
Iterate over the triples in cursor while applying the function fn to each one. Use the count keyword to limit the maximum number of triples that map-cursor visits. In each iteration fn is applied to the current triple and to the list of arguments in args. map-cursor reuses a single triple as it iterates so make sure to use copy-triple if you retain any of the triples you visit.
The function returns the number of triples visited.
There are many other functions that either query a triple-store directly or return information about a triple-store. For example, count-query determines the number of matches to a query very quickly (because it doesn't bother to iterate over them) and pprint-subject lets you easily explore more about particular resources.
db using only the information stored in the indices. Unindexed triples will not be included. An error will be signaled if the triple-store is missing the required index for the query.
db using only the information stored in the indices. Unindexed triples will not be included. The estimate can be off by as much as twice the triple store's metaindex-skip-size for each index chunk involved.
s, p, o and g. You may also specify that only encoded or unencoded triples by searched; whether or not to search deleted triples; and whether or not a filter should be used.. A new triple will be created unless you pass in one to use using the triple keyword parameter. nil is returned if no triples match.
triple-id is id and return it. The keyword argument db can be used to specify the triple-store in which to search. It defaults to the current triple-store, *db*. Get-triple-by-id allocates a new triple (using make-triple. You can prevent this by passing in your own triple using the keyword argument :triple. The data in the triple you pass in will by overwritten.
Query a triple store for triples matching the given subject, predicate, object, and graph. These can be specified either as UPIs, future-parts, strings in N-Triple format, or the wildcard nil. Returns a cursor object that can be used with cursor-next-p and cursor-next-row.
The following example finds every triple that starts with !ub:Kevin.
> (add-triple !ub:Kevin !ub:isa !"programmer")
8523645
> !ub:Kevin
!<http://www.w3.org/1999/02/22-rdf-syntax-ns#Kevin>
> (get-triples :s !ub:Kevin)
#<row-cursor #<triple-record-file @ #x13c1a87a> 2019 [1 - 2018] @
#x14942bba>
> (print-triples *)
<http://www.w3.org/1999/02/22-rdf-syntax-ns#Kevin>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#isa>
"programmer" .
The function get-triples takes the following arguments:
s,p,o,g- specify the query pattern. Usenilas a wildcard. Each of these can be a UPI, a future-part, or a string that can be converted into a part. These can also take on the value :minimum if a corresponding?-endparameter is specified. If :minimum is used, then the range query will run from the smallest value up to the ending value.s-end,p-end,o-end,g-end- Allows for range queries over encoded triples (triples whose parts are encoded UPIs). Each?-endparameter may only be used in conjunction with its corresponding starting value parameter. Each of these can be a UPI, a future-part, or a string that can be converted into a part. These can also take on the value :maximum if a corresponding starting parameter is specified. If :maximum is used, then the range query will run from the starting value up to the maximum value in the triple-store.The
:dbkeyword argument specifies the triple store to query, defaulting to the value of *db*.filter - if supplied, the
filtershould be a predicate of one parameter, a triple. If the filter function returnsnil, then the triple will not be included in the result set.include-deleted - if set to true, then triples that are flagged as deleted will not be filtered out by the cursor.
return-encoded-triples - If true, then get-triples returns triples with encoded parts; i.e., triples that use directly encoded UPIs rather than strings stored in the dictionary. The default value is true.
return-non-encoded-triples - if true, then
get-tripleswill return triples all of whose UPIs are stored as strings. This is set to true unless overridden.
The return value is a cursor object. The functions cursor-next-row and cursor-next-p can be used to step through the cursor.
If it can be determined that one of the search parameters is not interned in the triple-store, then get-triples will return a null-cursor (i.e., a cursor that has no rows) and a second value of :part-not-found.
Query a triple store for triples matching the given subject, predicate, object, and graph, specified either as part IDs (UPIs), future-parts, strings in N-Triples format, or the wildcard nil. Returns a list of matching triples. The get-triples-list function supports a multitude of options:
db- This keyword argument specifies the triple store to query, defaulting to the value of *db*.s,p,o,g- controls the actual query pattern. Usenilas a wildcard.s-end,p-end,o-end,g-end- Allows for range queries over encoded triples (triples whose parts are encoded UPIs). Each?-endparameter may only be used in conjunction with its corresponding starting value parameter.cursor- if cursor is supplied then AllegroGraph will use it to return more triples rather than building a new cursor.if-fewer- controls the behavior ofget-triples-listwhen fewer thanlimittriples match the query. Possible values are (defaults tonil):nil- return list of actual results:error- signal error if fewer results than limitother -- return other instead of short list
if-more- controls what happens when more results thanlimitare available. Possible values are (defaults to:cursor):nil- return list of limit results:error- signal error if more results than limit:cursor- return the list of limit results and a second value of a cursor that will yield the remaining resultsother - return other instead of truncated list
limit- This keyword argument can be used to place a cap on the maximum number of triples returned. It defaults to the value of the special variable get-triples-list-limit. If set, then get-triples-list will return no more than:limittriples. If it is nil, then get-triples-list will return all of the triples found by the query. Warning: settinglimitto nil can causeget-triples-listto return every triple in the triple-store; this can be a very bad thing over a serial connection.return-encoded-triples- If true, then get-triples-list returns triples with encoded parts; i.e., triples that use directly encoded UPIs rather than strings stored in the dictionary. The is set to true unless overridden.return-non-encoded-triples- if true, thenget-triples-listwill return triples all of whose UPIs are stored as strings. This is set to true unless overridden.use-reasoner- Deprecated. If true, then the RDFS++ reasoner will be used to return inferred triples. If left unspecified, this will be true if thedbis a reasoning-triple-store andnilotherwise.Note that most of the arguments to
get-triples-listdo not make sense when reasoning is turned on. AllegroGraph will signal an error if you try to combine reasoning with other parameters that it cannot use.
If it can be determined that one of the search parameters is not interned in the triple-store, then get-triples-list will return immediately return nil.
part down to a maximum depth of maximum-depth using the format format. Triples for which part is an object and their children will be printed. See part->string and (ag-property :default-print-triple-format) for information about part printing. See pprint-subject to display information based on objects rather than subjects.
part down to a maximum depth of maximum-depth using the format format. Triples for which part is a subject and their children will be printed. See part->string and (ag-property :default-print-triple-format) for information about part printing. See pprint-object to display information based on subjects rather than objects.
s, p and o (and optionally g) can be found in the designated triple-store. If left unspecified, the triple-store designated by *db* will be searched. This is handy when you care only about the presence of a triple and not its contents. If you want to use the triple, then use get-triple instead.
Range Queries
Both get-triples and get-triples-list support fast range queries using AllegroGraph's encoded data types. Though RDF requires that subjects be resources or blank nodes and predicates by resources, AllegroGraph allows you to store and query for encoded data types in any of a triple's fields. 5 In each case, to execute a range query, you must supply a starting and ending encoded UPI. You can only make a range query on a single field in each query but you can include other fields which act as additional filters. For example:
> (get-triples :o (value->upi "12:01" :time))
:o-end (value->upi "12:59" :time)
:p !ex:startTime)
will return a cursor that iterates only all of the triples whose predicate is !ex:startTime and whose object falls between 12:01 and 12:59.
6
SPARQL Overview
AllegroGraph includes twinql, an implementation of the powerful SPARQL query language. SPARQL is covered both in this reference guide and in the twinql reference and tutorial. AllegroGraph also includes a SPARQL client and Server.
Prolog Select Overview
With pure Lisp as the retrieval language, you use a combination of functional and procedural approaches to query the database. With Prolog, you can specify queries in a much more declarative manner. Allegro CL Prolog and AllegroGraph work very well together. The reference guide includes more details and the tutorial provides an introduction to using Prolog and AllegroGraph with many complete examples.
RDFS++ Reasoning Overview
See the Reasoner tutorial for more details on using AllegroGraph's RDFS++ reasoner. It works with get-triples, get-triples-list, SPARQL and the Prolog q functor.
Deleting and Undeleting triples
AllegroGraph lets us delete and undelete triples. The function delete-triples deletes triples from the triple store, using the same query syntax as get-triples.
Marks the triple whose id is id as deleted.
See also undelete-triple and undeleted-triple-p.
The :db keyword argument specifies the triple store in which the triple should be marked as deleted.
Delete triples matching the given subject, predicate, object, and graph, specified either as part IDs, strings in N-Triples format, or the wildcard nil. Returns the number of triples deleted.
The :db keyword argument specifies the triple store to query, defaulting to the value of *db*.
Returns a boolean indicated whether the triple whose ID is id is deleted.
The :db keyword argument specifies the triple store in which to check.
Unsets the deleted flag from the triple whose id is id.
The :db keyword argument specifies the triple store in which the triple should be marked as undeleted.
Undelete triples matching the given subject, predicate, object, and graph, specified either as part IDs, strings in N-Triples format, or the wildcard nil. Returns the number of triples undeleted.
The :db keyword argument specifies the triple store to query, defaulting to the value of *db*.
Serializing Triples
There are several methods by which you can create a textual representation of your triple-store:
- using print-triples,
- using one of the serialization functions like serialize-rdf/xml or serialize-rdf-n3
- using the serialization methods in twinql (AllegroGraph's SPARQL sub-system).
The print-triples function provides a simple mechanism to output triples to *standard-output* or a stream. It's easy to build an export function on top of it:
(defun export-triples (triples file)
(with-open-file (output file
:direction :output
:if-does-not-exist :create
:if-exists :error)
(print-triples triples
:limit nil :stream output :format :ntriple)))
The other techniques provide more control over the output format.
:format, which defaults to the value of (ag-property :default-print-triple-format), specifies how the triple should be printed. The value :ntriples specifies that it should be printed in N-Triples syntax. The value :long indicates that the string value of the part should be used. And the value :concise causes it to use a more concise, but possibly ambiguous, human-readable format.
triple-container which can be either a triple store object, a list of triples such as is returned by get-triples-list, or a cursor such as is returned by get-triples. If the keyword argument :limit is supplied, then at most that many triples will be displayed. The :format keyword argument controls how the triples will be displayed, in either :ntriples, :long, or :concise format. It defaults to (ag-property :default-print-triple-format). The stream argument can be used to send output to the stream of your choice. If left unspecified, then output will go to standard-output.
Write from, which should be a triple store, a list, or a cursor, to to, which should be a stream, file path, t (print to *standard-output*), or nil (return a string).
If from is a triple-store or a list of triples, and prepare-namespaces-p is t, it is first traversed to build a hash of namespaces to prefixes for all properties in the store. The value of db.agraph::*namespaces* is used as a seed.
If you can ensure that every property used in the triple-store has a defined prefix, you can pass nil for prepare-namespaces-p to gain a speed improvement from omitting this phase.
If error-on-invalid-p is t, the serializer will throw an error if it encounters a type or predicate that it cannot abbreviate for RDF/XML.
If a namespace prefix table is built, it will be returned as the second value.
If from is a cursor, it cannot be traversed multiple times, so prepare-namespaces-p is ignored. If a property is encountered that cannot be abbreviated with the current available prefixes, an error will be signaled, unless error-on-invalid-p is nil. You should be aware of this before using this serializer: serializing the output of a cursor can fail if you do not first prepare namespace mappings, or specify that invalid output is acceptable.
if-exists and if-does-not-exist are arguments to the Common Lisp open function which apply when to is a filename.
If memoize-abbrev-lookups-p is t, a upi-hash-table is built to store the mappings between resources in the store and string abbreviations. This hash-table will contain as many entries as there are types and properties in the data to be serialized. For some datasets disabling this caching will yield a significant reduction in space usage in exchange for a possible loss of speed.
If indent is non-nil, then it specifies the initial indentation of elements.
If nestp is t, then (subject to the order of triples in the triple store) some nesting of RDF/XML elements will be applied. nestp of nil will cause a flat tree to be produced, where each resource is its own top-level element.
If output-types-p is t, then additional queries will be performed for each resource to decorate the RDF/XML with types. If nil, then rdf:type elements alone will be used.
Please note that the RDF/XML serializer is not guaranteed to work correctly with value-encoded literals.
Serialize source according to exchange-of-named-rdf-graphs. Serialization will probably open at least as many files as there are graphs in the source.
Returns the manifest path and the number of graphs saved.
If single-stream-p only a single file is open at any one time. This is slower, but guaranteed not to fail with large numbers of graphs.
Write source, which should be a triple store, cursor, or list of triples, to output. output must be t (equivalent to *standard-output*), nil (which returns the serialization as a string), a string or pathname, which will be opened for output respecting the if-exists and if-does-not-exist arguments, or a stream.
The resulting output is produced according to the value of constraints. This must be one of the following symbols:
:canonical: each graph appears once in the output. All graphs and triples are sorted lexicographically. All graphs are named, even when a name must be generated.:collated: each graph appears once in the output.:lenient(ornil, the default): graphs can appear multiple times in the output. No sorting occurs. load-trix can consume this, but not all other TriX parsers necessarily can.
The value of the default-graph argument applies when the default graph has to be serialized. If it is nil, the default, the AllegroGraph-specific <default/> element is used. If it is non-null, it should be a URI string or a valid part that will be substituted into the output.
Managing a triple-store
These functions are used to create, delete, and examine a triple-store. All of a triple-store's data is kept in a single directory whose name it shares. For convenience, many operations act by default on the current triple-store which is kept in a special variable named *db*. The with-triple-store macro makes it easy to call other code with a particular store marked current. There are also several reports that describe the triple-store in detail.
Each triple-store has two parameters that help you to manage its indices automatically: unindexed-triple-count-threshold and unmerged-chunk-count-threshold. The first controls the maximum number of unindexed triples in the store; the second controls the maximum number of index chunks or fragments. When it ships, each triple-store has both of these parameters set to zero (0) which means that no automatic indexing and merging will take place -- everything is left to your control. Here are some of the things that you will want to consider when setting these values.
- Ideally, you would like to have all of your triples indexed into a single index-fragment.
- The lower you set unindexed-triple-count-threshold, the fewer unindexed triples you will have but you will also have more index chunks.
- Each query must examine each index chunk so having too many will slow down query times.
We suggest that you experiment with variations on the parameters. Franz is very open to hearing your feedback on how you would like to manage your triple-store.
One final point is that the automatic indexing and merging is subject to checks by the AllegroGraph manager process (see manager-period elsewhere in this documentation).
db keyword argument default to the value of this variable.
While completely unrelated to AllegroGraph, there is another symbol with the same name exported from the dbi.oracle package. If you try to have a package use both the dbi.oracle and the db.agraph packages, these two symbols will signal a package conflict error. Assuming you want to have the db.agraph symbol to be available without a package qualifier, you should define your package something like this
(defpackage :my-package
(:use :cl :dbi.oracle :triple-store ...)
(:shadowing-import-from :triple-store :*db*)
...)
or else execute this form
(shadowing-import 'db.agraph:*db*)
before using either package.
:wait keyword parameter is passed along to close-triple-store. It defaults to nil
Close the triple store, after saving all persistent data to disk as if by sync-triple-store. Close-triple-store has the following keyword arguments:
:db- defaults to the value of *db* and specifies which triple-store to close. *db* is set tonilafter the triple store is closed. A triple-store only needs to be closed once regardless of how many times open-triple-store has been called on it.:if-closed- controls the behavior when thedbis either not open or nil. Ifif-closedis:errorthen an error will be signaled in this situation. If it is:ignore, thenclose-triple-storewill just return without signaling an error. The argument defaults to:ignore.:verboseis true, then a message will be printed to*debug-io*before the triple store is closed.:waitis true thenclose-triple-storewill not return until all of its concurrent activity is complete. This includes synchronizing its data, building indices and running queries. The value of:waitwill be true unless overridden. If it is false, thenclose-triple-storewill return immediately but the triple-store will no longer be available to use. Its actual in-memory structures will not be available to the garbage-collector until all of its background activity is complete and it is finally closed.
Create a new triple store with the given name. This is both the name of the triple-store and its location on disk. It can be the full path to a directory or just a directory name. If it is a simple name, then the directory argument is used to convert it to a complete path.
For example, to create a triple-store named 'animals' in the directory 'c:/datafiles/biology', you could use either
(create-triple-store
"c:/datafiles/biology/animals")
or
(create-triple-store "animals"
:directory "c:/datafiles/biology/")
The directory defaults to the directory component of *default-pathname-defaults*. You cannot use a name containing a directory path and the directory argument simultaneously.
Create-triple-store takes numerous keyword arguments:
:if-exists- controls what to do if the data directory already exists. The default value,:supersede, will cause create-triple-store to delete the old triple store and create a new one;:errorcauses create-triple-store to signal an error.:expected-unique-resources- sets the initial size of the triple-store. It determines the number of unique names (e.g., resources and literals) that the triple store is expected to hold and defaults to the value of default-expected-unique-resources. The triple-store will grow if this number is exceeded but setting the value initially will provide better performance because no resizing will be required.:with-indices- adds indices to the newly created triple-store. It is equivalent to calling add-index once for each index in the list of indices. It defaults to the value of the AllegroGraph propertystandard-indices.:include-standard-parts- if true, then AllegroGraph will add the following strings to the triple-store at creation time: rdf:type, owl:sameAs, owl:inverseOf, rdfs:subPropertyOf, rdfs:subClassOf, rdfs:range, rdfs:domain, owl:transitiveProperty. The value defaults to the ag-property(:include-standard-parts).
Create-triple-store returns a triple-store object and sets the value of the variable *db* to that object.
:directory parameter to create-triple-store or by using a full pathname as the name argument to create-triple-store.
name parameter used in the call to create-triple-store.
db. This is the graph that will be assigned to any triples added to db unless a different graph is specified.
Delete an existing triple store. Returns t if the deletion was successful and nil if it was not. The :db keyword argument can be either a triple store instance or the name of a triple store. If it is an instance, then the triple store associated with the instance will be deleted. If it is a name, then the triple store of that name in the directory designated by the :directory keyword argument will be deleted. The directory parameter defaults to the directory component of *default-pathname-defaults*.
The :if-does-not-exist keyword argument specifies what to do if the data directory does not exist. The default value, :error, causes delete-triple-store to signal an error. The value :ignore will cause delete-triple-store to do nothing and return nil.
The :if-open keyword argument specifies the behavior if the designated triple store is currently open. The default value, :error, causes delete-triple-store to signal an error. The value :close causes delete-triple-store to close the triple store, as if by close-triple-store and then delete it. If AllegroGraph is unable to close the triple store, an error may still be signaled.
Close any current triple-store and create a new empty one in a temporary directory. Make-tutorial-store takes two keyword parameters:
:temporary-directory- the directory where the store will be created. If it is not supplied, then it will get its value from (ag-propertytemporary-directory).:use-reasoner- If true (the default), then the new triple-store will use RDFS++ reasoning. If nil, then the triple-store will have no reasoning.
The new triple-store will be bound to *db* and is also returned by make-tutorial-store.
Open an existing triple store (previously created using create-triple-store) with the given name. Name is both the name of the triple-store and its location on disk. It can be the full path to a directory or just a directory name. If it is a simple name, then the directory argument is used to convert it to a complete path.
For example, to open a triple-store named 'animals' in the directory 'c:/datafiles/biology', you could use either
(open-triple-store
"c:/datafiles/biology/animals")
or
(open-triple-store "animals"
:directory "c:/datafiles/biology/")
The directory defaults to the directory component of *default-pathname-defaults*. You cannot use a name containing a directory path and the directory argument simultaneously.
The :if-does-not-exist keyword argument specifies what to do if the data directory does not exist. The default value, :error, causes open-triple-store to signal an error. The value :create will cause open-triple-store to create the triple store as if by a call to create-triple-store.
You can use the :with-indices parameter to add additional indices to the triple-store. (Adding an index multiple times has no effect). This will not remove any indices that already exist (see drop-index and drop-indices if you need to do that).
Returns a triple store object and sets the value of the variable *db* to that object. If the named triple store is already open, open-triple-store returns the same object.
WARNING Multiple calls to open-triple-store with the same arguments will each return the same (eq) triple-store. This means that closing a store in one thread will also close the store for all other threads that have opened it. Please contact Franz support staff ([email protected]) for multi-threaded programming strategies
This function has to be called before any inferences are made. It creates internal hash-tables to speed up the reasoner. In normal operation, AllegroGraph will call prepare-reasoning as necessary. You can see diagnostic messages by using the parameter verbose which defaults to the value of (ag-property :verbose-prepare-reasoning). You can also force the hash-tables to be regenerated using the force parameter. Finally, the show-progress keyword argument can be used to cause prepare-reasoning to print a message for each of the hash-tables it builds.
The function prepare-reasoning returns no value.
Ensure that all persistent data needed by the triple store is saved to disk.
Called automatically by close-triple-store and the bulk loading operations like load-ntriples. The :db keyword argument defaults to *db*. Returns t.
:db keyword argument specifies the triple store to use, either by name or a triple store object. It defaults to the value of *db*.
Returns true if the triple-store with the given name exists. Name can be the full path to a directory or just a directory name. If it is a simple name, then the directory argument is used to convert it to a complete path.
For example, to verify the existence of a triple-store named 'animals' in the directory 'c:/datafiles/biology', you could use either
(triple-store-exists-p
"c:/datafiles/biology/animals")
or
(triple-store-exists-p "animals"
:directory "c:/datafiles/biology/")
The directory defaults to the directory component of *default-pathname-defaults*. You cannot use a name containing a directory path and the directory argument simultaneously.
unindexed-triple-count-threshold unindexed triples, an indexing task will be started to index them. If a indexing-host has been added then the task will run on it (see add-indexing-host for details). Otherwise, indexing will run as a background task of the main AllegroGraph process.
Binds both var and db to the triple-store designated by store. The following keyword arguments can also be used:
errorp - controls whether or not
with-triple-storesignals an error if the specified store cannot be found.read-only-p - if specified then with-triple-store will signal an error if the specified triple-store is writable and read-only-p is nil or if the store is read-only and read-only-p is t.
- state - can be :open, :closed or nil. If :open or :closed, an error will be signaled unless the triple-store is in the same state.
This variable controls when changes to the triple store are written to disk. If t, then changes will be written after every call to add-triple. If nil (which is the default), then changes will be written only when the triple store is closed, indexed, or synchronized. A setting of nil is more efficient but can lead to surprises: for example, the results of queries may not contain recently added triples.
Note that functions such as load-ntriples and load-rdf/xml dynamically bind *synchronize-automatically* to nil in their inner loops for efficiency's sake. You may want to use a similar practice in any of your code that adds many triples at once.
Reports
db (which defaults to *db* unless specified). See db-room-list if you are interested in getting the information without having it printed.
db. This is used by the db-room function. The :db keyword argument defaults to *db*.
stream.
Indexing Triples
When triples are first added to the triple-store queries are performed by simple linear scanning. To avoid the cost of linear scans, triples can be indexed so that queries will be very fast. An AllegroGraph triple-store can have up to six different index flavors. Whether you need all six will depend on the sort of queries that you need to run. Each flavor is named by the order in which the triples are sorted. For example, if triples are sorted first on predicate, then object, subject, graph, and finally id, then the index flavor will be posgi. Here are the flavors AllegroGraph uses and the sorts of queries that they help optimize:
spogi get-triples _s_, ---, ---, ---
get-triples _s_, _p_, ---, ---
get-triples _s_, _p_, _o_, ---
posgi get-triples ---, _p_, ---, ---
get-triples ---, _p_, _o_, ---
ospgi get-triples ---, ---, _o_, ---
get-triples _s_, ---, _o_, ---
gspoi get-triples _s_, ---, ---, _g_
get-triples _s_, _p_, ---, _g_
get-triples _s_, _p_, _o_, _g_
gposi get-triples ---, _p_, ---, _g_
get-triples ---, _p_, _o_, _g_
gospi get-triples ---, ---, _o_, _g_
get-triples _s_, ---, _o_, _g_
Unless you tell it otherwise, AllegroGraph will assume that each new triple-store should have all six indices
7 . You can change this with the :with-indices argument to create-triple-store and by using add-index and drop-index to manage indices explicitly.
When to index
Regardless of which flavors you are using, you must still reckon with when and how to build indices. The function index-new-triples builds indices of just the currently unindexed triples and takes time proportional to the number of triples to be indexed. However at query time each index built with index-new-triples must be queried so calling index-new-triples too often will reduce the benefits of building the indices.
To get rid of the performance drag of having too many indices, you can use index-all-triples to build a unified index of all the triples in the triple-store. While this function can take time proportional to the total number of triples in the store, it can take advantage of the indices already built by index-new-triples to speed up indexing. In general the best strategy is to use index-new-triples to build indices after each large chunk of triples is added to the store and to periodically merge the indices with index-all-triples.
Adds a new index flavor to a triple-store.
The actual index data structure will be created the next time that AllegroGraph indexes the triple-store (either by a call to index-new-triples or index-all-triples or automatically through the management policy of the triple-store.)
The :db keyword argument specifies the triple-store to which to add the index and will be *db* unless otherwise specified.
The :location keyword argument controls the physical location of the index. It can be left unspecified or set to the location of a directory. If left unspecified, the index will be located in the same directory as the triple-store (see data-directory). If used, it should name an empty directory.
Flavor should be a valid index name (e.g., :posgi). See index-flavors in the reference guide for additional details
Adds several indices to a triple-store at once.
Flavors should be a list of valid index flavors. See add-index for additional details.
ag-property :standard-indices to a triple-store using add-indices.
Returns the average index-fragment-count for a triple-store. This is the total number of index chunks divided by the number of indices. The higher the chunk count, the more work each query must do to find results.
The keyword argument :db can be used to specify the triple-store to use. It defaults to *db*.
Remove an index from a triple-store.
The flavor argument should be a valid index flavor name that is currently an index of the triple-store.
The keyword argument :db controls the triple-store from which the index will be removed. It will default to *db* unless otherwise specified.
Flavor should be a valid index name (e.g., :posgi). See index-flavors in the reference guide for additional details
Remove several indices from a triple-store at once.
Flavors should be a list of valid index flavors that are indices of the triple-store. See drop-index for more details.
Create a unified index of all the triples in the triple store, including triples previously indexed. The time taken to index all triples includes the time index-new-triples plus the time to merge all index chunks. The first step is proportional to the number of unindexed triples multiplied by the logarithm of the same number (i.e., if N is the number of new triples, then the time is O(N log N)). The merge step is proportional to the total number of triples multiplied by the logarithm of the number of chunks. If you have a very large triple store to which you have added a fairly small number of new triples, you can use index-new-triples to get most of the benefits of indexing at much lower time cost.
Indexing can run as a background task in either the same Lisp process or on multiple remote Lisp processes (see the clustering documentation for more details). Index-all-triples return the task id of the indexing task that it creates.
The wait keyword argument controls whether index-all-triples returns immediately or waits for all indexing and merging to complete. It defaults to true. If it is false, you can use the id of the task returned to see if indexing has completed.
See the variable maximum-indexing-sort-chunk-size for information on controlling the indexing process.
flavor. The keyword argument :db can be used to specify the triple-store to use. It defaults to *db*.
Index the triples that have been added to the triple store since the last time indices were built. The time taken to index new triples is proportional to the number of unindexed triples multiplied by the logarithm of the same number (i.e., if N is the number of new triples, then the time is O(N log N)).
However, the new indices will not be merged with the older indices which will cause queries to execute more slowly. To maximize query performance you will want to use index-all-triples to build a unified index.
Indexing can run as a background task in either the same Lisp process or on multiple remote Lisp processes (see the clustering documentation for more details).
The wait keyword argument controls whether index-new-triples returns immediately or waits for all indexing to complete. It defaults to true. If it is false, then index-new-triples return the id of the indexing task that is created.
See the variable maximum-indexing-sort-chunk-size for information on controlling the indexing process.
stream.
Returns the status of the current triple-store as regards indexing. This can be one of:
:scheduled
:running
:needed
- :idle
merge-new-triples is a useful half-way measure. It will merge the small chunks into one (which should be quite fast). This will improve query performance without requiring a complete merge.
:db keyword argument specifies the triple store to use, either by name or a triple store object. It defaults to the value of *db*.
Returns a list of information on the indices of a triple-store.
The :db keyword argument specifies the triple-store on which to report.
The :verbose keyword argument controls how much information to return. If verbose is nil, then only the flavor-names are returned. If it is true, then a list of lists is returned where each sub-list starts with an index object and continues with ranges of the unindexed triples.
Advanced Triple-Store Operations
The !-reader macro and future-parts
When working with the triple-store at the REPL (the lisp listener) it's nice to have a more concise way to refer to resources and literals than with calls to resource, literal or the part interning functions. It's also handy to be able to abbreviate the many long URIs with a common prefix such as http://www.w3.org/2000/01/rdf-schema#. Namespaces and the !-reader macro provide a concise syntax for both resources and literals.
The first thing the !-reader macro allows you to do is write N-Triples strings without quotation marks (except for those required by the N-Triples syntax itself!). Thus instead of writing:
"<http://www.franz.com/>"
"\"foo\""
"\"foo\"^^<http://www.w3.org/2000/01/rdf-schema#integer>"
"\"foo\"@en"
you can simply write:
!<http://www.franz.com/>
!"foo"
!"foo"^^<http://www.w3.org/2000/01/rdf-schema#integer>
!"foo"@en
In addition, the !-reader macro uses namespaces to abbreviate long URIs. Use the register-namespace function to assign an abbreviation to any prefix used in URIs. For instance you can register s as an abbreviation for the URI prefix http://www.franz.com/simple# like this:
(register-namespace "s" "http://www.franz.com/simple#")
Then you can use that prefix with the !-reader macro to write URIs starting with that prefix:
!s:jans => !<http://www.franz.com/simple#jans>
You have probably noticed that the !-reader macro does not seem to be doing anything:
!"hello" => !"hello"
This is because ! is converting the string "hello" into what AllegroGraph calls a future-part and the future-part prints itself using the !-notation. If we describe the future-part, then we will see all of the additional structure:
> (describe !"hello")
!"hello" is a structure of type future-part. It has these slots:
type :literal
value-prefix nil
value-fragment "hello"
extra-prefix nil
extra-fragment nil
value "hello"
extra nil
extra-done-p t
upi #(5 0 0 0 0 0 111 108 108 101 104 7)
triple-db nil
Now it's clear that AllegroGraph has parsed the string and performed the computations to determine the part's UPI.
future-parts are called future-parts because they cache some of the information (e.g., the namespace prefix) and wait to resolve until the namespace mappings are available which may be in the future. Before we finish describing resolution, however, here are some examples. First, literals:
!"hello": equivalent to (literal "hello")!"hello"@en: equivalent to (literal "hello" :language "en")!"OK"^^<http://www.w3.org/2000/01/rdf-schema#XMLLiteral>: equivalent to (literal "OK" :datatype "http://www.w3.org/2000/01/rdf-schema#XMLLiteral")!"OK"^^rdfs:XMLLiteral: assuming that we have already registered the string "rdfs" with the namespace URI "http://www.w3.org/2000/01/rdf-schema#", then this is the same part as above.!"Careful"^^<rdfs:XMLLiteral>: this would be equivalent to (literal "bug" :datatype "rdfs:XMLLiteral") and is probably not what you intend.!"-- wrong --"^^XMLLiteral: this is an error since a type must be either a URI or a QName (Qualified name). I.e., it must either be bracketed with '<' and '>' or it must contain a ':'.
The story for resources is very similar:
!<http://www.franz.com/products#allegrograph>: equivalent to (resource "http://www.franz.com/products#allegrograph")!franz:allegrograph: assuming that we have already registered "franz" to map to "http://www.franz.com/products#", then this is the same part as above.!Wrong: this would be the URI "wrong" resolved using the current base URI. Since AllegroGraph does not support base URIs, such a part name is meaningless and will produce an error.!<smells-fishy:allegrograph>: equivalent to (resource "smells-fishy:allegrograph") and probably not what you intend.
Future parts are resolved when it is necessary to determine their UPI. If the part uses a namespace (e.g., is something like !a:b), then the namespace will be resolved first. It is an error to try and determine a part's UPI if the necessary namespace mapping has not been registered. Once the namespace of a part is resolved, then it will not be resolved again (during the current Lisp session). After namespace resolution, a future-part is equivalent to a particular string which can be interned into a triple-store (i.e., stored in the store's string dictionary).
Future-parts make working with AllegroGraph much simpler but they do contain some machinery and can be confusing. Remember that you can always tell what is happening by using the Lisp describe function.
The following are the functions used for enabling the ! reader macro and for managing namespaces.
:keep-standard-namespaces is true (the default) then the namespace mappings in standard-namespaces will not be removed.
register-namespace that can be used to recreate the original namespaces if needed later. If the optional file argument is provided, output is written to that file. Otherwise the output is sent to *standard-output*.
uriref associated with namespace-prefix or nil if there is no association.
fn to each namespace mapping. Fn must be a function of two arguments: the prefix and the uri.
namespace-prefix and uri-reference, both of which should be strings. If the errorp keyword argument, which defaults to the value of (ag-property :error-on-redefine-namespace), is true, then defining a mapping for an existing prefix will signal a continuable namespace-redefinition-error condition.
The standard-namespaces is a list of (name prefix) pairs representing namespace mappings. For example:
'(("rdf" "http://www.w3.org/1999/02/22-rdf-syntax-ns#")
("rdfs" "http://www.w3.org/2000/01/rdf-schema#")
("owl" "http://www.w3.org/2002/07/owl#"))
It is used by the function register-standard-namespaces to create standard mappings.
Triples and parts are represented by (simple-array (unsigned-byte 8) 56) and (simple-array (unsigned-byte 8) 12) respectively. By default the Lisp printer prints these as vectors of bytes which is not very informative when using AllegroGraph interactively. This function modifies a pprint-dispatch table to print triples and parts interpretively if this can be done in the current environment. Specifically, the value of db must be an open triple store, and the vector being printed must print without error in the manner of print-triple or upi->value. If any of these conditions don't hold the vector is printed normally.
If the boolean argument is true, the informative printing is enabled, otherwise disabled. The :pprint-dispatch argument specifies the dispatch table to modify, by default the value of print-pprint-dispatch. Once enable-print-decoded has been turned on, you can also use the special-variable *print-decoded* to enable fine-grained control of triple and UPI printing.
Clustering: indexing with multiple processors
AllegroGraph can use multiple processors (on the same machine or different machines) to dramatically increase indexing speed. This clustering ability is built on a more generic core from the net.cluster package which is itself built upon Allegro Common Lisp's RPC mechanisms. In practice, all you need to do is make sure that Allegro Common Lisp is installed on each machine that you want to use, setup your environment to tell AllegroGraph where the machines are located and then start indexing.
The details of setting up a network for clustering are outside of the scope of this reference though Franz will be including more information on-line in the coming months. You will want to make sure that all of the machines can access the data quickly over a shared drive. The easiest setup, of course, is to use a single computer with multiple processors or processor cores.
Use add-indexing-host to tell AllegroGraph what machines to use (and the net.cluster functions machines, remove-machine and remove-all-machines to manage them). You can optimize start-up time by calling start-remote-clients or start-all-remote-clients yourself. This starts another Lisp instance over the connection and prepares that instance to run tasks.
All of the functions that use background processes (such as indexing, merging and (eventually) querying) have a :wait parameter to let you specify if the task should wait until all processing is complete. You can learn more about the details of a task by use find-task on the return value of a function like index-all-triples to retrieve the task instance associated with a particular ID. Finally, you can use the indexing-status and unschedule-indexing functions to see the current state of a triple-store's indexing tasks.
:agraph-cluster-code-pathname and sys:agraph;agraph-cluster.fasl
identifier in the task-manager. The search will occur in pending tasks, running tasks and failed tasks. The kind of search depends on the type of identifier. If it is a number, then the match will be performed on the id of the task; if it is a symbol or a string, then the match will be performed on task-name; finally, if it is a task, then the task is just returned.
name.
Freetext Indexing
AllegroGraph 2.2 and beyond support freetext indexing on the objects of triples whose predicates have been registered for indexing. Currently, only triples added after a predicate has been registered will be indexed. 8 Once indexed, triples can be found using a simple but robust query language. Freetext indexing support includes functions to register predicates and see which predicates are registered:
Register predicate for freetext indexing in the triple-store db. Once registered, any triples with this predicate will have the string of their object indexed by AllegroGraph's built-in freetext indexer. Use the db keyword argument to specify the triple-store in which to register the predicate. If left unspecified, the predicate will be registered in triple-store *db*.
(register-freetext-predicate
!<http://www.w3.org/2000/01/rdf-schema#comment>)
Note that you have to register predicates before you add triples with that predicate. Older triples will not get indexed.
db. See register-freetext-predicate for more information.
predicate is registered for freetext indexing in the triple-store db. See register-freetext-predicate for more information.
It of course also includes several methods to query a triple-store for triples that match an expression:
Returns a list of ids of the triples whose object contains text matching the expression.
(freetext-get-ids "amsterdam")
(freetext-get-ids "\"Good girls go to heaven,
bad girls go to Amsterdam\"")
(freetext-get-ids '(and "amsterdam" "usa"))
(freetext-get-ids '(and "amst?r* (or "us?" "neth*")))
Returns a cursor that iterates over the triples whose objects contain text that matches the expression.
(iterate-cursor (triple (freetext-get-triples "amsterd*"))
(print triple))
Returns all the unique subjects in triples whose objects contain expression. This is a useful function in prolog queries. The following example is included in the tutorial.
(select (?person)
(lisp ?list
(freetext-get-unique-subjects '(and "collection" "people")))
(member ?person ?list)
(q- ?person !rdfs:subClassOf !c:AsianCitizenOrSubject))
Freetext Query Expressions
Here is the informal grammar used to build query expressions:
- pattern
- string-pattern | composite-pattern
- string-pattern
- string | phrase-string
- string
- "char*"
- char
- ? denotes a wild card that matches any single character
- char
- * denotes a wild card that matches any sequence of characters
- char
- \" denotes an escaped "
- char
- any any other character denotes itself
- phrase-string
- "\"this is a phrase\"" no ? and * allowed
- composite-pattern
- (and pattern*) | (or pattern*)
Data-type and Predicate Mapping
Most triple-stores work internally only with strings. AllegroGraph, however, can store a wide range of datatypes directly in its triples. This ability not only allows for huge reductions in triple-store size but also lets AllegroGraph execute range queries remarkably quickly. Use the supported-types function to see a list of datatypes that AllegroGraph can encode directly. The datatypes are specified as keywords or integers (with the integers being used internally). You can translate in either direction using type-code->type-name and type-name->type-code. You can add encoded-triples (i.e., triples some of whose parts are encoded UPIs rather than references to strings) directly using add-triple or by setting up mappings between particular predicates or specific datatypes and then using one of the bulk loading functions. In the former case, you use value->upi and in the later, you use datatype-mappings and predicate-mappings.
For example, we can add a triple that directly points to another by using the :triple-id AllegroGraph datatype. This provides a simple and light-weight reification mechanism but note that it is outside the boundaries of RDF. Here we add one triple that describes Gary's birthdate and another that says the first is wrong (see the section on simple reification for more details).
> (let ((new-id (add-triple !o:gary !o:birthdate
(value->upi "1924-03-13" :date))))
> (add-triple !o:data !o:incorrect (value->upi new-id :triple-id)))
As a second example, here is how to specify that the datatype xsd:double maps to an AllegroGraph :double-float and the predicate <http://www.example.com/predicate#age> maps to an :unsigned-byte
> (setf (datatype-mapping
"http://www.w3.org/2000/01/XMSchema#double") :double-float)
:double-float
> (setf (predicate-mapping
"http://www.example.com/predicate#age") :unsigned-byte)
:unsigned-byte
Now when you load an N-Triples file, AllegroGraph will example each triples to see if it satisfies the mappings. When it does, then an encoded-triple will be added to the triple-store. 9 Depending on your needs, you can even tell AllegroGraph to only load encoded-triples and not worry about strings at all. This can provide tremendous spaces savings and also gives you the benefit of range queries.
Returns the type encoding for part. Part should be XML Schema type designator. For example:
> (datatype-mapping "http://www.w3.org/2001/XMSchema#unsignedByte")
:unsigned-byte
The scope of the mapping is the db. Use (setf datatype-mapping) to add an association between a datatype and an encoded UPI type
Returns the type encoding for part. Part should be the URIref of a predicate. For example:
> (predicate-mapping !<http://www.example.org/property/height>)
:double-float
The scope of the mapping is the db. See (setf predicate-mapping) for more information. Setfable.
Returns a list of type names that can be used in value->upi to encode a string into an encoded UPI. To see the corresponding type code for a name, use the type-name->type-code function.
See the section on type mapping.
code. See type-name->type-code and supported-types for more details. The numbers can come from the type-names returned by supported-types or can correspond to RDF node types like blank nodes, resources and literals. The function returns nil if the code does not correspond to any type.
Returns the type code associated with the name. See type-code->type-name and supported-types. The name can be one of the supported-types or one of:
- :blank-node
- :resource
- :literal
- :literal-language
- :literal-short
- :literal-typed
The function returns nil if there is no type-code corresponding to name.
Decodes UPI and returns the value, the type-code and any extra information as multiple values.
upi- the UPI to decode:db- specifies the triple-store from which the UPI originates.
The value, type-code, and extra information are interpreted as follows:
- value - a string representing the contents of the UPI
- type-code - an integer corresponding to one of the defined UPI types (see supported-types for more information). You can use type-code->type-name to see the English name of the type.
- extra - Some encoded UPIs contain additional information which will be placed in
extraif it is there. Examples include the language code or datatype of a literal. If no extra information is present, thennilwill be returned as the extra information.
Examples:
> (upi->value (value->upi 22 :byte))
22
18
nil
> (upi->value (upi (literal "hello" :language "en")))
"hello"
3
"en"
See value->upi for additional information.
value into UPI as type of encode-as. The encode-as argument can be a type code or a type name (see supported-types and type-name->type-code for details. If a upi keyword argument is not supplied, then a new UPI will be created. See upi->value for information on retrieving the original value back from an encoded UPI.
Return a list of the datatype and predicate mappings of db.
- :db - defaults to *db*.
Each item in the list returned consists of a list of three elements:
- the URIref used for the mapping (predicate or datatype)
- the type-code of the mapping
- a keyword that indicates if the mapping is a
:datatypeor:predicatemapping.
Applies fn to each datatype and predicate mapping of db.
- :db - defaults to *db*.
fn should be a function of three arguments. For each mapping, it will called with
- the URIref used for the mapping (predicate or datatype)
- the type-code of the mapping
- a keyword that indicates if the mapping is a
:datatypeor:predicatemapping.
(See collect-all-type-mappings if you just want a list of the mappings.).
Federation
Managing Massive Data - Federation
The block diagram we saw above is abstract: it can be implemented in many different ways. AllegroGraph 3.0 uses the same programming API to connect to local triple-stores (either on-disk or in-memory), remote-triple-stores and the entirely new federated triple-store. A federated store collects multiple triple-stores of any kind into a single virtual store that can be manipulated as if it were a simple local-store. Federation provides three big benefits:
- it scales well,
- it makes triple-stores more manageable, and
- it makes data archive extremely simple.
A high-level description of these benefits is provided in the AllegroGraph introduction. This guide focuses on the classes that are used to build a federation. You can find examples in the federation tutorial and learning center.
AllegroGraph's internal architecture
Internally, an open AllegroGraph triple-store is an instance of one of the classes depicted below. Most of the time, you won't need to be concerned with this class implementation because AllegroGraph will manage it transparently. We're depicting them here because they also serve to illustrate many of AllegroGraph's capabilities.
Let's look at each of these in turn.
An Abstract-triple-store defines the main interfaces a triple-store must implement. This class has four main subclasses:
concrete-triple-stores manage actual triples whereas the other three function as wrappers between real triples and the store.
federated-triple-stores provide mechanisms to group and structure arbitrary collections of other triple-stores.
Encapsulated-triple-stores let us add new behaviors to existing stores in a controlled and easily optimized fashion. The best example of an encapsulated-store is a reasoning-triple-store which endow triple-stores with RDFS++, rule based or other reasoning engines.
Finally, a remote-triple-store lets AllegroGraph use triple-stores being served by other processes either locally or anywhere on the network. These triple-stores can be other AllegroGraph stores or connections to Oracle and Sesame ones. 10
By combining these four classes, you can build a triple-store composed of leaf stores from anywhere, implementing differing reasoning rules, from entirely different architectures and treat them as if they comprise a single unified store living on your desktop.
Create a new encapsulated-triple-store wrapping db and and return it.
The new store will be named name and will be of type wrapper-class (which must be a subclass of encapsulated-triple-store. The additional wrapper-args are passed along to the newly created store.
name which federates each of the triple-stores listed in stores. This also sets *db* to the value of the federated store. .
Removes one layer of encapsulation from an encapsulated-triple-store and returns the triple-store that was encapsulated.
If store is not encapsulated, then this returns store unchanged. See encapsulate-triple-store for details.
Note AllegroGraph's federated triple-stores help solve problems associated with the management and understanding of massive datasets -- AllegroGraph does not keep track of where those datasets live or how to access them. You are responsible for finding each leaf triple-store and configuring them as best suits your particular problem space. You are also responsible for ensuring that leaf triple-stores remain open for as long as the federation is in use. Franz will continue to enhance AllegroGraph's federation support and the persistence of complex relationships between triple-stores. Please be sure you are using the most recent release of AllegroGraph and to contact us ([email protected]) if you have any questions or issues.
Federation, triple-ids, default-graphs and blank nodes
Federation adds a new ambiguity to triples, the default-graph and blank node identifiers: from which leaf store did they come? To see the sort of problem that can arise, imagine that we federate two small stores into one as in the figure below:

Now let's try a simple query: What is the rdf:type of the thing whose ex:isNamed is <Gary>? To answer this, we would first ask for the triples whose predicate is ex:isNamed and whose object is <Gary> and find this:
_:anon1 ex:isNamed "Gary"
then we would ask for the triples whose subject is _:anon1 and whose predicate is rdf:type. If the federation could not tell blank nodes from different stores apart, then it would give us back two answers:
_anon1 rdf:type <Human>
_anon1 rdf:type <Dog>
and that would be wrong!
To prevent this, AllegroGraph keeps track of the originating triple-store for each blank node, triple-id and default-graph UPI. If you look at any of these UPIs or triples in its raw form (i.e., if enable-print-decoded is nil), then you will see that some of the bytes in these data-structures encode the triple-store's ID.
Franz is still exploring the semantics surrounding some of these issues (for example, sometimes if may make more sense to allow multiple leaf stores to use the same default-graph UPI) and will continue to improve federation support by making it more flexible without giving up its speed or ease of use.
Simple Reification
Suppose I have triple t that states s p o and I want to further claim that I believe it. I'd like to say:
- name:Gary believes t
This ability to talk about an assertion is called reification. In RDF, reifying a triple requires creating a new blank node (_:anon) so that we can say
- name:Gary believes _:anon
and then making (at least) four assertions:
- _:anon is rdf:type rdfs:Statement,
- _:anon has rdfs:subject s,
- _:anon has rdfs:predicate p , and
- _:anon has rdf:object o
This is a lot of work when all we really want is to say something about an assertion. Because AllegroGraph provides both persistent triple-ids and encoded UPIs, we can reify another triple by saying simply:
- name:Gary believes [the triple-id of t]
In Java, the code for this would look like:
AllegroGraph ag;
Triple t;
...
ag.addStatement("<name:Gary>", "<some:believes>",
ag.createEncodedLiteral(t.queryAGId(), "triple-id"));
and in Lisp, we would use value->upi with a type-code of +triple-id-tag+. You can find another example and more discussion of AllegroGraph's direct reification in the AllegroGraph Tutorial.
SPARQL Query Language
parse-sparql takes a string and parses it into an s-expression format. A parse error will result in a sparql-parse-error being raised.
This function is useful for three reasons: validation and inspection of queries, manual manipulation of query expressions without text processing, and performing parsing at a more convenient time than during query execution.
You do not need an open triple store in order to parse a query.
default-base and default-prefixes allow you to provide BASE and PREFIX arguments to the parser without inserting them textually into the query.
default-base should be nil or a string, and default-prefixes can either be a hash-table (string prefix to string expansion) or a list similar to db.agraph:*standard-namespaces*.
parse-sparql returns the s-expression representation of the query string.
run-sparql takes a SPARQL query as input and returns bindings or new triples as output.
Since AllegroGraph 3.0 it is a convenient wrapper for the db-run-sparql methods specialized on particular database classes and query engines. You might consider using those methods directly to gain more control over the execution of your queries.
You should consider specifying an engine argument to your queries; the choice of default execution engine is not guaranteed to remain the same in future releases.
The precise arguments used vary according to the query engine; these are the typical arguments expected by the default engine.
SELECT and ASK query results will be presented in results-format, whilst the RDF output of DESCRIBE and CONSTRUCT will be serialized according to rdf-format. If the format is programmatic (that is, it is intended to return values rather than print a representation; :arrays is an example) then any results will be returned as the first value, and nothing will be printed on output-stream.
The
querycan be a string, which will be parsed byparse-sparql, or an s-expression as produced byparse-sparql. If you expect to run a query many times, you can avoid some parser overhead by parsing your query once and callingrun-sparqlwith the parsed representation.If
queryis a string, thendefault-baseanddefault-prefixesare provided to parse-sparql to use when parsing the query. See the documentation for that function for details. Parser errors signaled within parse-sparql will be propagated onwards byrun-sparql.Results or new triples will be serialized to
output-stream. If a programmatic format is chosen for output, the stream is irrelevant. An error will be signaled ifoutput-streamis not astream,t, ornil.If
limit,offset,from, orfrom-namedare provided, they override the corresponding values specified in the query string itself. AsFROMandFROM NAMEDtogether define a dataset, and the SPARQL Protocol specification states that a dataset specified in the protocol (in this case, the programmatic API) overrides that in the query, if eitherfromorfrom-namedare non-nilthen any dataset specifications in the query are ignored. You can specify that the contents of the query are to be partially overridden by providingtas the value of one of these arguments. This is interpreted as 'use the contents of the query'.fromandfrom-namedshould be lists of URIs.default-dataset-behaviorcontrols how the query engine builds the dataset environment ifFROMorFROM NAMEDare not provided. Valid options are:all(ignore graphs; include all triples) and:default(include only the store's default graph).with-variablesshould be an alist of symbols and values. Before the query is executed, the variables named after symbols will be bound to the provided values. This allows you to use variables in your query which are externally imposed, or generated by other queries. The format expected bywith-variablesis the same as that used for each element of the list returned by the:alistsresults-format.db(*db*by default) specifies the triple store against which queries should run.If
verbosepis non-nil, status information is written to*sparql-log-stream*(*standard-output*by default).
Three additional extensions are provided for your use.
If
extendedpis true (or*use-extended-sparql-verbs-p*is true, and the argument omitted) some additional SPARQL verbs become available.SUM,AVERAGE,MEDIAN,STATS,CORRELATION, andCOUNTcan all be used in place ofSELECT. These verbs are still experimental and undocumented.If
memoizepis true (or*build-filter-memoizes-p*is true, and the argument omitted) calls to SPARQL query functions (such asSTR,fn:matches, and extension functions) will be memoized for the duration of the query. For most queries this will yield speed increases whenFILTERorORDER BYare used, at the cost of additional memory consumption (and consequent GC activity). For some queries (those where repetition of function calls is rare) the cost of memoization will outweigh the benefits. In large queries which call SPARQL functions on many values, the size of the memos can grow large.
Memoization also requires that your extension functions do not depend on side-effects. The standard library is correct in this regard.
- You can achieve substantial speed increases by sharing your memos between queries. Create a normal
eqlhash-table with(make-hash-table), passing it as the value of thememosargument torun-sparql. This hash-table will gradually fill with memos for each used query function.
If you wish to globally enable memoization, set the variables as follows:
(progn
(setf *build-filter-memoizes-p* t)
(setf *sparql-sop-memos* (make-hash-table)))
Be aware that the size of *sparql-sop-memos* could grow very large indeed. You might consider using a weak hash-table, or periodically discarding the contents of the hash-table.
load-functionis a function with signature(uri db &optional type)ornil. If it is a function, it is called once for eachFROMandFROM NAMEDparameter making up the dataset of the query. The execution of the query commences once each parameter has been processed. Thetypeargument is either:fromor:from-named, and theuriargument is a part (ordinarily afuture-part) naming a URI. The default value is taken from*dataset-load-function*. You can use this hook function to implement loading of RDF before the query is executed.
The values returned by run-sparql are dependent on the verb used. The first value is typically disregarded in the case of results being written to output-stream. If output-stream is nil, the first value will be the results collected into a string (similar to the way in which cl:format operates).
The second value is the query verb: one of :select, :ask, :construct, or :describe. Other values are possible in extended mode.
The third value, for SELECT queries only, is a list of variables. This list can be used as a key into the values returned by the :arrays and lists results formats, amongst other things.
Individual results formats are permitted to return additional values.
format argument. See the documentation for run-sparql for more information.
Run the provided query, using the results to construct a new graph. The new graph is either returned or serialized onto output-stream as specified by the format argument. construct-pattern must be a list of triple patterns. query-pattern is used as input to run-sparql-select.
See the documentation for run-sparql for more information.
UPI coercion depends on the current value of db!
Run the provided query, using the results to construct a new graph. The new graph is either returned or serialized onto output-stream as specified by the format argument. targets is a list of resources to describe. query is used as input to run-sparql-select to yield further resources to describe.
See the documentation for run-sparql for more information.
Run the provided query, serializing the results as specified by the format argument. :distinct can be t or :distinct, meaning full DISTINCT processing, or :reduced, which optionally discards duplicates.
See the documentation for run-sparql for more information.
Return a list of alists, each of which contains the values for the requested variables in order.
If variables is not provided, you can find the names of the ones returned in the second return value.
Return a list of lists, each of which contains the values for the requestedvariables in order.
If variables is not provided, you can find the names of the ones returned in the second return value.
Prolog Select
The q and q- functors
The main interface to Prolog is the function q- (for simple query). The q- functor is analogous to get-triples. There are many versions of the functor but the simplest one has three arguments (for subject, predicate and object). You can supply any combination of these arguments and the functor will iterate over all of the possible matches in the triple-store, unifying its logic variables to each result in turn. The example below assumes that enable-print-decoded is active.
> (?- (q- ?x !rdf:type ?z))
?x = {http://example/ok#ViewDerivedObject}
?z = {owl:Class}
;; type Enter
?x = {http://example/ok#UserActions}
?z = {owl:Class}
;; type period ( . )
This documentation uses the usual Prolog argument notation. A + prefix on an argument indicates that is must be supplied (it is input to the predicate), a - prefix indicates the argument is output and must not be supplied, and a ± prefix indicates the argument may be either.
As is usual with Prolog, you can stop the iteration by typing a period (' . '). The q- variant of the query functor even supports AllegroGraph range queries.
Query a triple-store's inner store. If the store is a simple-store, then q- is equivalent to q Unify s, p, and o with the triples in the store.
Execute a range query for triples whose object is between o-min and o-max. Unify s and p.
Unify s, p, o, and g with the triples in the store.
Execute a range query for triples whose graph is between g-min and g-max. Unify s,p, and o.
Execute a range query for triples whose object is between o-min and o-max. Unify s,p and g.
Unify s, p, o, g, and id with the triples in the store.
Execute a range query for triples whose graph is between g-min and g-max. Unify s,p, o and id.
Execute a range query for triples whose object is between o-min and o-max. Unify s,p, g and id.
Execute a range query for triples whose graph is between g-min and g-max. Unify s,p, o, id and triple.
Query the triple-store. If the store is a simple store, then q is the same as q-. If the store is an encapsulated-triple-store (for example, a reasoning-triple-store) then q and q- will differ.
the select macros
You can combine multiple q clauses into a query using one of the family of select macros. These evaluate a list of Prolog clauses and then do something with the solutions found 11 . There are three dimensions in which this family of macros differ:
distinct - if the macro has
distinctin its name, then each unique solution is only returned once, i.e., it will only occur in the result set once or only be used as a callback once.translation - If the macro has a
0(zero) in its name, then it will return solutions whose UPIs are not-translated. Otherwise, it will look up the UPIs in the string dictionary and return those. Operations like select0 can therefore be much faster than select and are more natural if the UPI will be used in a further query.callbacks - If the macro has
callbackin its name, then you must provide a callback function that will accept a solution and do something with it. The callback function argument is evaluated and may be either a function of one argument or the name of such a function.
Each macro takes as its first argument a template. Often the template is a a single var or a simple list of vars. But in general the template may be a tree composed of Lisp data and Prolog variables
The select macros will find each solution to the list of supplied Prolog clauses. It will then build up a fresh instance of the template tree with each Prolog var in the tree replaced by the variable in the solution. For example:
> (select ((:name ?name) (:age ?age))
(q- ?x ?isa !ex:person)
(q- ?x ?hasname ?name)
(q- ?x ?hasage ?age))
would return a list of results like
(((:name "Gary") (:age 12))
((:name "Xaviar") (:age 56))
...
)
You can find other examples of using select in the Using Prolog with AllegroGraph tutorial.
clauses and return a list of all solutions. Each solution is a copy of the template (which is a tree) where each Prolog variable is replaced by its string value. See select0 if you want UPIs rather than strings.
clauses and return a list of all solutions. Solutions consist fresh copies of the template (which is a tree) where each Prolog variable in the tree is replaced by its UPI value in the solution. If you are interested in part-names rather than raw UPIs, see select.
callback once for each solution. Solutions consist of a fresh copy of the template with each var replaced by the string value of the Prolog variable in the solution. The callback argument is evaluated. See select0/callback if you are want UPIs rather than strings.
callback once for each solution. Each solution is a copy of the template with each Prolog variable replaced by its UPI. The callback argument is evaluated. See select/callback if you want strings rather than UPIs.
clauses and return a list of all distinct solutions. Each solution is a copy of the template where each Prolog variable in the tree is replaced by its string value See select0-distinct if you want UPIs rather than strings.
clauses and return a list of all distinct solutions. Each solution is a copy of the template (which is a tree) where each Prolog variable is replaced by its UPI value. See select-distinct if you want strings rather than UPIs,
callback once for each distinct solution. Each solution is a fresh copy of the template with each var replaced by the string value of the Prolog variable in the solution. The callback argument is evaluated. See select0-distinct/callback if you want UPIs rather than strings.
callback once for each distinct solution. Each solution is a fresh copy of the template with each var replaced by the UPI value of the Prolog variable in the solution. The callback argument is evaluated. See select-distinct/callback if you want strings rather than UPIs.
Prolog and range queries
You can make range queries using the same prolog q functor as you do to make non-range queries. We support range queries on either the object or the graph fields (but not on both simultaneously in the same clause. What follows is a list of all the 9 possibilities for q. Each token in the functor may be a UPI literal, a Prolog variable (possibly anonymous) or nil. We use a - prefix on a token to indicate that it is a placeholder and it cannot be used as a variable; a + prefix to indicate that the token must be supplied and a ? to indicate that the token is either. .
Suppose, for example, that we use AllegroGraph to record the velocities during a mythical 1000-km trip:
;;;;;;;;;;;;;;;;;;;; A 1000 KM trip.
(in-package :triple-store-user)
(create-triple-store "My1000KmTrip" :if-exists :supersede)
(register-namespace "t" "http://www.me.disorg#"
:errorp nil)
;; add triples describing a 1000-km trip
(loop with km = 0 ; distance in km
with time = 0 ; time in seconds
as kmh = (random 80.0) ; velocity in km/hr
do (add-triple
!t:me
!t:distance
(value->upi km :double-float)
:g (value->upi time :unsigned-long))
(add-triple
!t:me
!t:velocity
(value->upi kmh :double-float)
:g (value->upi time :unsigned-long))
(incf km (/ kmh 60))
(incf time 60)
count 1 ; Number of data points, which is
; also the duration in minutes.
while (< km 1000))
(index-all-triples)
We can then use the following select query to find triples that represent the 1-minute periods where average speed is 75..80 km/h and the distance at which it occurred.
(loop for (time speed distance)
in (sort (select (?time ?v ?distance)
(lisp ?v75 (value->upi 75 :double-float))
(lisp ?v80 (value->upi 80 :double-float))
(q- !t:me !t:velocity (?v ?v75 ?v80) ?time)
(q- !t:me !t:distance ?distance ?time))
(lambda (x y) (< (first x) (first y))))
do (format t "~7d ~5f ~5f~%" (/ time 60) speed distance))
This last form could be written more succinctly using the ++ syntax explained in the tutorial:
(loop for (time speed distance)
in (sort (select (?time ?v ?distance)
(q- !t:me
!t:velocity
(?v (value->upi 75 :double-float)
(value->upi 80 :double-float))
?time)
(q- !t:me !t:distance ?distance ?time))
(lambda (x y) (< (first x) (first y))))
do (format t "~7d ~5f ~5f~%" (/ time 60) speed distance))
Other AllegroGraph Prolog functors
subject with the subject field of triple.
predicate with the predicate field of triple.
object with the object field of triple.
graph with the graph field of triple.
triple-id with the triple-id field of triple.
part1 is part= to part2. Each of part1 and part2 should be UPIs, future-parts or strings in N-Triples format that can be converted into resources or literals.
RDFS++ Reasoning
The following additional functions and variables are also part of the reasoner:
Return a new reasoning-triple-store that encapsulates db and adds an rdfs++-reasoner.
db- the triple-store to encapsulate. The defaults to the value of *db*.name- the name to give the encapsulated-triple-store. Defaults to the current db-name of thedbwith rdfs++- prepended.
db. The new store will have a reasoner of reasoner-class and be named name.
triple is the result of inference (as opposed to be physically present in the triple-store).
reasoner of a reasoning-triple-store.
Deprecated. This variable will be removed in a future version of AllegroGraph. If your triple-store reasoning needs are simple, you can query the inner-triple-store of a reasoning-triple-store. See the reference guide for more information.
If true, then the RDFS++ reasoner will be used in queries. This will effect get-triples and the output of SPARQL and Prolog select queries.
Prepare-reasoning is a function called internally by the AllegroGraph reasoner. It is unlikely that you will ever need to call it yourself. Its purpose is to update the internal data structures used by the reasoner.
This function has to be called before any inferences are made. It creates internal hash-tables to speed up the reasoner. In normal operation, AllegroGraph will call prepare-reasoning as necessary. You can see diagnostic messages by using the parameter verbose which defaults to the value of (ag-property :verbose-prepare-reasoning). You can also force the hash-tables to be regenerated using the force parameter. Finally, the show-progress keyword argument can be used to cause prepare-reasoning to print a message for each of the hash-tables it builds.
The function prepare-reasoning returns no value.
HTTP and Sesame Support
AllegroGraph supports a client/server environment for clients implemented in Lisp or in Java. The Lisp client API is described in Lisp Client Reference and the Java client API is described in Java Tutorial and Javadocs.
The Lisp server is managed with the following functions exported from db.agraph.
Start a server that allows client programs to access AllegroGraph triple stores.
The port argument (default 4567) is the port number where the server listens for connections.
The jport argument is unused but reserved for situations where two ports are required.
The users argument specifies the number of simultaneous connections allowed. The default is 50.
The limit argument specifies the total number of connections allowed over the life of the server. The default is nil to specify unlimited connections.
The root argument, when non-nil, specifies a default pathname for the entire Lisp image running the server.
The nanny argument may be nil or a number n of seconds. When non-nil, all connections are scanned every n seconds and triple stores opened by dead connections are closed.
The ender argument specifies a function of no arguments. This function is called just before the triple store associated with a dead connection is closed.
The timeout argument specifies a time interval in seconds. If a triple store cannot be accessed within this time interval, an error is signaled.
The idle-life argument specifies a time interval in seconds. If a triple store is open but idle for this interval, it is closed automatically (and re-opened if needed). The default is 24 hours, i.e. (* 24 60 60).
The indexing argument is currently ignored.
The worker-stream argument specifies a stream that worker threads can use for random output. The value nil specifies the system default. The value t specifies initial-terminal-io. Any other value must be a suitable stream. When running the server under the Franz Emacs-Lisp interface, the value t may be needed to avoid background-stream errors.
The error-log argument specifies a stream or file path where error information can be printed. The default is nil. When nil, the error information is sent to the client. When t, print error information on the server console. When :none, error information is not generated at all.
The verbose and debug arguments may be non-nil to trigger status and progress messages.
The eval-in-server-file is nil (evalInServer not allowed) or is a filename where each line is a regular expression of a valid evalInServer command
The function returns two values: a server port instance that becomes the default server port, and the port number where the server is listening.
Method (agj-server)
Stop the connection identified by the argument.
Method (integer)
Stop the connection identified by integer.
Method (agj-server)
Stop the listening server. If the optional argument is non-nil, stop any running connections as well. The default is t.
Method (null)
Stop the default listening server. If the optional argument is non-nil, stop any running connections as well. The default is t.
This function enables or disables progress messages from client calls. The arguments and results of each call from the client are printed.
The onoff argument may be omitted, nil, :toggle, :close, a string, or any other non-nil value.
Two values are returned, the previous trace state and the new trace state, in that order.
If the argument is omitted, the function returns the current trace state.
If the argument is nil, a previous trace state is terminated.
If the argument is :toggle, the current trace state is reversed.
If the argument is :close, a previous trace state is terminated.
If the argument is a string, it should be a pathname to a writable file. The file is opened and supersedes any existing file. Trace output is initiated, and sent to the file.
- Any other non-nil value initiates trace output to standard-output.
This function maps triple store integer ids to the actual triple store instance.
The client code references each triple store by an integer identifier. This integer is printed in the ag-server-trace output.
If the tsx argument is nil or unspecified, the function returns an alist of all known triple stores.
If the tsx argument is an integer, the function returns the specified triple store instance.
- If the setdb argument is non-nil, then the current (global) value of
*db*is set to the triple store instance.
This symbol is not used in AllegroGraph 3.0.
Global default value of indexing parameter: ((min % max) (min avg max))
value argument may three possible values. nil is the default and initial value and allows select queries that have no escapes to Lisp code, that is, queries that do not contain the ?? syntax or calls to any of the lisp, lisp*, etc. functors. The value t allows all queries without checking, and is appropriatge only for environnments where clients can be trusted. The value :disallow blocks any use of select by clients.
Sesame
A sesame-server is an instance of the sesame-server class. It represents a server at a given host and port that can handle Sesame 2.0 HTTP requests. See the HTTP protocol reference for additional details.
This function creates a sesame-server instance and optionally starts the HTTP server. The returned value is the server instance. This value also becomes the default server.
The path argument (default is /sesame) specifies the initial part of the server URL.
The timeout argument is the default timeout value for all registered triple stores. If a triple store is not available within that number of seconds, a bad request return code is sent back to the client. The default is 15 seconds.
The idle-life argument is the default idle interval in seconds for an open triple store. If a triple store stays open but idle for this interval, it is closed automatically. The default is 24 hours.
The start argument, if non-nil, ensures that the HTTP server is running. If the value is a list, it is passed to the AllegroServe start function. The most common value is (list :port nnn).
The wserver argument may be an AllegroServe wserver instance.
The class argument (default sesame-server) allows applications to provide a sub-class.
The output-stream argument is a synonym for worker-stream retained for compatibility with previous versions of AllegroGraph. If the worker-stream argument is specified, the output-stream argument is ignored.
- If the worker-stream argument is specified, it must be a stream. This stream will be bound to standard-output, terminal-io, and debug-io in worker threads running Sesame HTTP requests. Binding this argument to initial-terminal-io may be needed when running under eli.
When the server argument is an instance of sesame-server, start that Sesame server instance.
When the server argument is nil, start a Sesame server using the default server instance.
When the server argument is an instance of sesame-server, stop that Sesame server instance.
When the server argument is nil, stop the default Sesame server instance.
When the server argument is an instance of sesame-server, make a triple store available as a Sesame 2.0 Remote Repository on that server.
If db is specified, name and directory must be omitted or consistent. If name and directory are specified, db must be omitted or consistent.
The specified database will be opened and closed as required.
Id defaults to name; it is the id by which the database will be known to clients. If id is not unique, an error is signaled.
When the server argument is nil, make a triple store available as a Sesame 2.0 Remote Repository. The default server instance is used for the operation.
Method (sesame-server)
Return the port number where this server is listening.
Method (null)
Return the port number where the default Sesame HTTP server is listening.
value argument may three possible values. nil is the default and initial value and allows select queries that have no escapes to Lisp code, that is, queries that do not contain the ?? syntax or calls to any of the lisp, lisp*, etc. functors. The value t allows all queries without checking, and is appropriatge only for environnments where clients can be trusted. The value :disallow blocks any use of select by clients.
Specialized Datatypes
In addition to the "encoded UPIs" for the various computer numeric datatypes, AllegroGraph supports several specialized datatypes for efficient storage, manipulation, and search of Social Network, Geospatial and Temporal information.
Social Network Analysis
By viewing interactions as connections a in graph, we can treat a multitude of different situations using the tools of Social Network Analysis (SNA). SNA lets us answer questions like:
How closely connected are any two individuals?
What are the core groups or clusters within the data?
How important is this person (or company) to the flow of information?
How likely is it that this person and that person know one another?
The field is full of rich mathematical techniques and powerful algorithms. AllegroGraph's SNA toolkit includes an array of search methods, tools for measuring centrality and importance, and the building blocks for creating more specialized measures. These tools can be used with any "network" data set whether its connections between companies and directors, predator/prey food webs, chemical interactions, or links between web sites.
Navigating Through a Graph - Generators
The graph functions described below all use generators in their definitions. A generator is a function of one-argument, a vertex, that returns a list of nodes that are connected to the vertex. The definition of connected depends on the generator. In a directed graph, connected may refer only to the nodes that point to a specific vertex or it may refer to the nodes at which the vertex points. Generators can also ignore edge direction in a graph and return a list of nodes that are adjacent to the specific vertex.
We provide several helper utilities and a generator definition language to define both simple ad complex generator functions. When the graph operations below take a generator as argument, you may supply either a function of one argument or the name of a generator that has been defined using the generator definition language.
the Generator Definition Language
The language consists of
(:objects-of &key node p)(:subjects-of &key node p)(:undirected &key p)(select var select-clause*)
Define a new SNA generator function and associate it with `name.
Returns the new function. The function is defined using a simple language. See the reference guide for details on the syntax and semantics of this language.
Lookup a defined sna-generator by name and return its associated function.
name can be a generator function itself (in which case it is simply returned) or a symbol naming an existing function or the name of a generator previously defined with the defsna-generator macro.
name with an SNA generator function. Returns the new function. If the function is nil, then the association is removed.
Notes
The generator returns the (distinct) union of the UPIs found by the clauses.
In both
:objects-ofand:subjects-of, thenodeparameter is syntactic sugar and can be left off.In all three of
:objects-of,:subjects-of, and:undirected, thepvariable can be a single property or a list of properties
Examples
(register-namespace "ex" "http://namespace.franz.com/namespace#")
(defsna-generator involved-with ()
(:objects-of :p (!ex:kisses !ex:intimateWith)))
(defsna-generator involved-with (node)
(:objects-of :node node :p (!ex:kisses !ex:intimateWith)))
(defsna-generator involved-with ()
(:undirected :p (!ex:kisses !ex:intimateWith)))
(defsna-generator in-movie-with (node)
(select (?x)
(q- ?x !franz:stars (?? node))))
(Note the use of Allegro Prolog ?? idiom that we use to treat the symbol node as a variable in the body of the macro.)
Search
There are many ways to search in a graph and the one you choose will depend both on the application and on the kind of graph data you have collected. The SNA library provides multiple search functions whose operation is controlled by generators as defined above. Most operations come in several flavors. For example,
- breadth-first-search - returns whether or not you can get there from here.
- map-breadth-first-search-paths - applies a function to each possible path from here to there
- all-breadth-first-search-paths - collects and returns a list of all the paths from here to there.
We also provide an additional set of search functions specialized for bipartite graphs.
Search db in breadth first fashion starting at start and looking for end, using generator to expand the search space. Returns nil if no path can be found (within depth) and the first such path found otherwise. The arguments are:
- start - a UPI or future-part or string that can be converted into a UPI.
- end - a UPI, future-part or string that can be converted into a UPI.
- generator - a function of one argument or a generator name. See the description of generators for additional details.
- maximum-depth - If supplied, this restricts the length of the paths searched. Only paths (from
start) less than or equal to this will be checked. If maximum-depth is not specified, it defaults tonilwhich means to search all paths. Warning in large graphs this can be very expensive.
fn to each path between start and end using generator to determine adjacent nodes and breadth-first-search to find paths.
start and end using generator to determine adjacent nodes and breadth-first-search to find paths.
Search db in depth first fashion starting at start and looking for end, using generator to expand the search space. Returns nil if no path can be found (within depth) and the first path found otherwise. The arguments are:
- start - a UPI, future-part or string that can be converted into a UPI.
- end - a UPI, future-part or string that can be converted into a UPI.
- generator - a function of one argument or a generator name. See the description of generators for additional details.
- maximum-depth - If supplied, this restricts the length of the paths searched. Only paths (from
start) less than or equal to this will be checked. If maximum-depth is not specified, it defaults tonilwhich means to search all paths. Warning in large graphs this can be very expensive.
fn to each path between start and end using generator to determine adjacent nodes and depth-first-search to find paths.
start and end using generator to determine adjacent nodes and depth-first-search to find paths.
start and end (using generator to determine when two nodes are adjacent.
fn to each path between start and end using generator to determine adjacent nodes and bidirectional-search to find paths.
start and end using generator to determine adjacent nodes and bidirectional-search to find paths.
Bipartite graphs
fn to each path between start and end using generator-1 and generator-2 to determine adjacent nodes and breadth-first-search to find paths. The function assumes that generator-1 can be used on the start node; the node type of the end node does not matter.
fn to each path between start and end using generator-1 and generator-2 to determine adjacent nodes and depth-first-search to find paths. The function assumes that generator-1 can be used on the start node; the node type of the end node does not matter.
fn to each path between start and end using generator-1 and generator-2 to determine adjacent nodes and bidirectional-search to find paths.
Graphs Measures
There are many ways to measure information about a graph and its structure. Some of these focus on the graph as a whole while others target particular actors (vertices).
Who is nearby
nodal-neighbors returns a list of other nodes that can be reached from node by following an edge. Node should be a vertex in the graph represented by the triple-store; See the description of generators for additional details.
Note that the nodal-degree of a node is the same as `(length (nodal-neighbors node)). See noda-degree for additional details.
The nodal-degree of node is the total number of edges that connect it to other nodes in the graph. Edges are found using the generator. See the description of generators for additional details.
Note that the interpretation of nodal-degree depends entirely on the generator being using in the calculation. Suppose, for example, that we have a graph with three nodes and two edges:
A --> B <-- C
and that these are encoded in AllegroGraph as
!ex:A !ex:linksTo !ex:B
!ex:C !ex:linksTo !ex:B
If we define three generators:
(defsna-generator linksTo (node)
(:objects-of :p !ex:linksTo))
(defsna-generator linksFrom (node)
(:subject-of :p !ex:linksTo))
(defsna-generator links (node)
(:undirected :p !ex:linksTo))
then we will find that
> (nodal-degree !ex:B 'linksTo)
0
> (nodal-degree !ex:B 'linksFrom)
2
> (nodal-degree !ex:B 'links)
2
Finally, note that nodal-degree is the same as the length of the list of nodes returned by nodal-neighbors.
nodes ego group. These are the other nodes in the graph (represented by the triple-store) that can be reached by following paths of at most length depth starting at node. The paths are determined using the generator to select neighbors of each node in the ego-group. See the description of generators for additional details.
Centrality Measures
The centrality of an actor in a network is a measure of its prestige or importance or power. There are many ways to measure it and the best way varies with the application.
Actor is a node in the graph; group is a list of nodes (e.g., the actor's ego group) and generator is either a function or name. See the description of generators for additional details.
An actor centrality measure provides insight into how central or important an actor is in the group. Closeness-centrality is the (normalized) inverse average path length of all the shortest paths between the actor and every other member of the group. (The inverse so that higher values indicate more central actors).
Actor is a node in the graph; group is a list of nodes (e.g., the actor's ego group) and generator is either a function or name. See the description of generators for additional details.
An actor centrality measure provides insight into how central or important an actor is in the group. Betweenness-centrality measures how much control an actor has over communication in the group.
The actor-betweenness-centrality of actor i is computed by counting the number of shortest paths between all pairs of actors (not including i) that pass through actor i. The assumption being that this is the chance that actor i can control the interaction between j and k.
Actor is a node in the graph; group is a list of nodes (e.g., the actor's ego group) and generator is either a function or name. See the description of generators for additional details.
Cliques
In graph theory, a clique is a fully connected subgraph in a larger graph. AllegroGraph supplies function to determine is a subgraph is a clique and to find all of the cliques in a graph.
subgraph is linked to every other member. As usual, the generator is used to determine whether or not a link exists between two nodes. See the description of generators for additional details.
generator to find adjacent nodes). Each clique returned will contain at least minimum-size and no more than maximum-size members .
fn to each clique in which node is a member and whose size is at least minimum-size. The generator is used to find adjacent nodes.
Prolog and Social Network Analysis
The functions described above have analogues in the Prolog world.
Graph Search
Unifies path with each path found from start to end using a breadth first search strategy.
start- the node at which to startend- the node at which to stopgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).max-depth- the maximum depth to search.path- bound to a list of UPIs representing a path fromstarttoend. Each element in the path will be a UPI U such that there is a triple whose subject is U; whose object is the next element in the list; and which is returned by a call togenerator. Iterates over paths betweenstartandendof all lengths. Warning Searching for all possible paths in a large triple-store can take a long amount of time.
Iterates over paths between start and end that are no longer than max-depth.
Unifies path with each path found from start to end using a depth first search strategy.
start- the node at which to startend- the node at which to stopgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).max-depth- the maximum depth to search.path- bound to a list of UPIs representing a path fromstarttoend. Each element in the path will be a UPI U such that there is a triple whose subject is U; whose object is the next element in the list; and which is returned by a call togenerator. Iterates over paths betweenstartandendof all lengths. Warning Searching for all possible paths in a large triple-store can take a long amount of time.
Iterates over paths between start and end that are no longer than max-depth.
Unifies path with each path found from start to end using a bidirectional search strategy (i.e., preceding from start and end simultaneously).
start- the node at which to startend- the node at which to stopgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).max-depth- the maximum depth to search.path- bound to a list of UPIs representing a path fromstarttoend. Each element in the path will be a UPI U such that there is a triple whose subject is U; whose object is the next element in the list; and which is returned by a call togenerator. Iterates over paths betweenstartandendof all lengths. Warning Searching for all possible paths in a large triple-store can take a long amount of time.
Iterates over paths between start and end that are no longer than max-depth.
Graph Measures
Unifies degree to be the nodal-degree of actor in the current triple-store (i.e., the current value of *db*).
actor- a node in the graphgenerator- the name of the generator function used to compute adjacent nodes in the graph (see the section on generators for more details).
Unifies neighbor to each vertex that has an edge pointing away from or towards actor in the graph defined by generator in the current triple-store (i.e., the current value of *db*).
actor- a node in the graphgenerator- the name of the function used to determine adjacent nodes. (See generators for more details).
The density of group is the normalized average degree of the actors in the group. Roughly, this is a measure of how many of the possible connections between actors are actually realized.
group- a list of nodes in the graph (these can be UPIs, future-parts, or strings that can be coerced into UPIs).generator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify group to the list of UPIs representing the ego group of actor in the graph.
actor- a node in the graphdepth- how many links to travel when fining the ego group.generator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
See ego-group-member to iterate over each member instead of collecting them all into a list.
Unify member with each of the other actors in actor's ego-group.
actor- a node in the graphdepth- how many links to travel when fining the ego group.generator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
See ego-group to directly collect all of the members of an actor's ego-group.
Unify clique with each of the graph cliques (i.e., completely connected sub-graphs) in graph in which actor plays a member.
actor- a node in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details). The arity three version ofcliqueiterates over all cliques that have three or more members
The arity four version of clique iterates over all cliques that have minimum-size or more members
Succeeds if group is a clique in graph (where edges between nodes are defined by generator).
group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the actor-degree-centrality of actor.
actor- a UPI in the graph (or something that can be coerced into a UPI).group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the group-degree-centrality of group.
group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the actor-closeness-centrality of actor.
actor- a UPI in the graph (or something that can be coerced into a UPI).group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the group-closeness-centrality of group.
group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the actor-betweenness-centrality of actor.
actor- a UPI in the graph (or something that can be coerced into a UPI).group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Unify centrality with the group-betweenness-centrality of group.
group- a list of items that can be coerced into UPIs in the graphgenerator- a function that specifies how to find the neighbors of an actor in the graph (see generators for more details).
Geospatial Primitives
Introduction
AllegroGraph provides a novel mechanism for efficient storage and retrieval of data elements which are coordinates in a two-dimensional region. We often refer to this as "geospatial" although that term refers more specifically to positions on or around the earth's surface. AllegroGraph supports a more-general notion of two-dimensional coordinates, both on a flat plane such as the surface of a silicon chip, a sphere such as the earth's surface, or any other two-dimensional geometry system a user can define by writing some additional Lisp code. However, we will use the term geospatial to include any such data when there is no danger of ambiguity
AllegroGraph supports a :geospatial UPI type. The geospatial UPI type supports up to 256 subtypes, some predefined and others available for the application programmer to custom design. A geospatial UPI always encodes both an X and Y ordinate inside a single UPI in a way that allows efficient searching. The subtype specifies how external numeric data (e.g. degrees, radians, meters, or nanometers) is converted to and from the geospatial UPI internal representation.
In the 3.0 release geospatial UPIs are not supported for remote triple stores. Remote stores will be supported in the next release. For using geospatial UPIs from Java, see the several examples in the learning center.
Geospatial Subtypes
It is the job of a geospatial subtype to convert coordinates in some external representation to and from UPI representation. There are helper functions for defining certain important kinds of subtypes, for example, latitude and longitude on the earth's surface, and simple X:Y coordinates over a finite range of the infinite Cartesian plane.
The precision of each ordinate in the internal UPI representation is 32-bits. Dividing the circumference of the earth by 2^32 reveals that the resolution of a 32-bit integer longitude is slightly better than 1 cm.
Suppose we want to search a triple store for geospatial UPIs that are close to a certain XY, i.e., within a bounding box [X1,Y1,X2,Y2]. In a traditional RDF store (perhaps using :latitude and :longitude types) the X and Y would be in separate triples. If the two ordinates were combined a single part, it would still only be possible to search over a range of {X1,X2}, but within that range every Y value must be retrieved and range tested. As the size of the data increases, and therefore the total number of UPIs within the X range {X1,X2} increases, this scales badly.
A geospatial UPI does combine the two ordinates into a single value, but it adds a third component to the UPI. The Y dimension (or latitude) is decimated into strips of a fixed width, and UPIs are sorted first on the strip, then on the X, and finally on the actual Y value.
How does the Y strip help? In any of the AllegroGraph indexes, UPIs in any particular one of the SPOG are sorted as 12-byte unsigned integers. Within any index, all geospatial UPIs of a given subtype will sort together, first sorted on Y strip, then on the unsigned 32-bit integer X, then finally on the unsigned 32-bit integer Y. The Y strip is a decimation of the Y value. In other words, the Y values are divided into narrow strips. UPIs (within a given subtype) are sorted first on the strip, then the X, then the Y. If we expect searches to be concerned with regions (or radii) about R in size, and if the strip width is chosen to be within an order of magnitude of the search size, it helps the search tremendously.
Suppose we have a large number of GPS latitude and longitude information of cell phone locations, and that the data points have a resolution around 10 meters. Suppose we are interested in searching over a radius of 100 meters. If we store the latitude-longitude UPIs using a strip width of 100 meters, then to find all candidates within the bounding box [X-100,Y-100,X+100,Y+100] requires scanning short regions of two strips. Each candidate within those regions can be further filtered for exact distance. The proportion of entries that must be filtered out is 1-(pi/4).
Suppose our strips are larger, 500 meters. In that case our 100 meter radius search needs scan at most only two strips, and frequently only one, but the scan overall is somewhat less efficient because number of entries that must be filtered is greater. Even if the Y region lies completely within a single strip, the proportion of undesired entries that must be filtered is approximately 1-(pi/(4*5)). If the Y region of interest spans two strips, the proportion of entries that must be examined and rejected by the filter is 10-(pi/(4*10)).
If we err in the other direction and make the strips significantly smaller than the typical search radius, the proportion of entries that must be examined and filtered is not much affected, but the number of Y strips that must be scanned over the range [X1,X2] increases, causing more cursor creation and scans of disjoint sections of the index file. For example, if the strip width were 10 meters, the 100-meter radius query would have to examine 10 or 11 strips. This requires more cursor initialization and accessing multiple separate regions of the index.
In practice, even if the strip size for a particular geospatial subtype is as much as an order of magnitude away from the Y range used in a particular search, the strip approach is tremendously more efficient than direct X-Y search even for huge databases. If it is anticipated that data will be searched using widely different ranges at different times, then the data can be duplicated in the database using multiple subtypes with different strip sizes. For example, if we sometimes wanted to find cell phones records within a 100 meter radius of a location, and other times wanted to find calls within a 10 kilometer radius of a location, then it might make sense to record the data with multiple separate triples (or perhaps use both the object and graph UPIs of a single triple) with strip widths appropriate for each of the expected types of searches.
This points out the important limitation of the geospatial UPI strip concept. It requires that the program creating the data know in advance something about how the data will be used, i.e., the typical width of regions of interest. Fortunately, this estimate does not need to be exact. Even an order of magnitude error will not make the data unusable.
Defining and Managing Geospatial Subtypes
AllegroGraph cannot anticipate all of the geospatial subtypes that future applications might find necessary. An application must define the subtypes it wants to use, and there are some helper functions to assist for obvious popular requirements such as Earth-surface latitude/longitude with any desired strip width.
A geospatial subtype needs to define a number of functions to translate to and from the internal fields of the UPI and the external data. It is important to realize that an X-Y location most-intuitively consists of two separate numerical values. Other UPI types once way or another contain only a single value -- a string for resources and string literals, and a single number for the various numeric types, including time etc. This means that the familiar functions upi->value and value->upi may not immediately be applicable. Although the application program rarely needs be concerned with the strip component, it does need communicate back and forth the two values for X and Y.
One way to work around this would be to use Common Lisp's built in complex numbers. Another way is to use Common Lisp's multiple values. The advantage of a complex is that it is a single quantity that contains two numeric values, either integer or float. This is supported, but since manipulating complex number is a a little less efficient and computationally involved, it is more usual to employ conversion functions that deal with the two values as separate numbers.
(A geospatial subtype is associated with a unique UUID. In the future there will be a facility, not yet implemented, which will search for or otherwise reconstruct a subtype from a UUID. It will also be possible to use geospatial UPIs with federation, but currently geospatial UPIs are not supported in federated stores.)
An application can control all aspects of encoding and decoding x/y data to and from geospatial UPIs but this is rarely necessary and only so for exceptional kinds of models. Simple defining macros are provided for define geospatial subtypes for a region on a flat Cartesian plane and for the surface of a sphere (as for longitude/latitude).
xmin..xmax and Y range ymin..ymax and with the strip-width specified.
latitude-strip-width-in-km is specified in degrees.
latitude-strip-width-in-miles. The range of latitudes and longitudes are given by these keyword arguments with these defaults: lat-min -90.0, lat-max +90.0, lon-min -180.0, lon-max +180.0.
latitude-strip-width-in-km is specified in kilometers.
Execution of these macros returns an opaque geospatial subtype object that implements the subtype. It is typical to save it somewhere in order to use it later. See the defparameter in the example below.
The first defines a Cartesian subtype covering the specified region of the Cartesian plane. Units of the four arguments are at the discretion of the programmer and may be any type of real numbers.
The other four macros define a spherical subtype. A subtype can be defined to use either longitude/latitude in decimal degrees or radians. For longitude/latitude, the strip width may be given in miles (relative to the earth's average radius), kilometers, or degrees in latitude.
Before using a geospatial subtype it must be defined, usually by executing one of the above operators. Before storing a triple with a part with a geospatial subtype into a triple store, it is necessary to add that subtype to the set of subtypes known to that store. This is done with the add-geospatial-subtype-to-db function.
When opening a triple store containing one or more geospatial subtypes, geospatial subtypes it uses will be recreated in the running AllegroGraph program if they are not already registered in that image.
When working in spherical coordinates it is idiomatic to speak of "latitude and longitude" and to present the latitude before the longitude, as in "37.5N127.3W". Latitude, i.e. the North/South axis, corresponds intuitively to Cartesian Y, and longitude corresponds intuitively to Cartesian X. However, in Cartesian coordinates it is typical to present X before Y, as in "the point {3,-5}". Since Cartesian and spherical coordinates mostly share a common API, we will in AllegroGraph uniformly speak of longitude/latitude and present the longitude before the latitude. The only exception will be in parsing and printing ISO6709 latitude-longitude strings, where the standard defines latitude to appear before longitude.
Internally, the several varieties of latitude-striping subtypes all represent latitude and longitude ordinates as 32-bit unsigned integers. The ranges -90..+90 and -180..+180 are scaled so that any coordinate in ISO6709 format ±DDMMSS±DDDMMSS will round-trip between internal and external string representations without change or loss of precision. Each second in latitude corresponds to 3300 units in the integer encoding, and each second in longitude corresponds to 6600 integer units, so fractional seconds that are exact submultiples will be reproducible. These rather strange numbers were chosen as being close to the maximum resolution possible within 32 bits, and having a large number of prime divisors:
3300: 2 2 3 5 5 11
6600: 2 2 2 3 5 5 11
*standard-output* the (mod 256) subtype index UUIDs of each the geospatial subtype that has been registered in the running AllegroGraph image.
subtype argument may be a geospatial-subtype object returned by one of the register functions, or the mod 256 index of the subtype in this executing AllegroGraph image. An error is signaled if the subtype is still in use (as in add-geospatial-subtype-to-db) by any open database.
Define a geospatial subtype. It returns two values: an opaque object representing the subtype and an mod 256 integer which is the subtype index within this running AllegroGraph image.
This function is usually called from higher-level geospatial subtype definers such as register-cartesian-striping and similar definers, and would only be called in applications that need to define custom geospatial subtypes not covered by those existing functions.
The additional arguments:
documentation - A documentation string.
base-uuid - uuid
2v-encoder - A function of arguments
(subtype x y &optional (upi (make-upi)))which encodes the givenxandyas a UPI. If the optional UPI argument is used, that UPI is filled in. Otherwise a fresh UPI is allocated.2v-decoder - A function that takes a UPI of this geospatial subtype and returns two values, the X and the Y (or e.g. longitude and latitude) that the UPI encodes.
x->usb32 - A function that translates a real number into an monotonic (unsigned-byte 32) integer.
usb32->x - A function that does the reverse.
y->usb32 - Ditto for y.
usb32->y - Ditto for Y.
- usb32->strip - A function that takes a real number for Y and computed the (unsigned-byte 16) strip number in which that value belongs.
AllegroGraph takes care of the mapping between the subtype index in the local AllegroGraph and the subtype index in an open triple store. In general these will not be the same.
The next three functions are not normally needed by Allegrograph applications but are included for completeness and introspection.
db. See add-geospatial-subtype-to-db. Some geospatial queries require the subtype as an argument, and since opening a database with geospatial data reconstructs any unregistered subtypes automatically, it may be more convenient when opening an existing store to obtain a subtype object this way rather than by reregistering it manually.
geospatial subtype in argument db which must be an open triple store. This information is not usually needed by application programs.
(mod 256) index of this argument geospatial-subtype in the running AllegroGraph image. Not needed in normal programming.
Converting between Geospatial Data and UPIs
subtype-index, strip and x and y coordinates.
subtype and x and y coordinates.
This creates using the given geospatial subtype a UPI with the given x and y coordinates.
x and y coordinates of a geospatial UPI as multiple values.
This returns x and y of a geospatial part as multiple values. See the example below.
Using Automatic Predicate and Type Mapping with Geospatial Data
These functions create type or predicate mappings for geospatial subtypes. subtype os a geospatial-subtype object. The predicate-part or datatype arguments are the same as could be passed to setf of datatype-mapping or predicate-mapping.
(setf predicate-mapping) but is used for spherical geospatial subtypes. Automatic mapping needs to know the intended subtype for geospatial data predicates.
(setf predicate-mapping) but is used for Cartesian geospatial subtypes. Automatic mapping needs to know the intended subtype for geospatial data predicates.
(setf datatype-mapping) but is used for spherical geospatial subtypes. Automatic mapping needs to know the intended subtype for geospatial datatypes.
(setf datatype-mapping) but is used for Cartesian geospatial subtypes. Automatic mapping needs to know the intended subtype for geospatial datatypes.
Retrieving Geospatial Triples
pred and an object UPI that is a geospatial UPI with the given subtype and within the specified Cartesian bounding box. If :use-g is true, the triple's graph slot is searched instead of the object. The units are implicit in the data.
subtype is a geospatial-subtype object such as is returned by register-cartesian-striping. pred is a UPI or future part specifying the predicate of triples to be matched. It must be supplied. x and y are the coordinates around which to search, and radius is the search radius. The units of radius are implicit in the subtype. All matching triples with an object of the specified geospatial subtype and within the search radius will be returned by the cursor. If the use-g argument is specified and is true, the graph part of triples is searched instead of the object. The other arguments are as for get-triples.
There are Prolog analogs to the functions above. The triple argument is unified to successive triples that have predicate pred and an object within the bounding box or radius.
-triple against each triple with predicate +pred with an object of geospatial subtype +subtype within the bounding box x-min x-max y-min y-max. The +subtype is the object returned by register-cartesian-striping and similar functions.
-triple against each triple with predicate +pred with an object of geospatial subtype +subtype within radius distance of coordinate x y. The +subtype is the object returned by register-cartesian-striping and similar functions.
The Haversine formula is used to compute the "Great Circle" distance on a sphere. See http://en.wikipedia.org/wiki/Haversine_formula for background. Each of these functions returns a cursor that will return all the triples with predicate pred and an object UPI that is a geospatial UPI with the given subtype and within the specified spherical radius. If :use-g is true, the graph is searched instead of the object. This is the spherical analog to the bounding box functions above.
subtype is a geospatial-subtype object such as is returned by register-latitude-striping-in-miles. pred is a UPI or future part specifying the predicate of triples to be matched. It must be supplied. lon and lat are the coordinates around which to search, and radius-in-miles is the search radius. All matching triples with an object of the specified geospatial subtype and within the search radius will be returned by the cursor. If the use-g argument is specified and is true, the graph part of triples is searched instead of the object. The other arguments are as for get-triples.
radius-in-km is given in kilometers.
radius-in-radians is given in radians. This incompletely implemented and nonfunctional in release 3.0.
These functions have Prolog analogues: the triple argument is unified to successive triples that have predicate pred and an object within the spherical radius.
-triple against each triple with predicate +pred with an object of geospatial subtype +subtype within +radius miles of +longitude and +latitude. These last three arguments are typically floating-point numbers. The +subtype is the object returned by register-latitude-striping-in-miles and similar functions.
+radius is in kilometers.
Polygon Support
There is a prototype facility for dealing with polygon regions. It can be used to determine if a pair of geospatial ordinates lies within a region defined by a polygon. The current interface is Lisp specific but will eventually also be provided by the Java client.
All computations on a polygon are performed on a Lisp data representation, a proper list of conses of X and Y ordinates which are the vertexes of the polygon. Successive vertexes define the edges with an implied edge between the last and first element. There is no requirement that a polygon be convex, or even non-self-intersecting. Polygons work with any geospatial subtype, including both Cartesian and spherical ordinates, although the predicates for the interior of a polygon compute in the Cartesian plane and do not account for spherical ordinates. This is a reasonable optimization for small regions of the sphere, except near the poles.
When a polygon must be stored in a triple store (e.g. the boundaries of a city) by convention it can be done with an ordered set of triples, one for each vertex. The Subject is any convenient identifier for the polygon, the Object is a geospatial UPI for the vertex, and the Graph is available for any other purpose. The Predicate is a nonnegative integer UPI of type +rdf-subscript+ which orders the vertexes. These can be extracted from the triple store by the polygon-vertexes function.
polygon-upi.
The polygon-subject-upi is the subject identifying the desired polygon. This function returns a fresh list of the vertexes of the polygon. A polygon could have been stored in a triple store with code like the following:
(defparameter *cartesian-10*
(register-cartesian-striping -1000 1000 -1000 1000 10))
(add-geospatial-subtype-to-db *cartesian-10*)
(defparameter *my-pentagon*
'((234.56 . 347.31)
(243.07 . 348.40)
(247.85 . 357.02)
(230.68 . 349.52)
(231.37 . 348.62)))
(defparameter *penta*
(with-temp-upi (u)
(with-temp-upi (s)
(loop with id = (new-blank-node)
for vertex-number from 1
for (x . y) in *my-pentagon*
do (add-triple id
(value->upi vertex-number :subscript)
(geospatial->upi *cartesian-10* x y u))
finally (return id)))))
penta will be set to the new blank node that names this polygon. Its vertexes can now be retrieved given it's UPI as subject.
(polygon-vertexes *penta*) =>
((234.56006 . 347.31006) (243.07007 . 348.40002)
(247.84998 . 357.02002) (230.67993 . 349.52002)
(231.37 . 348.62))
polygon is a list of vertexes such as is returned by polygon-vertexes. Returns true if the point [x,y] is inside the polygon. Boundary cases for vertexes of points on the edges are indeterminate.
This predicate returns true if the given point is inside the polygon. The polygon is a list of coordinates, as above. Points on an edge or vertex will return an indeterminate result since they are subject to float rounding.
(point-inside-polygon-p (polygon-vertexes *penta*) 235.5 350.0) => t
(point-inside-polygon-p *my-pentagon* 235.5 350.0) => t
(point-inside-polygon-p *my-pentagon* 235.5 356.0) => nil
See the polygon section in the Geospatial tutorial for more examples how polygons can be used.
inner polygon is contained entirely within the outer polygon. Boundary cases for points on vertexes or edges are indeterminate. The outer-convex-p boolean may be passed, and if true allows a more-efficient algorithm to be used.
This function tests whether the inner polygon is entirely contained by the outer polygon. Again, results are indeterminate if any vertexes of the inner polygon fall on edges or vertexes of the outer polygon, or if any edges of the two polygons are collinear. The outer-convex-p boolean may be passed, and if true allows a more-efficient algorithm to be used.
predicate and an object that is a geospatial UPI of subtype subtype within the polygon. If use-g is supplied and true, the graph is used instead. Boundary cases for vertexes of points on the edges are indeterminate. The other arguments are as for get-triples-geospatial-bounding-box
This function returns a cursor that return all triples with the specified predicate that have an Object that is a geospatial UPI of the specified subtype and which is within the given polygon. If :use-g is true, the graph is searched instead of the object.
-triple to each triple with predicate +predicate and an object part of geospatial subtype +subtype within the polygon denoted by the list polygon. Boundary cases on the vertexes and edges are not specified.
These are the Prolog analogs to get-triples-inside-polygon. They successively unify the -triple argument to each triple inside the given polygon.
Temporal Primitives
AllegroGraph encoded UPIs support efficient storage and retrieval of temporal data including datetimes, time points, and time intervals:
- datetimes in ISO8601 format: "2008-02-01T00:00:00-08:00"
- time points: !ex:point1, !ex:h-hour, !ex:when-the-meeting-began, etc
- time intervals: !ex:delay-interval (e.g., from point !ex:point1 to !ex:h-hour)
Once data has been encoded, applications can perform queries involving a broad range of temporal constraints on data in the store, including:
- relations between points and datetimes
- relations between intervals and datetimes
- relations between two points
- relations between two intervals
- relations between points and intervals
The temporal reasoning tutorial describes all of these capabilities in detail and also functions as a reference guide.
Managing AllegroGraph
AllegroGraph provides several utilities to help you manage your triple-stores and AllegroGraph itself. Most of the management operations are carried out automatically but there may be occasions when you will want to take greater control.
The following functions let you set and get properties that control AllegroGraph, find the version you are using and operate on all of the triple-stores that you have open.
Returns the value of the property associated with name. With no argument, prints all property names and values to standard output. Setfable.
> (setf (ag-property :default-print-triple-format) :ntriples)
:ntriples
> (ag-property :default-print-triple-format)
:ntriples
extended argument is true, then it also returns the build date.
Search for an open triple-store named by designator. Designator can be one of the following:
- An object of type triple-db
- A pathname which is the directory of a triple-store (cf. data-directory)
- A string which can be coerced into a pathname which is the directory of a triple-store
- A string which is the
nameof an open triple-store.
Note that it is possible that two or more triple-stores are open which have the same name. In this case find-triple-store will signal an error of type ambiguous-triple-store-designator.
In addition to several special variables that can be dynamically bound to control its behavior dynamically, AllegroGraph has the following properties:
errorp keyword argument to register-namespace. If true and errorp is not supplied, then calling register-namespace with a namespace-prefix that already has a namespace mapping will signal an error. Otherwise the namespace mapping will be changed silently.
The default value for the format keyword argument to print-triple, print-triples, and part->string. May be one of these values:
:ntriples - Print appropriate for an N-Triples syntax file, including angle brackets and other punctuation, and escaping all characters outside the permitted set with \uxxxx escapes. The permitted characters are approximately the printable 7-bit ASCII. Triples written in this format are intended to be readable without loss of information, provided encoded UPIs have appropriate type or predicate mappings in effect.
:long - Exactly like :ntriples, except that no character \uxxxx escaping is performed. This is appropriate for printing to a stream that can support and display Unicode characters.
:concise - This format is intended for human-readable presentation. Characters are not escaped, language and type tags are suppressed from literals, and numeric encoded UPIs are printed numerically. If an appropriate namespace prefix is registered, it is used, otherwise URIs are printed fully.
:terse - Similar to :concise, except that only the fragment portion of a URI is printed, and long literal strings are truncated with "..." ellipses.
The default is :ntriples.
sys:temporary-directory.
verbose in AllegroGraph functions that have a verbose keyword argument. Examples include load-ntriples, load-xml/rdf and index-all-triples.
prepare-reasoning will output information messages as it runs inferences.
Finally, AllegroGraph periodically runs a variety of background checks to help optimize your triple-stores. These are controlled by the AllegroGraph agraph-manager. You can set how often AllegroGraph runs these checks using manager-period.
AllegroGraph-Manager of the AllegroGraph application.
policy to see what management operations need to be done and then do them.
Returns true if and only if the AllegroGraph manager process is paused.
If the manager is paused, then the background process that frees unused resources will not be executed.
resume-agraph-manager).
pause-agraph-manager).
manager). The manager is started automatically when AllegroGraph opens a triple-store so Application programmers will not generally need to use this.
REPL Interface
In addition to the ! reader macro, AllegroGraph provides a handful of functions to make it easier to interact with the triple-store from the REPL.
Triples and parts are represented by (simple-array (unsigned-byte 8) 56) and (simple-array (unsigned-byte 8) 12) respectively. By default the Lisp printer prints these as vectors of bytes which is not very informative when using AllegroGraph interactively. This function modifies a pprint-dispatch table to print triples and parts interpretively if this can be done in the current environment. Specifically, the value of db must be an open triple store, and the vector being printed must print without error in the manner of print-triple or upi->value. If any of these conditions don't hold the vector is printed normally.
If the boolean argument is true, the informative printing is enabled, otherwise disabled. The :pprint-dispatch argument specifies the dispatch table to modify, by default the value of print-pprint-dispatch. Once enable-print-decoded has been turned on, you can also use the special-variable *print-decoded* to enable fine-grained control of triple and UPI printing.
:format, which defaults to the value of (ag-property :default-print-triple-format), specifies how the triple should be printed. The value :ntriples specifies that it should be printed in N-Triples syntax. The value :long indicates that the string value of the part should be used. And the value :concise causes it to use a more concise, but possibly ambiguous, human-readable format.
triple-container which can be either a triple store object, a list of triples such as is returned by get-triples-list, or a cursor such as is returned by get-triples. If the keyword argument :limit is supplied, then at most that many triples will be displayed. The :format keyword argument controls how the triples will be displayed, in either :ntriples, :long, or :concise format. It defaults to (ag-property :default-print-triple-format). The stream argument can be used to send output to the stream of your choice. If left unspecified, then output will go to standard-output.
The default value for the format keyword argument to print-triple, print-triples, and part->string. May be one of these values:
:ntriples - Print appropriate for an N-Triples syntax file, including angle brackets and other punctuation, and escaping all characters outside the permitted set with \uxxxx escapes. The permitted characters are approximately the printable 7-bit ASCII. Triples written in this format are intended to be readable without loss of information, provided encoded UPIs have appropriate type or predicate mappings in effect.
:long - Exactly like :ntriples, except that no character \uxxxx escaping is performed. This is appropriate for printing to a stream that can support and display Unicode characters.
:concise - This format is intended for human-readable presentation. Characters are not escaped, language and type tags are suppressed from literals, and numeric encoded UPIs are printed numerically. If an appropriate namespace prefix is registered, it is used, otherwise URIs are printed fully.
:terse - Similar to :concise, except that only the fragment portion of a URI is printed, and long literal strings are truncated with "..." ellipses.
The default is :ntriples.
part down to a maximum depth of maximum-depth using the format format. Triples for which part is a subject and their children will be printed. See part->string and (ag-property :default-print-triple-format) for information about part printing. See pprint-object to display information based on subjects rather than objects.
part down to a maximum depth of maximum-depth using the format format. Triples for which part is an object and their children will be printed. See part->string and (ag-property :default-print-triple-format) for information about part printing. See pprint-subject to display information based on objects rather than subjects.
From Parts and UPIs to Values
See upi->value and upi->values for additional information.
part which can be either a UPI or a future-part.
part in ;long syntax. Part can be either a UPI or a future-part.
part in N-Triples syntax. Part can be either a UPI or a future-part.
part (which can be a UPI or a future-part). The :format keyword argument controls the format and can be one of :ntriples, :long, :concise, or :terse, as with the :format argument to print-triple. The default is the value of (ag-property :default-print-triple-format).
part which can be either a UPI or a future-part.
part. Part can be UPI or a future-part.
Deprecated: use part->value instead.
Returns the value of the part which can be UPI or a future-part.
Miscellaneous Utilities
UPI hash-tables
upi in the upi-hash-table table and whether or not the value was found. setf may be used with gethash/upi to modify the value associated with a upi or to add a new association to the hash-table.
table.
fn to each UPI/value association in the upi-hash-table table. fn should be a function of two arguments. It will be called with a UPI as the first argument and the value associated with the UPI as the second.
upi and its value in the upi-hash-table table.
Other
CVS/Ontology Management
Ontology management is often done by non-programmers. It's a little much to ask non-programmers to use one of the APIs for AllegroGraph just to get data into a database. For these users, we have created a tool for reading entire ontologies, a collection of triples, into a database. This tool assumes:
- A single ontology is represented by data in a single file.
- The ontology must have a unique name.
- CVS is used to store the files containing the ontologies.
- A CVS tagging mechanism is used to indicate which versions of an ontology the tool will use.
Since ontologies must have a unique name, it is recommended users of this tool maintain a consistent naming scheme. For example, the full module and path in the module of the file containing the ontology. For example: ontology_module/groupA/ontology123.owl. Here ontology_module is the CVS module name and groupA/ontology123.owl is the file name of the ontology in the CVS module.
These tools work using tags made in CVS with the tag command. Each version of the ontology to be added to the database is tagged. For example, in a working copy of the `ontology_module' module, you could execute this command:
$ cvs tag -F jason_beta groupA/ontology123.owl
jason_beta is the name of the CVS tag and groupA/ontology123.owl is the name of the file in the module. -F means to forcibly move the tag to the current version, if the tag has been used before.
Now, we could use the update_ontology command, like so:
$ update_ontology ontology_name nasa.db jason_beta \
ontology_module/groupA/ontology123.owl
This would unload, or delete, all previous triples in nasa.db that have the ontology name ontology_name, and then load the triples from the file groupA/ontology123.owl with the version given by jason_beta in the CVS module ontology_module.
Requirements
The CVSROOT environment variable must be set.
CVS must be installed. On Windows, Cygwin CVS is recommended. See www.cygwin.com for more information.
'rapper' must be installed to convert files in formats other than N-Triples format.
The
bindirectory in the AllegroGraph installation directory should be in your PATH, otherwise full path qualification will need to be done to execute the command line tools.
update_ontology command line arguments
$ update_ontology [-v] ontology_name database cvs_tag module_path
where
-vallows for verbose operation, mostly for debuggingontology_nameis the name of the (e.g., ontology3)databaseis the name of the database in which the triples are updatedcvs_tagis the CVS tag (e.g., User1_beta) which specifies the the desired new version of the ontologiesmodule_pathis the name of the file in the CVS repository that contains the updated ontology. For example, if the module name isontologyand the file isontology3, then the module_path would beontology/ontology3.
The update_ontology command will retrieve from CVS the exact version of the ontologies specified by the tag User1_beta and executes ths sync_ontology command:
$ sync_ontology ontology3 module:ontology3:User1_beta database
where
module:ontology3:User1_betais shorthand for: the fileontology3in modulemodulewith version given byUser1_beta
sync_ontology command line arguments
update_ontology uses a lower-level command line tool, sync_ontology. The arguments to it are:
$ sync_ontology [--src format] ontology_name file ag_database
where
--srcis used to convert the file fromformatto n-triples format. Currently,formatmust be one of the format arguments accepted by rapper 1.4.15, which are: rdfxml, turtle, or rss-tag-soup. NOTE: a file extension of.owlautomatically implies aformatofrdfxml.ontology_nameis the name of the ontology, and is used as the named graph for all triples added to the databasefilecontains the triples to be added to the databaseag_databaseis the name of the database to which the triples are added
Other uses (mainly for testing):
$ sync_ontology -p [-n limit | -n none]
[-f { concise | long | ntriple } ]
database [ontology_name]
where
-psignals "print mode", used to print a database-n limitis use to set the :limit argument to get-triples-list, and a value ofnone' is the same asnil'-f conciseor-f longare used as the:formatargument toprint-triples
To delete triples:
$ sync_ontology -d database ontology_name
where -d is used to delete triples for an ontology
To initialize a database:
$ sync_ontology -Z [-r expected-unique-resources] database
where
-Zis used to initialize a database-r expected-unique-resourcesis use to set the create-triple-store argument of the same name
Indices
All of the functions and variables in AllegroGraph's public interface are indexed below.
Function and Macro index
- actor-betweenness-centrality
- actor-closeness-centrality
- actor-degree-centrality
- add-geospatial-subtype-to-db
- add-index
- add-indexing-host
- add-indices
- add-standard-indices
- add-triple
- ag-property
- ag-property-names
- ag-server-db
- ag-server-trace
- agraph-application
- agraph-manager
- all-bidirectional-search-paths
- all-breadth-first-search-paths
- all-depth-first-search-paths
- allegrograph-version
- apply-rdfs++-reasoner
- average-index-fragment-count
- bidirectional-search
- blank-node-p
- breadth-first-search
- clear-namespaces
- clear-type-mappings
- cliquep
- cliques
- close-all-triple-stores
- close-triple-store
- collect-all-type-mappings
- collect-cursor
- collect-namespaces
- collect-open-triple-stores
- copy-triple
- copy-upi
- count-cursor
- count-query
- create-triple-store
- cursor-next
- cursor-next-p
- cursor-next-row
- cursor-row
- data-directory
- datatype-mapping
- db-apply-reasoner
- db-name
- db-room
- db-room-list
- default-graph-upi
- defsna-generator
- delete-triple
- delete-triple-store
- delete-triples
- deleted-triple-p
- depth-first-search
- display-namespaces
- drop-geospatial-subtype
- drop-index
- drop-indices
- dump-namespaces
- ego-group
- enable-lisp-in-client-select-queries
- enable-print-decoded
- encapsulate-triple-store
- estimate-required-space
- estimated-count-query
- export-to-sesame
- federate-triple-stores
- find-cluster-code
- find-sna-generator
- find-task
- find-triple-store
- freetext-get-ids
- freetext-get-triples
- freetext-get-triples-list
- freetext-get-unique-subjects
- freetext-predicate-p
- freetext-registered-predicates
- future-part-extra
- future-part-type
- future-part-value
- future-part=
- geo-parts->upi
- geospatial->upi
- geospatial-subtype-index-in-db
- geospatial-subtype-index-in-this-image
- geospatial-subtypes-in-db
- get-triple
- get-triple-by-id
- get-triples
- get-triples-geospatial-bounding-box
- get-triples-geospatial-radius
- get-triples-haversine-km
- get-triples-haversine-miles
- get-triples-haversine-radians
- get-triples-inside-polygon
- get-triples-list
- get-variable-list
- gethash/upi
- graph
- graph-density
- graph-part=
- graph-upi=
- group-betweenness-centrality
- group-closeness-centrality
- group-degree-centrality
- hash-table-count/upi
- hashed-upi-p
- index-all-triples
- index-coverage-percent
- index-fragment-count
- index-new-triples
- index-status-report
- indexing-needed-p
- indexing-status
- inferred-triple-p
- inner-triple-store
- intern-literal
- intern-resource
- intern-typed-literal
- iterate-cursor
- literal
- load-ntriples
- load-ntriples-from-string
- load-properties
- load-rdf-manifest
- load-rdf/xml
- load-rdf/xml-from-string
- load-trix
- load-trix-from-string
- longitude-latitude->upi
- lookup-namespace
- machines
- make-future-part
- make-sesame-server
- make-triple
- make-tutorial-store
- make-upi
- make-upi-hash-table
- manage-agraph
- manage-triple-store
- manager-paused-p
- manager-period
- map-all-type-mappings
- map-bidirectional-search-paths
- map-bidirectional-search-paths-bipartite
- map-breadth-first-search-paths
- map-breadth-first-search-paths-bipartite
- map-cliques
- map-cursor
- map-depth-first-search-paths
- map-depth-first-search-paths-bipartite
- map-namespaces
- map-open-triple-stores
- maphash/upi
- merge-new-triples
- new-blank-node
- nodal-degree
- nodal-neighbors
- object
- object-part=
- object-upi=
- open-triple-store
- parse-sparql
- part->concise
- part->long
- part->ntriples
- part->string
- part->terse
- part->value
- part-value
- part=
- pause-agraph-manager
- point-inside-polygon-p
- polygon-inside-polygon-p
- polygon-vertexes
- pprint-object
- pprint-subject
- predicate
- predicate-mapping
- predicate-part=
- predicate-upi=
- prepare-reasoning
- print-triple
- print-triples
- print-type-mappings
- reasoner
- register-cartesian-striping
- register-freetext-predicate
- register-geospatial-subtype
- register-latitude-striping-in-degrees
- register-latitude-striping-in-km
- register-latitude-striping-in-miles
- register-latitude-striping-in-radians
- register-namespace
- register-sna-generator
- register-standard-namespaces
- remhash/upi
- remove-all-machines
- remove-machine
- report-loaded-geospatial-subtypes
- reset-properties
- resource
- resume-agraph-manager
- run-sparql
- run-sparql-ask
- run-sparql-construct
- run-sparql-describe
- run-sparql-select
- save-properties
- select
- select-distinct
- select-distinct/callback
- select/callback
- select0
- select0-distinct
- select0-distinct/callback
- select0/callback
- serialize-rdf-manifest
- serialize-rdf-n3
- serialize-rdf/xml
- serialize-trix
- sesame-server-port
- set-cartesian-datatype-mapping
- set-cartesian-predicate-mapping
- set-spherical-datatype-mapping
- set-spherical-predicate-mapping
- start-ag-server
- start-agraph-manager
- start-all-remote-clients
- start-remote-clients
- start-sesame-server
- stop-ag-server
- stop-agraph-manager
- stop-sesame-server
- string+
- subject
- subject-part=
- subject-upi=
- supported-types
- sync-triple-store
- triple-contents=
- triple-count
- triple-exists-p
- triple-id
- triple-store-exists-p
- triple-store-id
- triple-store-indices
- triple=
- type-code->type-name
- type-name->type-code
- undelete-triple
- undelete-triples
- unindexed-triple-count-threshold
- unmerged-chunk-count-threshold
- unschedule-indexing
- upi
- upi->geospatial
- upi->longitude-latitude
- upi->value
- upi->values
- upi-type-code
- upi-typep
- upi<
- upi=
- upip
- value->upi
- with-blank-nodes
- with-temp-triple
- with-temp-upi
- with-triple-store
Functor index
- actor-betweenness-centrality
- actor-closeness-centrality
- actor-degree-centrality
- bidirectional-search-paths
- breadth-first-search-paths
- clique
- cliquep
- depth-first-search-paths
- ego-group
- ego-group-member
- graph
- graph-density
- group-betweenness-centrality
- group-closeness-centrality
- group-degree-centrality
- nodal-degree
- nodal-neighbors
- object
- part=
- predicate
- q
- q-
- qs
- subject
- triple-id
- triple-inside-bounding-box
- triple-inside-bounding-box-g
- triple-inside-haversine-km
- triple-inside-haversine-km-g
- triple-inside-haversine-miles
- triple-inside-haversine-miles-g
- triple-inside-haversine-radians
- triple-inside-haversine-radians-g
- triple-inside-polygon
- triple-inside-polygon-g
- triple-inside-radius
- triple-inside-radius-g
- upi=
Variable index
-
For information on the N-Triples format, see both the W3C description and the information in the RDF test cases. Additionally the file w3c-ntriples-tests.nt in the
sample-inputsdirectory of the AllegroGraph distribution contains a set of test cases and provides a good overview of what can be represented. ↩ - Details of the RDF/XML syntax can be found in the RDF/XML-primer and related documentation. ↩
- Language tags are defined in RFC-3066 ↩
-
The function
do-cursorhas been removed from AllegroGraph as of version 3.0. Please use the function map-cursor and the macro iterate-cursor instead. ↩ - The Prolog q- functor provides an interface to range queries for only the object and graph slots of a triple. ↩
- It is possible to use range queries with UPIs of type :short-literal since these are stored directly in the UPI and not in the string dictionary. The only caveat is that you must make sure that all of your data really does fit into a short literal UPI. This is equivalent to saying that all of your strings must be less than or equal to 10 bytes in length after they have been UTF-8 encoded. ↩
- To be precise, AllegroGraph uses the :standard-indices property to determine which indices newly created triple-stores should have. The default value for this property is to use all possible indices. ↩
- This facility will become more flexible in future versions. ↩
- Currently, data-type and predicate mappings are available only in the N-Triples parser; we will support our other parsers in future versions of AllegroGraph. ↩
- The Oracle and Sesame connections will be implemented during the second and third quarters of 2008. ↩
-
Remember that
selectis a macro and that using it in the REPL will produce interpreted code. This means that selects run in the REPL will be significantly slower than those that you write inside of compiled functions. (Note also that both the HTTP and the Java interfaces to AllegroGraph ensure that any select calls get compiled before they run). Whether compiled queries execute significantly faster depends on whether the generated code performs a lot of backtracking or other repeated computation. ↩
