








- AllegroGraph
- Gruff
- AGWebView
- Amazon AWS
- Consulting
- Support
AllegroGraph
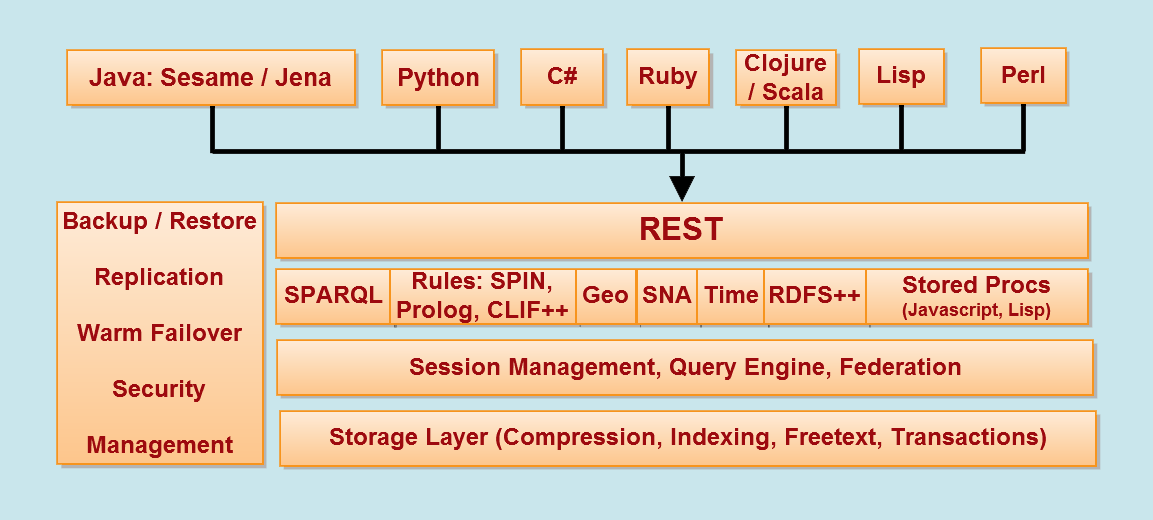
AllegroGraph® is a modern, high-performance, persistent graph database. AllegroGraph uses efficient memory utilization in combination with disk-based storage, enabling it to scale to billions of quads while maintaining superior performance. AllegroGraph supports SPARQL, RDFS++, and Prolog reasoning from numerous client applications.
AllegroGraph New Features
- Triple Attributes Enhancements. The Triple attributes facility, allows each triple to have associated attributes. These can be used for various purposes, such as access control.
- New AGTOOL - Updated and Optimize command-line utility combines most individual command-line programs into one.
- archive -- see Backup and Restore
- materialize -- see Materializer
- query -- see Querying
- export -- see Data Export
- load -- see Data Loading
- recover -- see Point-in-Time Recovery
- replicate -- see Replication
- upgrade -- see the agtool upgrade program in the Database Upgrading document.
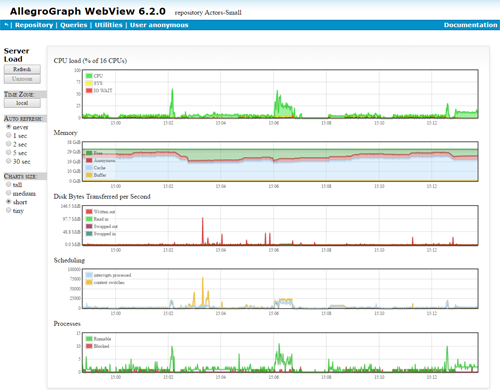
- New Server Performance Charts added to AGWebView. Click on the image below to enlarge the screenshot.
- Certification on Cloudera Enterprise
- Support for loading files from Hadoop Distributed File System; see Loading files from HDFS filesystems in Data Loading. Loading from HDFS file systems has been tested with the Cloudera Hadoop distribution.
- AllegroGraph Federation improvements - Improved and optimized communication between the main server and leaf nodes improves overall performance 2x for most users, and some operations by up to 50x. Federation is discussed in the AllegroGraph Introduction.
- Query Engine Optimizations:
- Improved SPARQL Processing Efficiency
- Improved Support for SPARQL Endpoints
- Improved Support for SPARQL Magic Properties
- More efficient use of temporary disk space
- Improved handling of very large result sets
- Storage Layer Operations:
- Reduced I/O of some data types
- Improved handling when out of disk space conditions exist
- Improved Auditing (see Auditing)
- Improved Online Backup and Restore (see Backup and Restore)
- Improved operations with freetext indices (see Full-text Indices)
- Python3 Client
- Updated Sesame (2.7.11) and Jena (2.11.1), both clients that support Java 1.6.
Additional New Features
- New 3D and multi-dimensional geospatial functionality (see N-dimensional Geospatial)
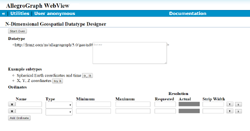
- Update to new Sesame 2.7.x transactional semantics (see Javadocs (Sesame and Jena))
- Update to new Apache Jena v2.6.x (see Javadocs (Sesame and Jena))
- WebView query page improvements: display of execution time and abort options (see WebView)
- SPARQL v1.1 support for Geospatial, Temporal, and Social Network Analytics
- The server supports new optional specific transaction "begin"
- Improved support for encrypted client connections
- Query Engine Improvements
- Support for TopBraid Composer 4.5. See Top Braid Composer Plugin
-
SPARQL Query Engine Enhancements
- Improved Query Optimizer
- SPARQL Performance Improvements
- Improved Query Memory Management
- Parallel Data Export
- Enhanced SPARQL "Magic Properties" or "Property Functions"
- Javascript API Updates
- Materialized Reasoner Improvements
- Query Plan Analyzer Improvements
- Enhanced Integration with MongoDB - Presentation: MongoDB meets the Semantic Web, and a recent Webcast on MongoGraph
- SOLR Interface for free text indexes, integrated with the SPARQL 1.1 query engine. View the webcast: Making Solr Search Smarter using RDF
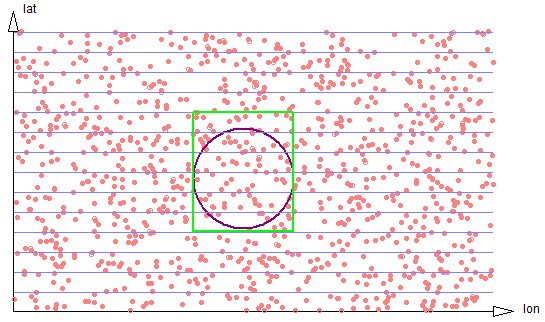
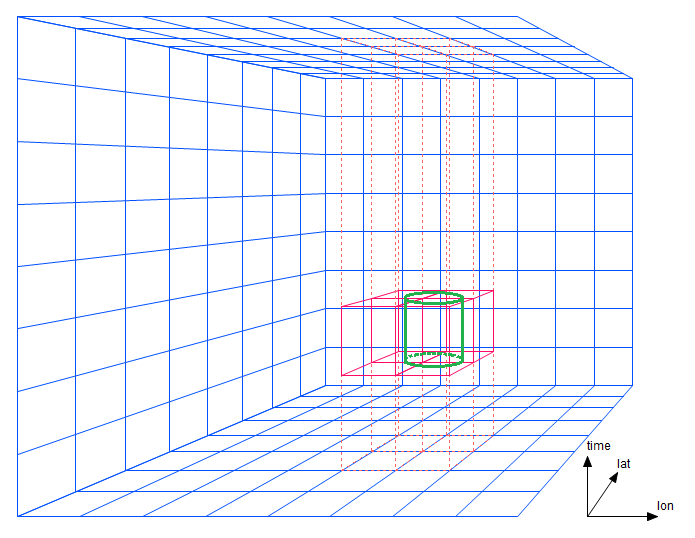
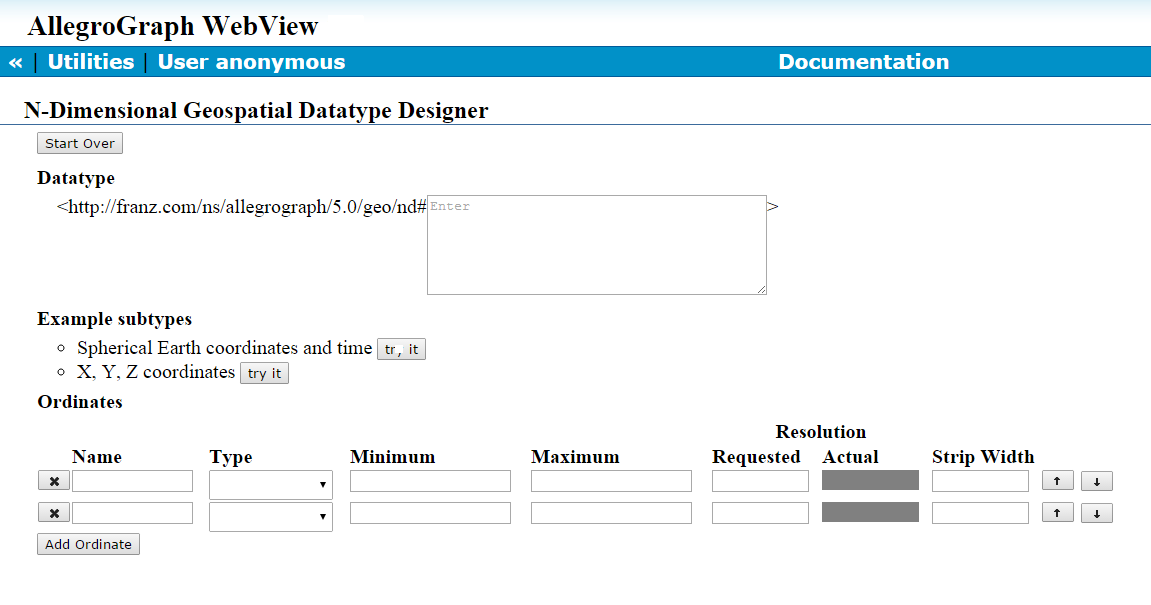
The primary emphasis of this release has been additional enterprise functionality, efficiency and overall scalability. Please refer to the release notes for a complete list of enhancements and improvements.
-
TopBraid Composer
TopBraid Composer, developed by TopQuadrant, Inc., is an enterprise-class modeling and application development environment It provides comprehensive support for modeling ontologies and data, connecting data sources, designing queries, rules and semantic data processing chains, and developing Semantic Web applications. For details see TopBraid Composer
-
RacerPro
The Semantic Web reasoning system developed by Racer Systems GmbH, RacerPro, has been integrated with AllegroGraph, exposing RDF data in AllegroGraph to Racer's highly optimized Description Logic (DL) reasoner. It is most suitable for ontology-driven applications or theorem proofing. RacerPro's interfaces also include DIG over HTTP and support for rules (SWRL). For details see RacerPro
-
AGWebview
AGWebview, developed by Franz, Inc., is an interface for exploring, querying, and managing AllegroGraph triple stores through a web browser. For details see AGWebview
-
Gruff
Gruff is an RDF browser that displays visual graphs and has an interface to build SPARQL or Prolog queries as visual graphs. Gruff can also display tables of all properties of selected resources or generate tables with SPARQL queries, and resources in the tables can be added to the visual graph. For details see Gruff
-
DATAmaestro
Data mining has increasingly played a key role in the enterprise decision process because of today's competitive necessity to respond to changing market conditions quickly and correctly, leveraging the enormous operating data now available for such process. DATAmaestro, developed by PEPITe S.A. brings unique capabilities to meet today's data mining needs. For details see DATAmaestro
-
Cogito
The COGITO platform by Expert System S.p.A., conceived to bring intelligence to the search, extraction and classification of unstructured information for internal management purposes and for monitoring and analyzing external sources, such as the Internet. For details see Cogito
-
Sentient Suite
The Sentient Suite, developed by IO Informatics Inc., integrates heterogeneous data to solve knowledge and project management problems for the Life Sciences industry. For details see Sentient Suite
-
Talend Open Studio
Talend Open Studio is an open source, Eclipse-based environment offering the broadest connectivity to all source and target systems to support all types of data integration, data migration and data synchronization operations. For details see Talend
-
Semaphore
Semaphore is an Enterprise Content Intelligence Platform built from four core and inter-connected modules: an Ontology Manager, Classification and Text Mining, a Semantic Enhancement Server, and a Search Application Framework. Semaphore:
- Automatically, accurately and consistently applies metadata and classification
- Improves findability by being ontology-driven
- Provides a better search and navigation experience
- Enables effective data disposition, data loss prevention, records retention and eDiscovery
For more info, send email to [email protected] or call (510) 452-2000, Option 3-Sales and Marketing.
| Copyright © Franz Inc., All Rights Reserved | Privacy Statement | 
|

|

|

|
|