








AllegroGraph News
December, 2012
In this issue
- Free Webcast: A Semantic Platform for Tracking Entities in Real Time As presented at Semtech SF, NY, and London - 10:00 AM Pacific, Wednesday, December 12
- AllegroGraph 4.9 - Now Available
- New - TopBraid Composer v4 - Now Supported
- New Webview Query Screen and Graph View (Beta)
- New Gruff release, version 4.0.17
- Recorded Webcast: Big Data, Fast Data, and Complex Data - Defining and Overcoming Challenges - From October 3rd
- YouTube - The AllegroGraph Channel
- Brief Highlights
Free Webcast: A Semantic Platform for Tracking Entities in Real Time - 10:00 AM Pacific, Wednesday, December 12th

As Presented at Semtech SF, NY, and London 2012.
Join us - Wednesday, December 12th at 10AM Pacific.
Having engaged several Fortune 500 companies with projects to develop Semantic Technology solutions we have identified several consistent requirements that have become the foundation for successful deployments of Semantic Technologies.
The overarching pattern that we see in these companies can best be described as real time entity tracking in order to perform real time business analytics. Typical entities are students, telephone customers, credit cards or insurance policies.
We identified and built out four components as the basis of our Semantic Technology Projects. Component one is an ETL system that takes data from various input streams and transforms the data into events, encoded as RDF triples, that go into a publish subscribe queue. To facilitate this we created a number of plugins for the open source ETL tool Talend to provide an R2RML mapping from data into triples. The second component is a forward chaining/backward chaining rule system that takes events out of the queue and combines it with the already existing knowledge about a particular entity and generates new knowledge. For some applications we see more than 10,000 triples per entity. Rules need to be able to deal with a new event in a fraction of a second. The third component is a machine learning component that is trained to generate predictions based on the features of a particular entity (for example: what is the customer going to call about when calling the call center). These predictions are again coded as individual triples. Finally, the fourth component is a reporting system that allows us to do real time analysis over all existing entities.
Register to attend this webinar here.
AllegroGraph 4.9 - Now Available
![]()
New features include:
- OWL 2 RL Materializer - Generates triples by applying a set of rules to the current triples in the triple store and then places the resulting triples back in the triple store. For example, RDF-inferred triples can be generated before runtime rather than at runtime.
- New Webview Query Screen and Graph View (Beta) - In WebView next to the Documentation menu is a link to "WebView Beta" a new UI for Query and Graph. All existing features of WebView Query are implemented.
- Improved Memory Management Functionality
- SPARQL 1.1 Query Improvements
- Support for Sesame 2.6.8 for the Java client.
- MongoDB Integration - Presentation: MongoDB meets the Semantic Web, and a recent Webcast on MongoGraph
- SOLR Interface for free text indexes, integrated with the SPARQL 1.1 query engine. View the webcast: Making Solr Search Smarter using RDF
- SPIN support (SPARQL Inferencing Notation). The SPIN API allows you to define a function in terms of a SPARQL query and then call that function in other SPARQL queries. These SPIN functions can appear in FILTERs and can also be used to compute values in assignment and select expressions.
See the full list of new features and improvements here.
New - TopBraid Composer v4 - Now Supported

Top-Braid Composer (TBC) is a graphical development environment for modeling data, connecting data sources, and designing queries, rules and semantic data processing chains.
The AllegroGraph TopBraid Composer Plugin lets the TBC user connect to an AllegroGraph server; load data into an AllegroGraph triple store; and execute SPARQL queries against the triple store. If the user has the proper AllegroGraph privileges, it is also possible to issue Prolog queries and to use RDFS++ inference.
For additional information, see the documentation here.
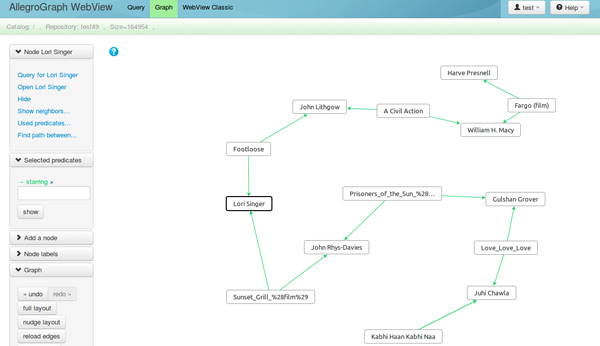
New Webview Query Screen and Graph View (Beta)
From the Repository Overview page, click the New link in the Queries menu. This exposes a page where you can edit a SPARQL or Prolog query to run against this repository.
- Query language - This page accepts SPARQL queries from all users. Users with permission to execute arbitrary code will be offered the option to use a Prolog query instead.
- Show my namespaces - Click this link to view the table of namespaces that are available to the current query. This could be a mix of shared and private namespaces.
- Add a namespace - This like lets you enter a new, private namespace to use in this query.
- Bulk Input - When you click the "Add a namespace" link, one of your options is a "Bulk Input" button. Click this button to open an edit field where you can paste in many namespaces in one operation. Use one namespace per line, in a format like "ex http://example.com/" or "ex: http://example.com/". (Note that bulk is used by two utilities in different ways. In data loading (see Data Loading), bulk means loading data without transaction logging. In Sesame and Jena and also here it mean processing several statements at once but is not related to transaction logging or loading.)
- Query Edit Field - This is the unlabeled field where you type in the text of your query. Note that you can adjust the size of the field by using the mouse to "grab" the handle at the lower right corner of the field.
- Link to query - Click this link to generate a URL that invokes this query on this repository. You can publish this URL or embed it in software. Copy the URL from the browser's address field. Note that this URL requires anonymous access. If there is no anonymous account, AGWebView will require the user to log in.
- Execute - The Execute button runs the query. A table of results will appear in the lower half of the page.
- Save As - You can save a private copy of a query for later reuse. Give it a name and then click the Save button. To find this query again, click the saved link in the Queries menu in the page banner. (This feature is available to superusers, normal users, and self-registered users, but not to anonymous users.)
- Add to Repository - You can also "save" a query by adding it to the Repository Overview page as a link to a "Pre-defined Query." To do this, give the query a name and click the "Add to Repository" button. (Superusers can add a query to the Repository Overview page. All users, including anonymous, can then use it.)
- Edit Initfile - This feature is available only to superusers. The "edit initfile" link opens a large edit field containing the text of the AllegroGraph server's initialization file, which is /data/settings/initfile. This code is run by AllegroGraph server each time a new session is opened. It lets you load Prolog functor definitions to use with your Prolog queries.
- Result - This is a table of search results. Each URI in the table is a link to a page of information about how that URI is used in the triple store.
- Download as - If your query produced triples as output (such as a SPARQL "construct" or "describe" query does), then this feature lets you save the results in one of four formats: N-Triples, N-Quads, RDF/XML, or TriX. If the results are just a list of variable values, like a SPARQL "select" query creates, you can choose between the SPARQL XML Result format and a comma-separate list of values.
- Display Geospatial Data on a Map - If the search results contain AllegroGraph geospatial coordinates, and if you have provided AGWebView with a Google Maps key, then AGWebView will offer to display the query results as a map. See the section about Google Maps.
- View Results as Graph - When you execute a SPARQL "construct" or "describe" query, the result is a set of actual triples that can be displayed as a graph. Click this link to display the graph. In the graph, blue nodes are resources and green ones are literal values. Hover the mouse over a node to see a description of the node. (This description appears as text on the line above the graph, not directly above the node.) Similarly, the arrowheads on the lines between nodes reveal the name of a predicate. You can drag the nodes around on the screen and watch the graph adjust to a new equilibrium.
For additional conference information, see here.
New Gruff release, version 4.0.17

New Features include:
- Anonymous access now works from Gruff.
- Federation is now done on the server for general efficiency and to allow queries.
- New tooltip information can be displayed in the outline view.
- Custom predicates can be used for tooltip text.
- Truncated nodes can be expanded on the fly in the graph view.
- Creating the table of query results is faster.
For additional information on the new release, see here.
Recorded Webcast: Big Data, Fast Data, and Complex Data - Defining and Overcoming Challenges - From October 3rd
As Presented at NoSQL Now! 2012.
Every day we speak with software engineers trying to find a productive approach for application development that requires a combination of BigData, Fast Data, and Complex Data solutions. In this presentation we will first describe when to use BigData solutions like Hadoop and Cassandra, then we will cover concepts around Fast Data solutions like in-memory graph databases, and finally we discuss use cases for Complex Data that thrive with Semantic Technologies.
The second part of this talk discusses a combined platform architecture for real time semantic entity tracking that needs the scale of Hadoop but also the speed of in-memory databases and the complexity of semantic technologies. We will discuss best practices for managing scalability solutions, ETL pipeline strategies, and complex event processing (CEP).
Watch this recorded webinar here.
YouTube - The AllegroGraph Channel
![]()
Videos covering AllegroGraph and related technologies.
Visit AllegroGraph's Channel here.
Brief Highlights
![]()
Semantic Case Study: Pfizer Moves Semantic Tech Forward, Helping Business Respond To Cost Pressures And Realize Efficiency Gains
A couple of years back, The Semantic Web Blog visited with Vijay Bulusu to gain some insight into how pharma giant Pfizer Inc. was moving forward with semantic technology. At the recent Semantic Technology and Business Conference in New York City, Bulusu, director, informatics and innovation at Pfizer, provided additional perspective on the issue - Read the full article here.

Semantic Case Study: EPIM ReportingHub.
The E&P Information Management Association (EPIM) launched EPIM ReportingHub (ERH), an interesting semantic technology project in the field of oil and gas. Read the full case study here.![]() Tactical Semantics: Extracting Situational Knowledge from Voice
Transcripts using Ontology-Driven Text Analysis. Dr. Kent D. Bimson,
Vice President, Research, Modus Operandi, Inc.
View the details here.
Tactical Semantics: Extracting Situational Knowledge from Voice
Transcripts using Ontology-Driven Text Analysis. Dr. Kent D. Bimson,
Vice President, Research, Modus Operandi, Inc.
View the details here.
![]() Building a Personalized
eCommerce Agent: Introducing the Thrive.AI app. Marc C. Hadfield, CTO,
Vital AI.
View the details here.
Building a Personalized
eCommerce Agent: Introducing the Thrive.AI app. Marc C. Hadfield, CTO,
Vital AI.
View the details here.
![]() Practical Lessons in
Developing an Enterprise-Wide Semantic Application. Craig Hanson,
Director, New Products, Vision and architecture, Amdocs. View the
details here.
Practical Lessons in
Developing an Enterprise-Wide Semantic Application. Craig Hanson,
Director, New Products, Vision and architecture, Amdocs. View the
details here.
![]() Intel - Big Memory, Big Data, and the
Semantic Web. "Techniques like MapReduce and NoSQL products based on
them are fine for some problems," said Mitch Shults, Mission-Critical
Segment Strategist, Intel Data Center Group. "To achieve high
performance against meaningful amounts of triplestore data, however,
you just can't afford to be traipsing all over the network to pull
things together. This result demonstrates the incredible value that
affordable large-scale, big-memory server platforms built around the
Intel Xeon E7 server platform can deliver for next-generation
workloads like triple stores." For additional information, see here.
Intel - Big Memory, Big Data, and the
Semantic Web. "Techniques like MapReduce and NoSQL products based on
them are fine for some problems," said Mitch Shults, Mission-Critical
Segment Strategist, Intel Data Center Group. "To achieve high
performance against meaningful amounts of triplestore data, however,
you just can't afford to be traipsing all over the network to pull
things together. This result demonstrates the incredible value that
affordable large-scale, big-memory server platforms built around the
Intel Xeon E7 server platform can deliver for next-generation
workloads like triple stores." For additional information, see here.

Semanticweb.com: What One Trillion Means for the Semantic Web. Mitchell Shults commented on the significance of Franz's recent success loading one trillion triplestores. Shults writes, Triplestores are perfect for making sense out of extremely complex data. However, a triplestore is only useful if massive quantities of information can be loaded, updated and effectively queried in a reasonable amount of time. That is why Franz's Technology announcement is so interesting. Read the rest of the article here.
Amdocs - "Semantics - the B2C Game Changer" (Video):
Bill Guinn, CTO Product Enablers, Amdocs Product Business Unit,
delivered a keynote at the 2011 Semantic Technology Conference in San
Francisco. His talk was one of the highlights for anyone interested in
how Semantic Technology can be used in enterprise systems. Watch the
video here.
![]() KRSTE.my (Knowledge Resource for Science and
Technology Excellence, Malaysia) is an initiative, based on
AllegroGraph, by MOSTI and spearheaded by MASTIC to address science
and technology issues and challenges faced by the community, the
ministry and the country. KRSTE.my is designed to be a Single Point
Access Facilities (SPAF) providing intelligent collaborative knowledge
management and learning services platform on Science and Technology
and Innovation. More info
here.
KRSTE.my (Knowledge Resource for Science and
Technology Excellence, Malaysia) is an initiative, based on
AllegroGraph, by MOSTI and spearheaded by MASTIC to address science
and technology issues and challenges faced by the community, the
ministry and the country. KRSTE.my is designed to be a Single Point
Access Facilities (SPAF) providing intelligent collaborative knowledge
management and learning services platform on Science and Technology
and Innovation. More info
here.
Recorded past Semantic Technologies Webinars: Recorded Webinars
Please add me to your newsletter mailing list. We
promise never to sell or divulge your email address to anyone. We will
only occasionally send you information relevant to our products (about
once a month).
Click here to unsubscribe. Send the email message that opens.
| Copyright © 2023 Franz Inc., All Rights Reserved | Privacy Statement | 
|

|

|

|
|